 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Hyperbolic Geometry for Harmful Prompt Detection and Sanitization
Apr 07, 2026Vision-Language Models (VLMs) have become essential for tasks such as image synthesis, captioning, and retrieval by aligning textual and visual information in a shared embedding space. Yet, this flexibility also makes them vulnerable to malicious prompts designed to produce unsafe content, raising critical safety concerns. Existing defenses either rely on blacklist filters, which are easily circumvented, or on heavy classifier-based systems, both of which are costly and fragile under embedding-level attacks. We address these challenges with two complementary components: Hyperbolic Prompt Espial (HyPE) and Hyperbolic Prompt Sanitization (HyPS). HyPE is a lightweight anomaly detector that leverages the structured geometry of hyperbolic space to model benign prompts and detect harmful ones as outliers. HyPS builds on this detection by applying explainable attribution methods to identify and selectively modify harmful words, neutralizing unsafe intent while preserving the original semantics of user prompts. Through extensive experiments across multiple datasets and adversarial scenarios, we prove that our framework consistently outperforms prior defenses in both detection accuracy and robustness. Together, HyPE and HyPS offer an efficient, interpretable, and resilient approach to safeguarding VLMs against malicious prompt misuse.
Not All Latent Spaces Are Flat: Hyperbolic Concept Control
Mar 14, 2026As modern text-to-image (T2I) models draw closer to synthesizing highly realistic content, the threat of unsafe content generation grows, and it becomes paramount to exercise control. Existing approaches steer these models by applying Euclidean adjustments to text embeddings, redirecting the generation away from unsafe concepts. In this work, we introduce hyperbolic control (HyCon): a novel control mechanism based on parallel transport that leverages semantically aligned hyperbolic representation space to yield more expressive and stable manipulation of concepts. HyCon reuses off-the-shelf generative models and a state-of-the-art hyperbolic text encoder, linked via a lightweight adapter. HyCon achieves state-of-the-art results across four safety benchmarks and four T2I backbones, showing that hyperbolic steering is a practical and flexible approach for more reliable T2I generation.
Implicit Inversion turns CLIP into a Decoder
May 29, 2025CLIP is a discriminative model trained to align images and text in a shared embedding space. Due to its multimodal structure, it serves as the backbone of many generative pipelines, where a decoder is trained to map from the shared space back to images. In this work, we show that image synthesis is nevertheless possible using CLIP alone -- without any decoder, training, or fine-tuning. Our approach optimizes a frequency-aware implicit neural representation that encourages coarse-to-fine generation by stratifying frequencies across network layers. To stabilize this inverse mapping, we introduce adversarially robust initialization, a lightweight Orthogonal Procrustes projection to align local text and image embeddings, and a blending loss that anchors outputs to natural image statistics. Without altering CLIP's weights, this framework unlocks capabilities such as text-to-image generation, style transfer, and image reconstruction. These findings suggest that discriminative models may hold untapped generative potential, hidden in plain sight.
Understanding Adversarial Training with Energy-based Models
May 28, 2025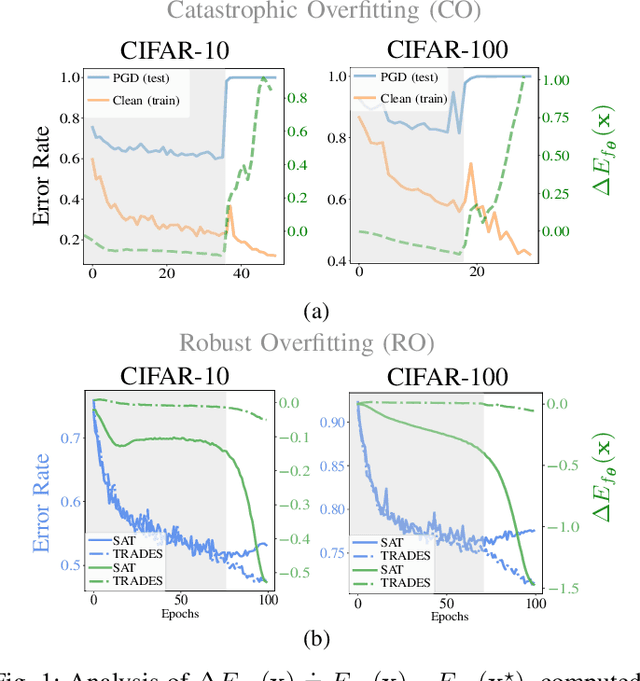
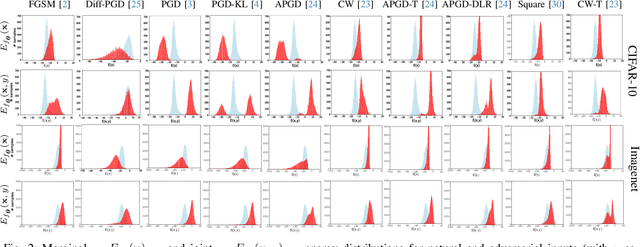
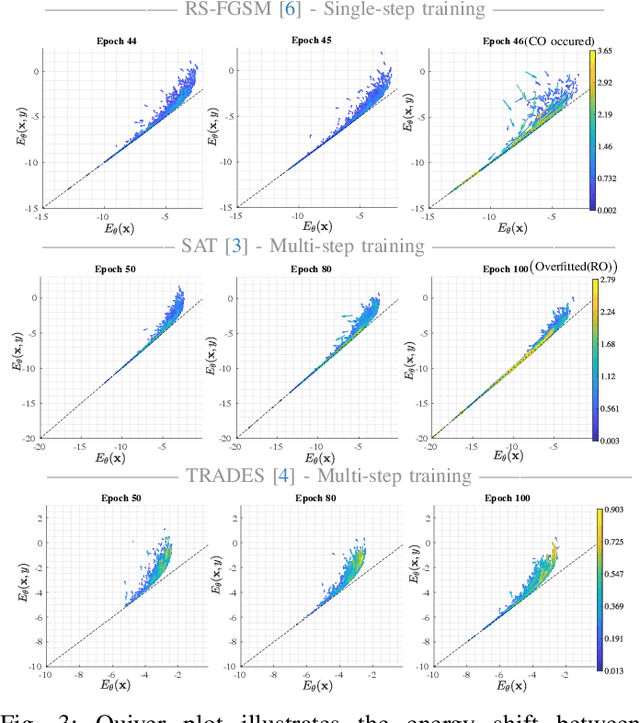
