 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMPERE: AMR-Aware Prefix for Generation-Based Event Argument Extraction Model
May 26, 2023Event argument extraction (EAE) identifies event arguments and their specific roles for a given event. Recent advancement in generation-based EAE models has shown great performance and generalizability over classification-based models. However, existing generation-based EAE models mostly focus on problem re-formulation and prompt design, without incorporating additional information that has been shown to be effective for classification-based models, such as the abstract meaning representation (AMR) of the input passages. Incorporating such information into generation-based models is challenging due to the heterogeneous nature of the natural language form prevalently used in generation-based models and the structured form of AMRs. In this work, we study strategies to incorporate AMR into generation-based EAE models. We propose AMPERE, which generates AMR-aware prefixes for every layer of the generation model. Thus, the prefix introduces AMR information to the generation-based EAE model and then improves the generation. We also introduce an adjusted copy mechanism to AMPERE to help overcome potential noises brought by the AMR graph. Comprehensive experiments and analyses on ACE2005 and ERE datasets show that AMPERE can get 4% - 10% absolute F1 score improvements with reduced training data and it is in general powerful across different training sizes.
Code-Switched Text Synthesis in Unseen Language Pairs
May 26, 2023Existing efforts on text synthesis for code-switching mostly require training on code-switched texts in the target language pairs, limiting the deployment of the models to cases lacking code-switched data. In this work, we study the problem of synthesizing code-switched texts for language pairs absent from the training data. We introduce GLOSS, a model built on top of a pre-trained multilingual machine translation model (PMMTM) with an additional code-switching module. This module, either an adapter or extra prefixes, learns code-switching patterns from code-switched data during training, while the primary component of GLOSS, i.e., the PMMTM, is frozen. The design of only adjusting the code-switching module prevents our model from overfitting to the constrained training data for code-switching. Hence, GLOSS exhibits the ability to generalize and synthesize code-switched texts across a broader spectrum of language pairs. Additionally, we develop a self-training algorithm on target language pairs further to enhance the reliability of GLOSS. Automatic evaluations on four language pairs show that GLOSS achieves at least 55% relative BLEU and METEOR scores improvements compared to strong baselines. Human evaluations on two language pairs further validate the success of GLOSS.
Multi-hop Evidence Retrieval for Cross-document Relation Extraction
Dec 21, 2022



Relation Extraction (RE) has been extended to cross-document scenarios because many relations are not simply described in a single document. This inevitably brings the challenge of efficient open-space evidence retrieval to support the inference of cross-document relations, along with the challenge of multi-hop reasoning on top of entities and evidence scattered in an open set of documents. To combat these challenges, we propose Mr.CoD, a multi-hop evidence retrieval method based on evidence path mining and ranking with adapted dense retrievers. We explore multiple variants of retrievers to show evidence retrieval is an essential part in cross-document RE. Experiments on CodRED show that evidence retrieval with Mr.Cod effectively acquires cross-document evidence that essentially supports open-setting cross-document RE. Additionally, we show that Mr.CoD facilitates evidence retrieval and boosts end-to-end RE performance with effective multi-hop reasoning in both closed and open settings of RE.
