 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse Language Modeling towards Robust and Grounded LLMs
Oct 02, 2025The current landscape of defensive mechanisms for LLMs is fragmented and underdeveloped, unlike prior work on classifiers. To further promote adversarial robustness in LLMs, we propose Inverse Language Modeling (ILM), a unified framework that simultaneously 1) improves the robustness of LLMs to input perturbations, and, at the same time, 2) enables native grounding by inverting model outputs to identify potentially toxic or unsafe input triggers. ILM transforms LLMs from static generators into analyzable and robust systems, potentially helping RED teaming. ILM can lay the foundation for next-generation LLMs that are not only robust and grounded but also fundamentally more controllable and trustworthy. The code is publicly available at github.com/davegabe/pag-llm.
Implicit Inversion turns CLIP into a Decoder
May 29, 2025CLIP is a discriminative model trained to align images and text in a shared embedding space. Due to its multimodal structure, it serves as the backbone of many generative pipelines, where a decoder is trained to map from the shared space back to images. In this work, we show that image synthesis is nevertheless possible using CLIP alone -- without any decoder, training, or fine-tuning. Our approach optimizes a frequency-aware implicit neural representation that encourages coarse-to-fine generation by stratifying frequencies across network layers. To stabilize this inverse mapping, we introduce adversarially robust initialization, a lightweight Orthogonal Procrustes projection to align local text and image embeddings, and a blending loss that anchors outputs to natural image statistics. Without altering CLIP's weights, this framework unlocks capabilities such as text-to-image generation, style transfer, and image reconstruction. These findings suggest that discriminative models may hold untapped generative potential, hidden in plain sight.
Understanding Adversarial Training with Energy-based Models
May 28, 2025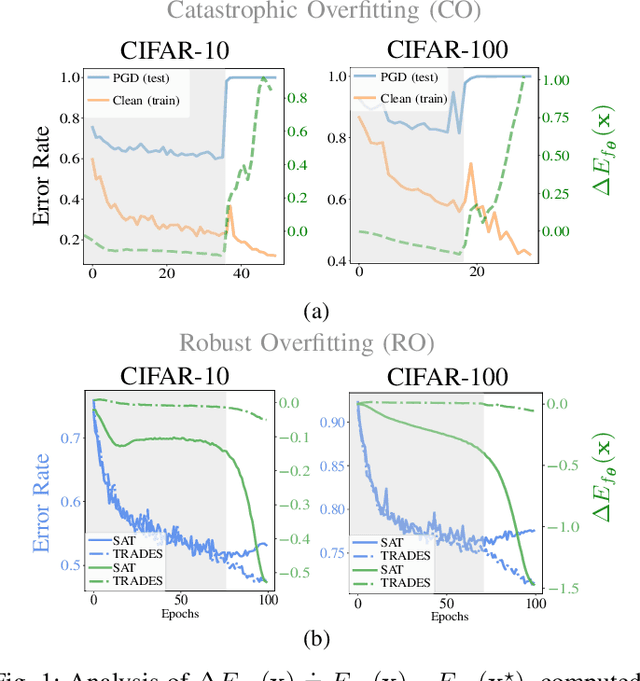
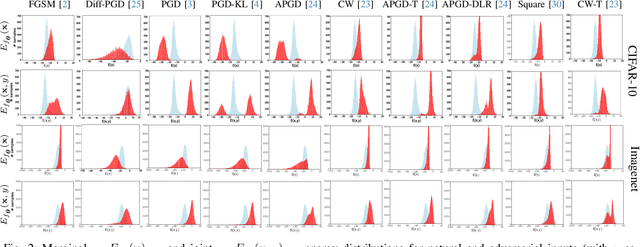
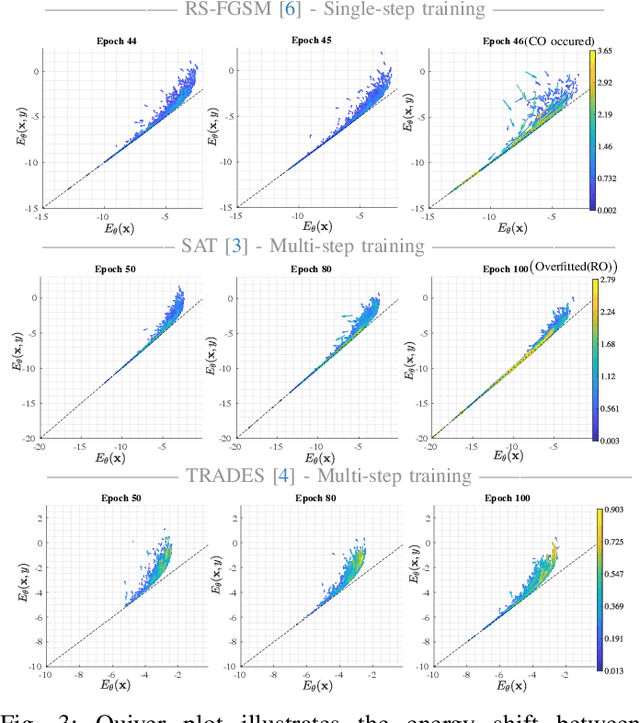
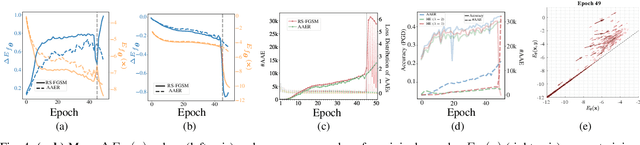
