 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Provable Energy-Guided Test-Time Defense Boosting Adversarial Robustness of Large Vision-Language Models
Mar 31, 2026Despite the rapid progress in multimodal models and Large Visual-Language Models (LVLM), they remain highly susceptible to adversarial perturbations, raising serious concerns about their reliability in real-world use. While adversarial training has become the leading paradigm for building models that are robust to adversarial attacks, Test-Time Transformations (TTT) have emerged as a promising strategy to boost robustness at inference. In light of this, we propose Energy-Guided Test-Time Transformation (ET3), a lightweight, training-free defense that enhances the robustness by minimizing the energy of the input samples. Our method is grounded in a theory that proves our transformation succeeds in classification under reasonable assumptions. We present extensive experiments demonstrating that ET3 provides a strong defense for classifiers, zero-shot classification with CLIP, and also for boosting the robustness of LVLMs in tasks such as Image Captioning and Visual Question Answering. Code is available at github.com/OmnAI-Lab/Energy-Guided-Test-Time-Defense .
Understanding Adversarial Training with Energy-based Models
May 28, 2025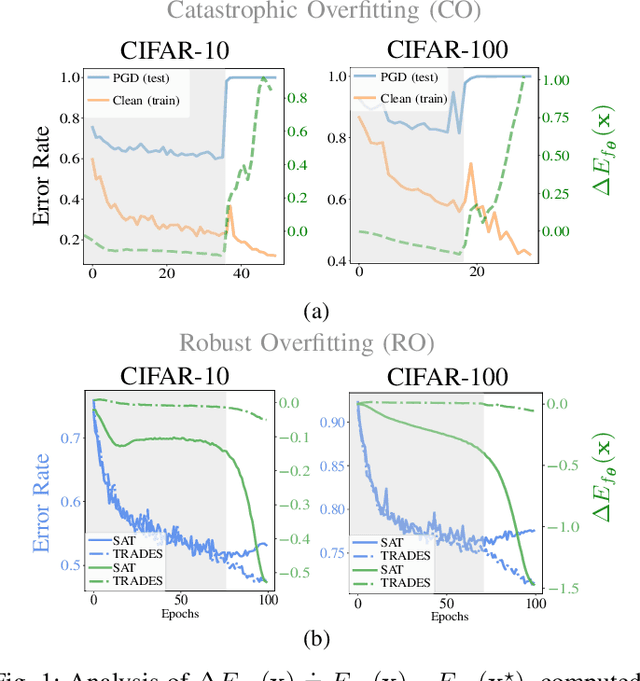
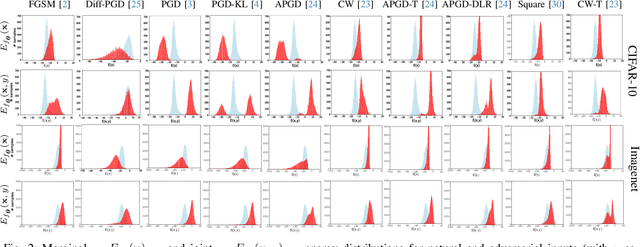
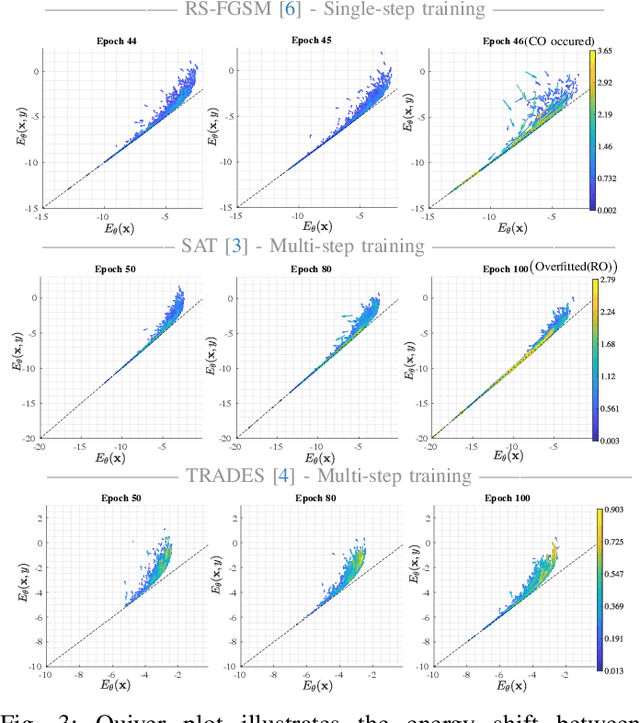
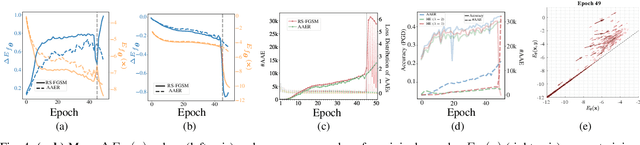
We aim at using Energy-based Model (EBM) framework to better understand adversarial training (AT) in classifiers, and additionally to analyze the intrinsic generative capabilities of robust classifiers. By viewing standard classifiers through an energy lens, we begin by analyzing how the energies of adversarial examples, generated by various attacks, differ from those of the natural samples. The central focus of our work is to understand the critical phenomena of Catastrophic Overfitting (CO) and Robust Overfitting (RO) in AT from an energy perspective. We analyze the impact of existing AT approaches on the energy of samples during training and observe that the behavior of the ``delta energy' -- change in energy between original sample and its adversarial counterpart -- diverges significantly when CO or RO occurs. After a thorough analysis of these energy dynamics and their relationship with overfitting, we propose a novel regularizer, the Delta Energy Regularizer (DER), designed to smoothen the energy landscape during training. We demonstrate that DER is effective in mitigating both CO and RO across multiple benchmarks. We further show that robust classifiers, when being used as generative models, have limits in handling trade-off between image quality and variability. We propose an improved technique based on a local class-wise principal component analysis (PCA) and energy-based guidance for better class-specific initialization and adaptive stopping, enhancing sample diversity and generation quality. Considering that we do not explicitly train for generative modeling, we achieve a competitive Inception Score (IS) and Fr\'echet inception distance (FID) compared to hybrid discriminative-generative models.