A Simple and Unified Tagging Model with Priming for Relational Structure Predictions
May 25, 2022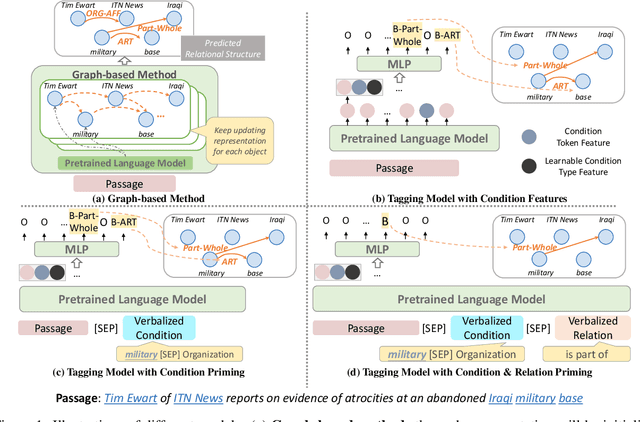
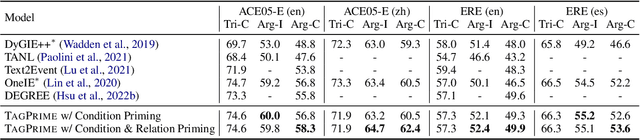
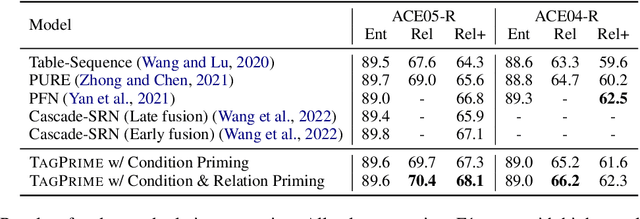
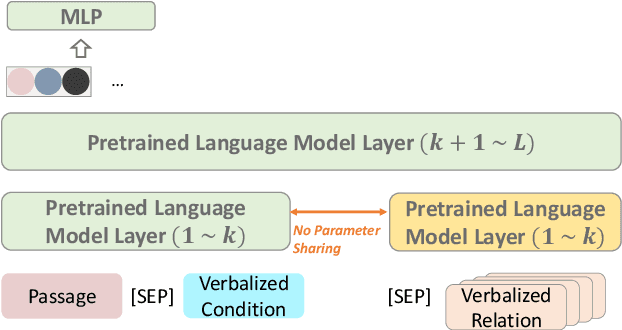
Relational structure extraction covers a wide range of tasks and plays an important role in natural language processing. Recently, many approaches tend to design sophisticated graphical models to capture the complex relations between objects that are described in a sentence. In this work, we demonstrate that simple tagging models can surprisingly achieve competitive performances with a small trick -- priming. Tagging models with priming append information about the operated objects to the input sequence of pretrained language model. Making use of the contextualized nature of pretrained language model, the priming approach help the contextualized representation of the sentence better embed the information about the operated objects, hence, becomes more suitable for addressing relational structure extraction. We conduct extensive experiments on three different tasks that span ten datasets across five different languages, and show that our model is a general and effective model, despite its simplicity. We further carry out comprehensive analysis to understand our model and propose an efficient approximation to our method, which can perform almost the same performance but with faster inference speed.
GENEVA: Pushing the Limit of Generalizability for Event Argument Extraction with 100+ Event Types
May 25, 2022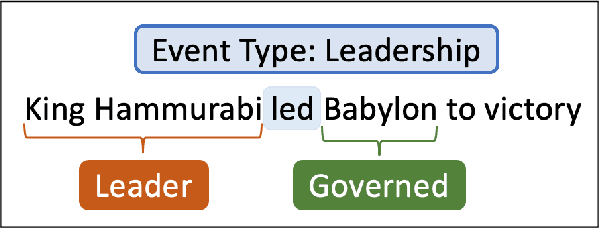
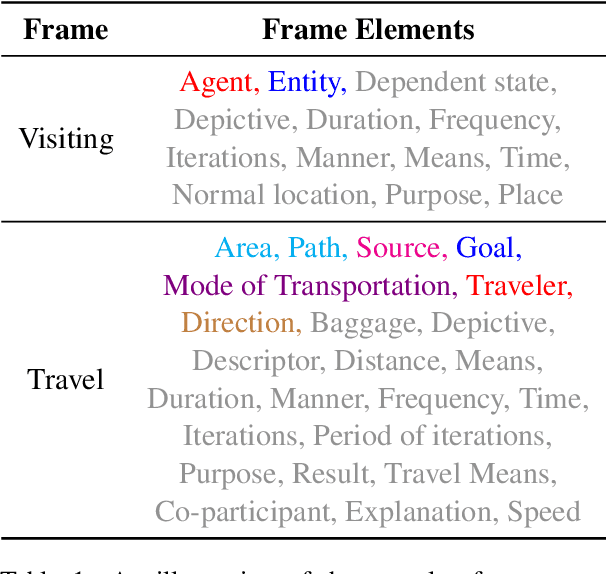
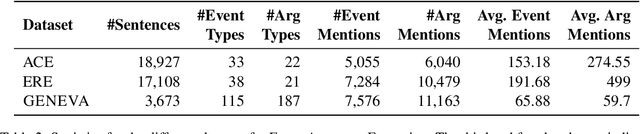
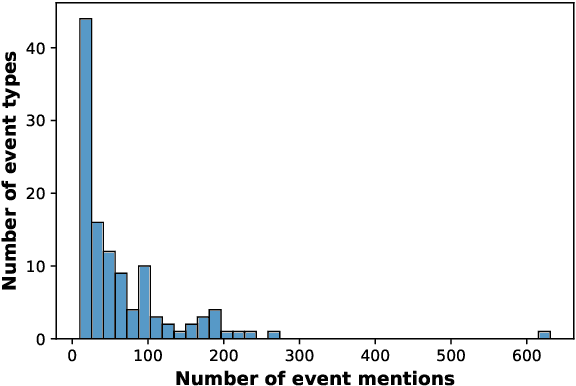
Numerous events occur worldwide and are documented in the news, social media, and various online platforms in raw text. Extracting useful and succinct information about these events is crucial to various downstream applications. Event Argument Extraction (EAE) deals with the task of extracting event-specific information from natural language text. In order to cater to new events and domains in a realistic low-data setting, there is a growing urgency for EAE models to be generalizable. Consequentially, there is a necessity for benchmarking setups to evaluate the generalizability of EAE models. But most existing benchmarking datasets like ACE and ERE have limited coverage in terms of events and cannot adequately evaluate the generalizability of EAE models. To alleviate this issue, we introduce a new dataset GENEVA covering a diverse range of 115 events and 187 argument roles. Using this dataset, we create four benchmarking test suites to assess the model's generalization capability from different perspectives. We benchmark various representative models on these test suites and compare their generalizability relatively. Finally, we propose a new model SCAD that outperforms the previous models and serves as a strong benchmark for these test suites.