We aim at using Energy-based Model (EBM) framework to better understand adversarial training (AT) in classifiers, and additionally to analyze the intrinsic generative capabilities of robust classifiers. By viewing standard classifiers through an energy lens, we begin by analyzing how the energies of adversarial examples, generated by various attacks, differ from those of the natural samples. The central focus of our work is to understand the critical phenomena of Catastrophic Overfitting (CO) and Robust Overfitting (RO) in AT from an energy perspective. We analyze the impact of existing AT approaches on the energy of samples during training and observe that the behavior of the ``delta energy' -- change in energy between original sample and its adversarial counterpart -- diverges significantly when CO or RO occurs. After a thorough analysis of these energy dynamics and their relationship with overfitting, we propose a novel regularizer, the Delta Energy Regularizer (DER), designed to smoothen the energy landscape during training. We demonstrate that DER is effective in mitigating both CO and RO across multiple benchmarks. We further show that robust classifiers, when being used as generative models, have limits in handling trade-off between image quality and variability. We propose an improved technique based on a local class-wise principal component analysis (PCA) and energy-based guidance for better class-specific initialization and adaptive stopping, enhancing sample diversity and generation quality. Considering that we do not explicitly train for generative modeling, we achieve a competitive Inception Score (IS) and Fr\'echet inception distance (FID) compared to hybrid discriminative-generative models.
What is Adversarial Training for Diffusion Models?
May 27, 2025We answer the question in the title, showing that adversarial training (AT) for diffusion models (DMs) fundamentally differs from classifiers: while AT in classifiers enforces output invariance, AT in DMs requires equivariance to keep the diffusion process aligned with the data distribution. AT is a way to enforce smoothness in the diffusion flow, improving robustness to outliers and corrupted data. Unlike prior art, our method makes no assumptions about the noise model and integrates seamlessly into diffusion training by adding random noise, similar to randomized smoothing, or adversarial noise, akin to AT. This enables intrinsic capabilities such as handling noisy data, dealing with extreme variability such as outliers, preventing memorization, and improving robustness. We rigorously evaluate our approach with proof-of-concept datasets with known distributions in low- and high-dimensional space, thereby taking a perfect measure of errors; we further evaluate on standard benchmarks such as CIFAR-10, CelebA and LSUN Bedroom, showing strong performance under severe noise, data corruption, and iterative adversarial attacks.