What is Adversarial Training for Diffusion Models?
May 27, 2025We answer the question in the title, showing that adversarial training (AT) for diffusion models (DMs) fundamentally differs from classifiers: while AT in classifiers enforces output invariance, AT in DMs requires equivariance to keep the diffusion process aligned with the data distribution. AT is a way to enforce smoothness in the diffusion flow, improving robustness to outliers and corrupted data. Unlike prior art, our method makes no assumptions about the noise model and integrates seamlessly into diffusion training by adding random noise, similar to randomized smoothing, or adversarial noise, akin to AT. This enables intrinsic capabilities such as handling noisy data, dealing with extreme variability such as outliers, preventing memorization, and improving robustness. We rigorously evaluate our approach with proof-of-concept datasets with known distributions in low- and high-dimensional space, thereby taking a perfect measure of errors; we further evaluate on standard benchmarks such as CIFAR-10, CelebA and LSUN Bedroom, showing strong performance under severe noise, data corruption, and iterative adversarial attacks.
Shedding More Light on Robust Classifiers under the lens of Energy-based Models
Jul 11, 2024



By reinterpreting a robust discriminative classifier as Energy-based Model (EBM), we offer a new take on the dynamics of adversarial training (AT). Our analysis of the energy landscape during AT reveals that untargeted attacks generate adversarial images much more in-distribution (lower energy) than the original data from the point of view of the model. Conversely, we observe the opposite for targeted attacks. On the ground of our thorough analysis, we present new theoretical and practical results that show how interpreting AT energy dynamics unlocks a better understanding: (1) AT dynamic is governed by three phases and robust overfitting occurs in the third phase with a drastic divergence between natural and adversarial energies (2) by rewriting the loss of TRadeoff-inspired Adversarial DEfense via Surrogate-loss minimization (TRADES) in terms of energies, we show that TRADES implicitly alleviates overfitting by means of aligning the natural energy with the adversarial one (3) we empirically show that all recent state-of-the-art robust classifiers are smoothing the energy landscape and we reconcile a variety of studies about understanding AT and weighting the loss function under the umbrella of EBMs. Motivated by rigorous evidence, we propose Weighted Energy Adversarial Training (WEAT), a novel sample weighting scheme that yields robust accuracy matching the state-of-the-art on multiple benchmarks such as CIFAR-10 and SVHN and going beyond in CIFAR-100 and Tiny-ImageNet. We further show that robust classifiers vary in the intensity and quality of their generative capabilities, and offer a simple method to push this capability, reaching a remarkable Inception Score (IS) and FID using a robust classifier without training for generative modeling. The code to reproduce our results is available at http://github.com/OmnAI-Lab/Robust-Classifiers-under-the-lens-of-EBM/ .