Summarization as Indirect Supervision for Relation Extraction
May 19, 2022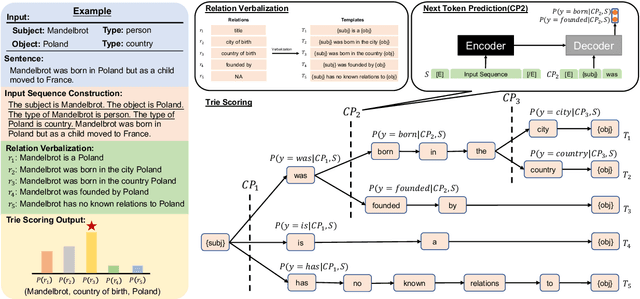
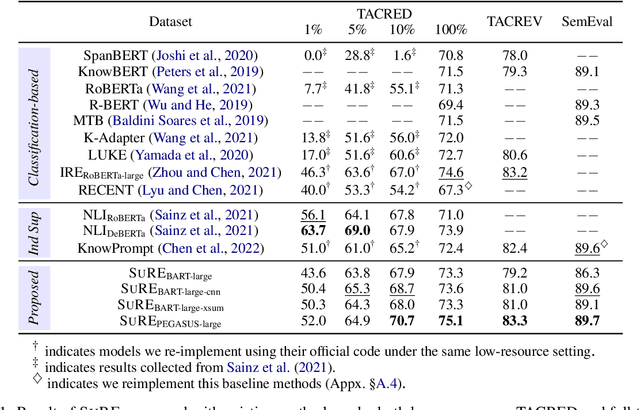
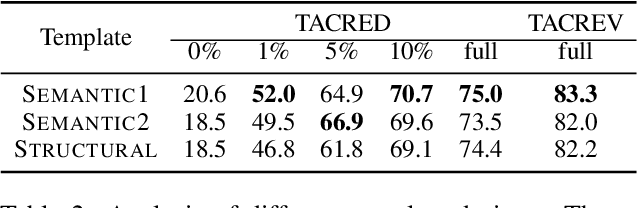

Relation extraction (RE) models have been challenged by their reliance on training data with expensive annotations. Considering that summarization tasks aim at acquiring concise expressions of synoptical information from the longer context, these tasks naturally align with the objective of RE, i.e., extracting a kind of synoptical information that describes the relation of entity mentions. We present SuRE, which converts RE into a summarization formulation. SuRE leads to more precise and resource-efficient RE based on indirect supervision from summarization tasks. To achieve this goal, we develop sentence and relation conversion techniques that essentially bridge the formulation of summarization and RE tasks. We also incorporate constraint decoding techniques with Trie scoring to further enhance summarization-based RE with robust inference. Experiments on three RE datasets demonstrate the effectiveness of SuRE in both full-dataset and low-resource settings, showing that summarization is a promising source of indirect supervision to improve RE models.