MASS: MoErging through Adaptive Subspace Selection
Apr 06, 2025



Model merging has recently emerged as a lightweight alternative to ensembling, combining multiple fine-tuned models into a single set of parameters with no additional training overhead. Yet, existing merging methods fall short of matching the full accuracy of separately fine-tuned endpoints. We present MASS (MoErging through Adaptive Subspace Selection), a new approach that closes this gap by unifying multiple fine-tuned models while retaining near state-of-the-art performance across tasks. Building on the low-rank decomposition of per-task updates, MASS stores only the most salient singular components for each task and merges them into a shared model. At inference time, a non-parametric, data-free router identifies which subspace (or combination thereof) best explains an input's intermediate features and activates the corresponding task-specific block. This procedure is fully training-free and introduces only a two-pass inference overhead plus a ~2 storage factor compared to a single pretrained model, irrespective of the number of tasks. We evaluate MASS on CLIP-based image classification using ViT-B-16, ViT-B-32 and ViT-L-14 for benchmarks of 8, 14 and 20 tasks respectively, establishing a new state-of-the-art. Most notably, MASS recovers up to ~98% of the average accuracy of individual fine-tuned models, making it a practical alternative to ensembling at a fraction of the storage cost.
Language-guided Hierarchical Fine-grained Image Forgery Detection and Localization
Oct 31, 2024Differences in forgery attributes of images generated in CNN-synthesized and image-editing domains are large, and such differences make a unified image forgery detection and localization (IFDL) challenging. To this end, we present a hierarchical fine-grained formulation for IFDL representation learning. Specifically, we first represent forgery attributes of a manipulated image with multiple labels at different levels. Then, we perform fine-grained classification at these levels using the hierarchical dependency between them. As a result, the algorithm is encouraged to learn both comprehensive features and the inherent hierarchical nature of different forgery attributes. In this work, we propose a Language-guided Hierarchical Fine-grained IFDL, denoted as HiFi-Net++. Specifically, HiFi-Net++ contains four components: a multi-branch feature extractor, a language-guided forgery localization enhancer, as well as classification and localization modules. Each branch of the multi-branch feature extractor learns to classify forgery attributes at one level, while localization and classification modules segment pixel-level forgery regions and detect image-level forgery, respectively. Also, the language-guided forgery localization enhancer (LFLE), containing image and text encoders learned by contrastive language-image pre-training (CLIP), is used to further enrich the IFDL representation. LFLE takes specifically designed texts and the given image as multi-modal inputs and then generates the visual embedding and manipulation score maps, which are used to further improve HiFi-Net++ manipulation localization performance. Lastly, we construct a hierarchical fine-grained dataset to facilitate our study. We demonstrate the effectiveness of our method on $8$ by using different benchmarks for both tasks of IFDL and forgery attribute classification. Our source code and dataset are available.
Environment Maps Editing using Inverse Rendering and Adversarial Implicit Functions
Oct 24, 2024



Editing High Dynamic Range (HDR) environment maps using an inverse differentiable rendering architecture is a complex inverse problem due to the sparsity of relevant pixels and the challenges in balancing light sources and background. The pixels illuminating the objects are a small fraction of the total image, leading to noise and convergence issues when the optimization directly involves pixel values. HDR images, with pixel values beyond the typical Standard Dynamic Range (SDR), pose additional challenges. Higher learning rates corrupt the background during optimization, while lower learning rates fail to manipulate light sources. Our work introduces a novel method for editing HDR environment maps using a differentiable rendering, addressing sparsity and variance between values. Instead of introducing strong priors that extract the relevant HDR pixels and separate the light sources, or using tricks such as optimizing the HDR image in the log space, we propose to model the optimized environment map with a new variant of implicit neural representations able to handle HDR images. The neural representation is trained with adversarial perturbations over the weights to ensure smooth changes in the output when it receives gradients from the inverse rendering. In this way, we obtain novel and cheap environment maps without relying on latent spaces of expensive generative models, maintaining the original visual consistency. Experimental results demonstrate the method's effectiveness in reconstructing the desired lighting effects while preserving the fidelity of the map and reflections on objects in the scene. Our approach can pave the way to interesting tasks, such as estimating a new environment map given a rendering with novel light sources, maintaining the initial perceptual features, and enabling brush stroke-based editing of existing environment maps.
