 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Gating via Damped Oscillations for Adaptive Implicit Neural Representations
Jun 22, 2026Implicit Neural Representations (INRs) have been proven successful in encoding continuous signals through coordinate-based networks, yet facing a spectral dilemma: periodic activations capture fine details but act as all-pass filters that memorise noise, while spatially compact activations regularise effectively but suffer from low-frequency bias. Existing attempts to resolve this trade-off introduce computational overhead or tuning frailty. We propose to model each neuron's activation as the steady-state response of a sinusoidally-forced damped harmonic oscillator, whose amplitude naturally governs the network's spectral selectivity during training. By jointly optimising the oscillator parameters alongside the network weights, our method adapts to the target signal's spectral content without explicit regularisation. Initialised in the stopband, the network exhibits a coarse-to-fine learning curriculum that progressively expands its spectral gate, capturing low-frequency structures first and high-frequency details only when justified by the reconstruction objective. Comprehensive experiments show that our approach consistently achieves state-of-the-art or competitive results against established INRs, while requiring no task-specific tuning of any hyperparameters.
Modulate-and-Map: Crossmodal Feature Mapping with Cross-View Modulation for 3D Anomaly Detection
Apr 02, 2026We present ModMap, a natively multiview and multimodal framework for 3D anomaly detection and segmentation. Unlike existing methods that process views independently, our method draws inspiration from the crossmodal feature mapping paradigm to learn to map features across both modalities and views, while explicitly modelling view-dependent relationships through feature-wise modulation. We introduce a cross-view training strategy that leverages all possible view combinations, enabling effective anomaly scoring through multiview ensembling and aggregation. To process high-resolution 3D data, we train and publicly release a foundational depth encoder tailored to industrial datasets. Experiments on SiM3D, a recent benchmark that introduces the first multiview and multimodal setup for 3D anomaly detection and segmentation, demonstrate that ModMap attains state-of-the-art performance by surpassing previous methods by wide margins.
SiM3D: Single-instance Multiview Multimodal and Multisetup 3D Anomaly Detection Benchmark
Jun 26, 2025We propose SiM3D, the first benchmark considering the integration of multiview and multimodal information for comprehensive 3D anomaly detection and segmentation (ADS), where the task is to produce a voxel-based Anomaly Volume. Moreover, SiM3D focuses on a scenario of high interest in manufacturing: single-instance anomaly detection, where only one object, either real or synthetic, is available for training. In this respect, SiM3D stands out as the first ADS benchmark that addresses the challenge of generalising from synthetic training data to real test data. SiM3D includes a novel multimodal multiview dataset acquired using top-tier industrial sensors and robots. The dataset features multiview high-resolution images (12 Mpx) and point clouds (7M points) for 333 instances of eight types of objects, alongside a CAD model for each type. We also provide manually annotated 3D segmentation GTs for anomalous test samples. To establish reference baselines for the proposed multiview 3D ADS task, we adapt prominent singleview methods and assess their performance using novel metrics that operate on Anomaly Volumes.
Understanding Adversarial Training with Energy-based Models
May 28, 2025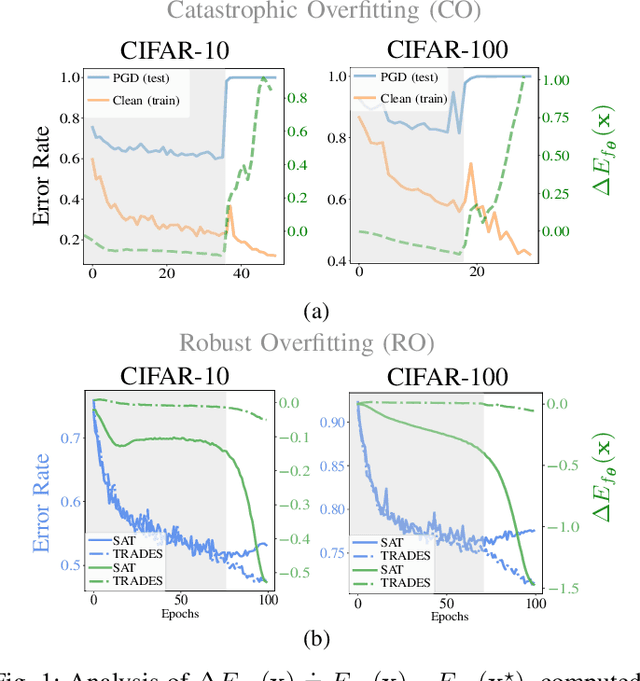
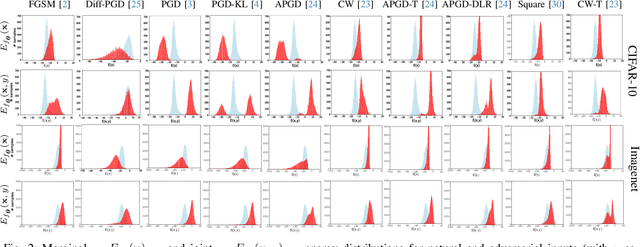
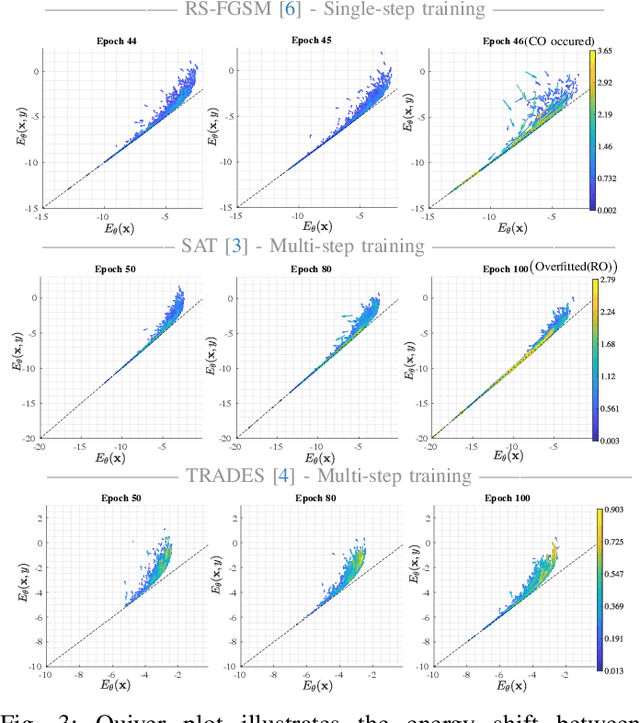
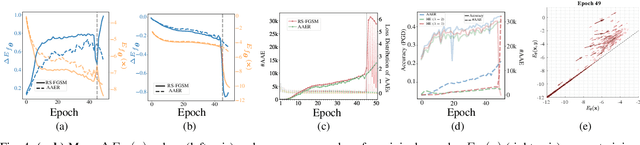