Multilingual Generative Language Models for Zero-Shot Cross-Lingual Event Argument Extraction
Mar 15, 2022
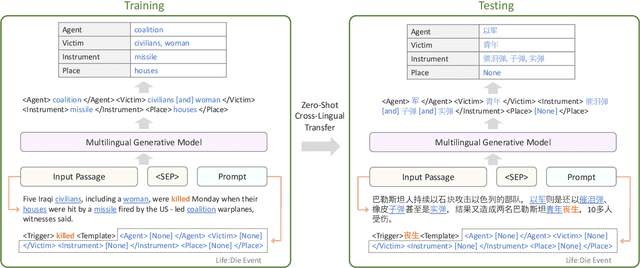
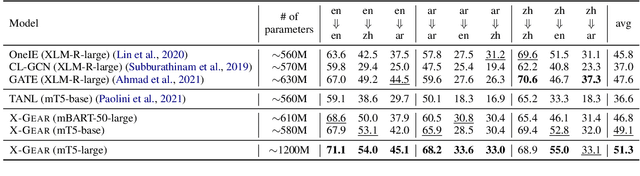
We present a study on leveraging multilingual pre-trained generative language models for zero-shot cross-lingual event argument extraction (EAE). By formulating EAE as a language generation task, our method effectively encodes event structures and captures the dependencies between arguments. We design language-agnostic templates to represent the event argument structures, which are compatible with any language, hence facilitating the cross-lingual transfer. Our proposed model finetunes multilingual pre-trained generative language models to generate sentences that fill in the language-agnostic template with arguments extracted from the input passage. The model is trained on source languages and is then directly applied to target languages for event argument extraction. Experiments demonstrate that the proposed model outperforms the current state-of-the-art models on zero-shot cross-lingual EAE. Comprehensive studies and error analyses are presented to better understand the advantages and the current limitations of using generative language models for zero-shot cross-lingual transfer EAE.
Event Extraction as Natural Language Generation
Aug 29, 2021
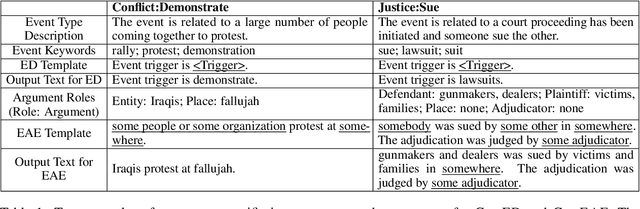
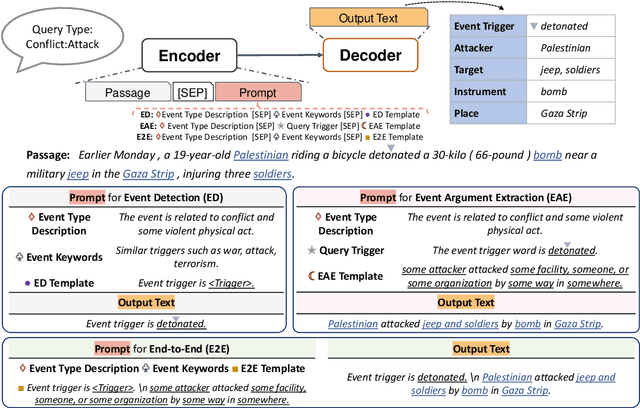
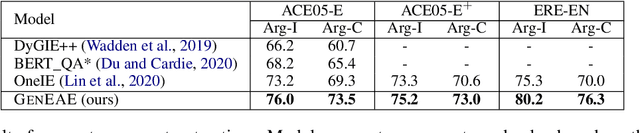
Event extraction (EE), the task that identifies event triggers and their arguments in text, is usually formulated as a classification or structured prediction problem. Such models usually reduce labels to numeric identifiers, making them unable to take advantage of label semantics (e.g. an event type named Arrest is related to words like arrest, detain, or apprehend). This prevents the generalization to new event types. In this work, we formulate EE as a natural language generation task and propose GenEE, a model that not only captures complex dependencies within an event but also generalizes well to unseen or rare event types. Given a passage and an event type, GenEE is trained to generate a natural sentence following a predefined template for that event type. The generated output is then decoded into trigger and argument predictions. The autoregressive generation process naturally models the dependencies among the predictions -- each new word predicted depends on those already generated in the output sentence. Using carefully designed input prompts during generation, GenEE is able to capture label semantics, which enables the generalization to new event types. Empirical results show that our model achieves strong performance on event extraction tasks under all zero-shot, few-shot, and high-resource scenarios. Especially, in the high-resource setting, GenEE outperforms the state-of-the-art model on argument extraction and gets competitive results with the current best on end-to-end EE tasks.