Perturb, Attend, Detect and Localize (PADL): Robust Proactive Image Defense
Sep 26, 2024



Image manipulation detection and localization have received considerable attention from the research community given the blooming of Generative Models (GMs). Detection methods that follow a passive approach may overfit to specific GMs, limiting their application in real-world scenarios, due to the growing diversity of generative models. Recently, approaches based on a proactive framework have shown the possibility of dealing with this limitation. However, these methods suffer from two main limitations, which raises concerns about potential vulnerabilities: i) the manipulation detector is not robust to noise and hence can be easily fooled; ii) the fact that they rely on fixed perturbations for image protection offers a predictable exploit for malicious attackers, enabling them to reverse-engineer and evade detection. To overcome this issue we propose PADL, a new solution able to generate image-specific perturbations using a symmetric scheme of encoding and decoding based on cross-attention, which drastically reduces the possibility of reverse engineering, even when evaluated with adaptive attack [31]. Additionally, PADL is able to pinpoint manipulated areas, facilitating the identification of specific regions that have undergone alterations, and has more generalization power than prior art on held-out generative models. Indeed, although being trained only on an attribute manipulation GAN model [15], our method generalizes to a range of unseen models with diverse architectural designs, such as StarGANv2, BlendGAN, DiffAE, StableDiffusion and StableDiffusionXL. Additionally, we introduce a novel evaluation protocol, which offers a fair evaluation of localisation performance in function of detection accuracy and better captures real-world scenarios.
Shedding More Light on Robust Classifiers under the lens of Energy-based Models
Jul 11, 2024



By reinterpreting a robust discriminative classifier as Energy-based Model (EBM), we offer a new take on the dynamics of adversarial training (AT). Our analysis of the energy landscape during AT reveals that untargeted attacks generate adversarial images much more in-distribution (lower energy) than the original data from the point of view of the model. Conversely, we observe the opposite for targeted attacks. On the ground of our thorough analysis, we present new theoretical and practical results that show how interpreting AT energy dynamics unlocks a better understanding: (1) AT dynamic is governed by three phases and robust overfitting occurs in the third phase with a drastic divergence between natural and adversarial energies (2) by rewriting the loss of TRadeoff-inspired Adversarial DEfense via Surrogate-loss minimization (TRADES) in terms of energies, we show that TRADES implicitly alleviates overfitting by means of aligning the natural energy with the adversarial one (3) we empirically show that all recent state-of-the-art robust classifiers are smoothing the energy landscape and we reconcile a variety of studies about understanding AT and weighting the loss function under the umbrella of EBMs. Motivated by rigorous evidence, we propose Weighted Energy Adversarial Training (WEAT), a novel sample weighting scheme that yields robust accuracy matching the state-of-the-art on multiple benchmarks such as CIFAR-10 and SVHN and going beyond in CIFAR-100 and Tiny-ImageNet. We further show that robust classifiers vary in the intensity and quality of their generative capabilities, and offer a simple method to push this capability, reaching a remarkable Inception Score (IS) and FID using a robust classifier without training for generative modeling. The code to reproduce our results is available at http://github.com/OmnAI-Lab/Robust-Classifiers-under-the-lens-of-EBM/ .
Exploring the Connection between Robust and Generative Models
Apr 08, 2023



We offer a study that connects robust discriminative classifiers trained with adversarial training (AT) with generative modeling in the form of Energy-based Models (EBM). We do so by decomposing the loss of a discriminative classifier and showing that the discriminative model is also aware of the input data density. Though a common assumption is that adversarial points leave the manifold of the input data, our study finds out that, surprisingly, untargeted adversarial points in the input space are very likely under the generative model hidden inside the discriminative classifier -- have low energy in the EBM. We present two evidence: untargeted attacks are even more likely than the natural data and their likelihood increases as the attack strength increases. This allows us to easily detect them and craft a novel attack called High-Energy PGD that fools the classifier yet has energy similar to the data set.