We aim at using Energy-based Model (EBM) framework to better understand adversarial training (AT) in classifiers, and additionally to analyze the intrinsic generative capabilities of robust classifiers. By viewing standard classifiers through an energy lens, we begin by analyzing how the energies of adversarial examples, generated by various attacks, differ from those of the natural samples. The central focus of our work is to understand the critical phenomena of Catastrophic Overfitting (CO) and Robust Overfitting (RO) in AT from an energy perspective. We analyze the impact of existing AT approaches on the energy of samples during training and observe that the behavior of the ``delta energy' -- change in energy between original sample and its adversarial counterpart -- diverges significantly when CO or RO occurs. After a thorough analysis of these energy dynamics and their relationship with overfitting, we propose a novel regularizer, the Delta Energy Regularizer (DER), designed to smoothen the energy landscape during training. We demonstrate that DER is effective in mitigating both CO and RO across multiple benchmarks. We further show that robust classifiers, when being used as generative models, have limits in handling trade-off between image quality and variability. We propose an improved technique based on a local class-wise principal component analysis (PCA) and energy-based guidance for better class-specific initialization and adaptive stopping, enhancing sample diversity and generation quality. Considering that we do not explicitly train for generative modeling, we achieve a competitive Inception Score (IS) and Fr\'echet inception distance (FID) compared to hybrid discriminative-generative models.
What is Adversarial Training for Diffusion Models?
May 27, 2025We answer the question in the title, showing that adversarial training (AT) for diffusion models (DMs) fundamentally differs from classifiers: while AT in classifiers enforces output invariance, AT in DMs requires equivariance to keep the diffusion process aligned with the data distribution. AT is a way to enforce smoothness in the diffusion flow, improving robustness to outliers and corrupted data. Unlike prior art, our method makes no assumptions about the noise model and integrates seamlessly into diffusion training by adding random noise, similar to randomized smoothing, or adversarial noise, akin to AT. This enables intrinsic capabilities such as handling noisy data, dealing with extreme variability such as outliers, preventing memorization, and improving robustness. We rigorously evaluate our approach with proof-of-concept datasets with known distributions in low- and high-dimensional space, thereby taking a perfect measure of errors; we further evaluate on standard benchmarks such as CIFAR-10, CelebA and LSUN Bedroom, showing strong performance under severe noise, data corruption, and iterative adversarial attacks.
Scaling LLaNA: Advancing NeRF-Language Understanding Through Large-Scale Training
Apr 18, 2025Recent advances in Multimodal Large Language Models (MLLMs) have shown remarkable capabilities in understanding both images and 3D data, yet these modalities face inherent limitations in comprehensively representing object geometry and appearance. Neural Radiance Fields (NeRFs) have emerged as a promising alternative, encoding both geometric and photorealistic properties within the weights of a simple Multi-Layer Perceptron (MLP). This work investigates the feasibility and effectiveness of ingesting NeRFs into an MLLM. We introduce LLaNA, the first MLLM able to perform new tasks such as NeRF captioning and Q\&A, by directly processing the weights of a NeRF's MLP. Notably, LLaNA is able to extract information about the represented objects without the need to render images or materialize 3D data structures. In addition, we build the first large-scale NeRF-language dataset, composed by more than 300K NeRFs trained on ShapeNet and Objaverse, with paired textual annotations that enable various NeRF-language tasks. Based on this dataset, we develop a benchmark to evaluate the NeRF understanding capability of our method. Results show that directly processing NeRF weights leads to better performance on NeRF-Language tasks compared to approaches that rely on either 2D or 3D representations derived from NeRFs.