ESTER: A Machine Reading Comprehension Dataset for Event Semantic Relation Reasoning
Apr 16, 2021
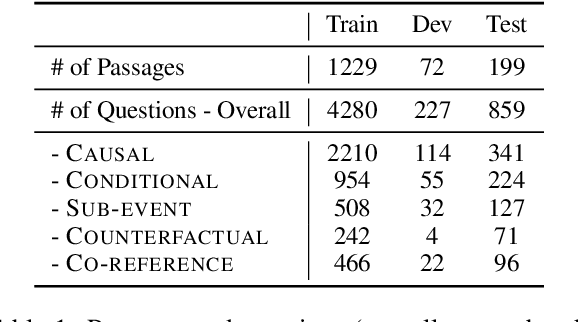
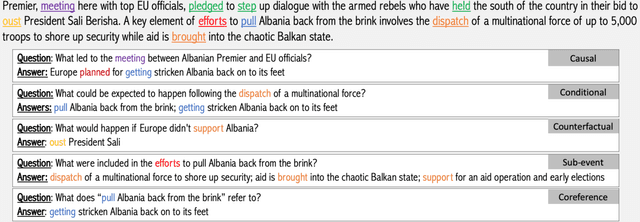
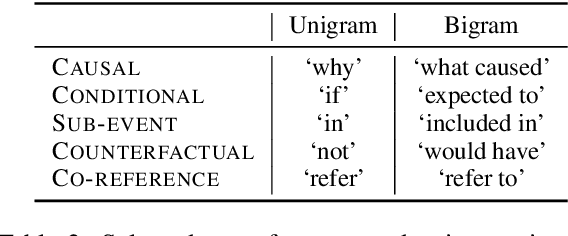
Stories and narratives are composed based on a variety of events. Understanding how these events are semantically related to each other is the essence of reading comprehension. Recent event-centric reading comprehension datasets focus on either event arguments or event temporal commonsense. Although these tasks evaluate machines' ability of narrative understanding, human like reading comprehension requires the capability to process event-based semantics beyond arguments and temporal commonsense. For example, to understand causality between events, we need to infer motivations or purposes; to understand event hierarchy, we need to parse the composition of events. To facilitate these tasks, we introduce ESTER, a comprehensive machine reading comprehension (MRC) dataset for Event Semantic Relation Reasoning. We study five most commonly used event semantic relations and formulate them as question answering tasks. Experimental results show that the current SOTA systems achieve 60.5%, 57.8%, and 76.3% for event-based F1, token based F1 and HIT@1 scores respectively, which are significantly below human performances.
MrGCN: Mirror Graph Convolution Network for Relation Extraction with Long-Term Dependencies
Jan 01, 2021
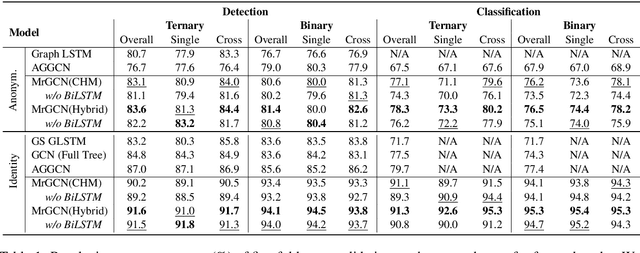
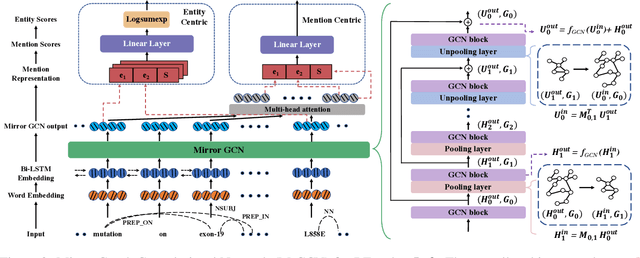
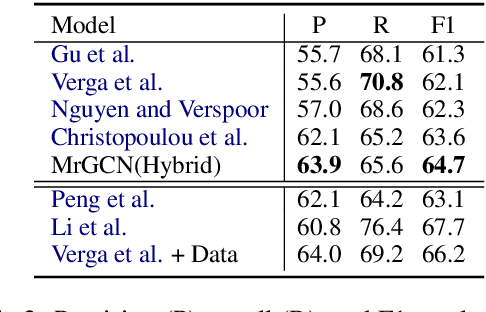
The ability to capture complex linguistic structures and long-term dependencies among words in the passage is essential for many natural language understanding tasks. In relation extraction, dependency trees that contain rich syntactic clues have been widely used to help capture long-term dependencies in text. Graph neural networks (GNNs), one of the means to encode dependency graphs, has been shown effective in several prior works. However, relatively little attention has been paid to the receptive fields of GNNs, which can be crucial in tasks with extremely long text that go beyond single sentences and require discourse analysis. In this work, we leverage the idea of graph pooling and propose the Mirror Graph Convolution Network (MrGCN), a GNN model with pooling-unpooling structures tailored to relation extraction. The pooling branch reduces the graph size and enables the GCN to obtain larger receptive fields within less layers; the unpooling branch restores the pooled graph to its original resolution such that token-level relation extraction can be performed. Experiments on two datasets demonstrate the effectiveness of our method, showing significant improvements over previous results.