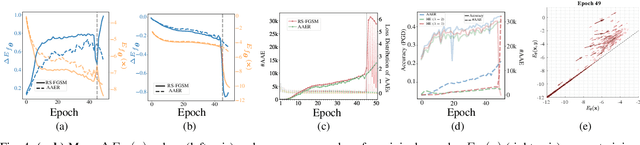
We aim at using Energy-based Model (EBM) framework to better understand adversarial training (AT) in classifiers, and additionally to analyze the intrinsic generative capabilities of robust classifiers. By viewing standard classifiers through an energy lens, we begin by analyzing how the energies of adversarial examples, generated by various attacks, differ from those of the natural samples. The central focus of our work is to understand the critical phenomena of Catastrophic Overfitting (CO) and Robust Overfitting (RO) in AT from an energy perspective. We analyze the impact of existing AT approaches on the energy of samples during training and observe that the behavior of the ``delta energy' -- change in energy between original sample and its adversarial counterpart -- diverges significantly when CO or RO occurs. After a thorough analysis of these energy dynamics and their relationship with overfitting, we propose a novel regularizer, the Delta Energy Regularizer (DER), designed to smoothen the energy landscape during training. We demonstrate that DER is effective in mitigating both CO and RO across multiple benchmarks. We further show that robust classifiers, when being used as generative models, have limits in handling trade-off between image quality and variability. We propose an improved technique based on a local class-wise principal component analysis (PCA) and energy-based guidance for better class-specific initialization and adaptive stopping, enhancing sample diversity and generation quality. Considering that we do not explicitly train for generative modeling, we achieve a competitive Inception Score (IS) and Fr\'echet inception distance (FID) compared to hybrid discriminative-generative models.
Shedding More Light on Robust Classifiers under the lens of Energy-based Models
Jul 11, 2024



By reinterpreting a robust discriminative classifier as Energy-based Model (EBM), we offer a new take on the dynamics of adversarial training (AT). Our analysis of the energy landscape during AT reveals that untargeted attacks generate adversarial images much more in-distribution (lower energy) than the original data from the point of view of the model. Conversely, we observe the opposite for targeted attacks. On the ground of our thorough analysis, we present new theoretical and practical results that show how interpreting AT energy dynamics unlocks a better understanding: (1) AT dynamic is governed by three phases and robust overfitting occurs in the third phase with a drastic divergence between natural and adversarial energies (2) by rewriting the loss of TRadeoff-inspired Adversarial DEfense via Surrogate-loss minimization (TRADES) in terms of energies, we show that TRADES implicitly alleviates overfitting by means of aligning the natural energy with the adversarial one (3) we empirically show that all recent state-of-the-art robust classifiers are smoothing the energy landscape and we reconcile a variety of studies about understanding AT and weighting the loss function under the umbrella of EBMs. Motivated by rigorous evidence, we propose Weighted Energy Adversarial Training (WEAT), a novel sample weighting scheme that yields robust accuracy matching the state-of-the-art on multiple benchmarks such as CIFAR-10 and SVHN and going beyond in CIFAR-100 and Tiny-ImageNet. We further show that robust classifiers vary in the intensity and quality of their generative capabilities, and offer a simple method to push this capability, reaching a remarkable Inception Score (IS) and FID using a robust classifier without training for generative modeling. The code to reproduce our results is available at http://github.com/OmnAI-Lab/Robust-Classifiers-under-the-lens-of-EBM/ .