Perturb, Attend, Detect and Localize (PADL): Robust Proactive Image Defense
Sep 26, 2024



Image manipulation detection and localization have received considerable attention from the research community given the blooming of Generative Models (GMs). Detection methods that follow a passive approach may overfit to specific GMs, limiting their application in real-world scenarios, due to the growing diversity of generative models. Recently, approaches based on a proactive framework have shown the possibility of dealing with this limitation. However, these methods suffer from two main limitations, which raises concerns about potential vulnerabilities: i) the manipulation detector is not robust to noise and hence can be easily fooled; ii) the fact that they rely on fixed perturbations for image protection offers a predictable exploit for malicious attackers, enabling them to reverse-engineer and evade detection. To overcome this issue we propose PADL, a new solution able to generate image-specific perturbations using a symmetric scheme of encoding and decoding based on cross-attention, which drastically reduces the possibility of reverse engineering, even when evaluated with adaptive attack [31]. Additionally, PADL is able to pinpoint manipulated areas, facilitating the identification of specific regions that have undergone alterations, and has more generalization power than prior art on held-out generative models. Indeed, although being trained only on an attribute manipulation GAN model [15], our method generalizes to a range of unseen models with diverse architectural designs, such as StarGANv2, BlendGAN, DiffAE, StableDiffusion and StableDiffusionXL. Additionally, we introduce a novel evaluation protocol, which offers a fair evaluation of localisation performance in function of detection accuracy and better captures real-world scenarios.
Looking for Tiny Defects via Forward-Backward Feature Transfer
Jul 04, 2024Motivated by efficiency requirements, most anomaly detection and segmentation (AD&S) methods focus on processing low-resolution images, e.g., $224\times 224$ pixels, obtained by downsampling the original input images. In this setting, downsampling is typically applied also to the provided ground-truth defect masks. Yet, as numerous industrial applications demand identification of both large and tiny defects, the above-described protocol may fall short in providing a realistic picture of the actual performance attainable by current methods. Hence, in this work, we introduce a novel benchmark that evaluates methods on the original, high-resolution image and ground-truth masks, focusing on segmentation performance as a function of the size of anomalies. Our benchmark includes a metric that captures robustness with respect to defect size, i.e., the ability of a method to preserve good localization from large anomalies to tiny ones. Furthermore, we introduce an AD&S approach based on a novel Teacher-Student paradigm which relies on two shallow MLPs (the Students) that learn to transfer patch features across the layers of a frozen vision transformer (the Teacher). By means of our benchmark, we evaluate our proposal and other recent AD&S methods on high-resolution inputs containing large and tiny defects. Our proposal features the highest robustness to defect size, runs at the fastest speed, yields state-of-the-art performance on the MVTec AD dataset and state-of-the-art segmentation performance on the VisA dataset.
LLaNA: Large Language and NeRF Assistant
Jun 17, 2024



Multimodal Large Language Models (MLLMs) have demonstrated an excellent understanding of images and 3D data. However, both modalities have shortcomings in holistically capturing the appearance and geometry of objects. Meanwhile, Neural Radiance Fields (NeRFs), which encode information within the weights of a simple Multi-Layer Perceptron (MLP), have emerged as an increasingly widespread modality that simultaneously encodes the geometry and photorealistic appearance of objects. This paper investigates the feasibility and effectiveness of ingesting NeRF into MLLM. We create LLaNA, the first general-purpose NeRF-language assistant capable of performing new tasks such as NeRF captioning and Q\&A. Notably, our method directly processes the weights of the NeRF's MLP to extract information about the represented objects without the need to render images or materialize 3D data structures. Moreover, we build a dataset of NeRFs with text annotations for various NeRF-language tasks with no human intervention. Based on this dataset, we develop a benchmark to evaluate the NeRF understanding capability of our method. Results show that processing NeRF weights performs favourably against extracting 2D or 3D representations from NeRFs.
Test Time Training for Industrial Anomaly Segmentation
Apr 04, 2024Anomaly Detection and Segmentation (AD&S) is crucial for industrial quality control. While existing methods excel in generating anomaly scores for each pixel, practical applications require producing a binary segmentation to identify anomalies. Due to the absence of labeled anomalies in many real scenarios, standard practices binarize these maps based on some statistics derived from a validation set containing only nominal samples, resulting in poor segmentation performance. This paper addresses this problem by proposing a test time training strategy to improve the segmentation performance. Indeed, at test time, we can extract rich features directly from anomalous samples to train a classifier that can discriminate defects effectively. Our general approach can work downstream to any AD&S method that provides an anomaly score map as output, even in multimodal settings. We demonstrate the effectiveness of our approach over baselines through extensive experimentation and evaluation on MVTec AD and MVTec 3D-AD.