 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProGraph-R1: Progress-aware Reinforcement Learning for Graph Retrieval Augmented Generation
Jan 25, 2026Graph Retrieval-Augmented Generation (GraphRAG) has been successfully applied in various knowledge-intensive question answering tasks by organizing external knowledge into structured graphs of entities and relations. It enables large language models (LLMs) to perform complex reasoning beyond text-chunk retrieval. Recent works have employed reinforcement learning (RL) to train agentic GraphRAG frameworks that perform iterative interactions between LLMs and knowledge graphs. However, existing RL-based frameworks such as Graph-R1 suffer from two key limitations: (1) they primarily depend on semantic similarity for retrieval, often overlooking the underlying graph structure, and (2) they rely on sparse, outcome-level rewards, failing to capture the quality of intermediate retrieval steps and their dependencies. To address these limitations, we propose ProGraph-R1, a progress-aware agentic framework for graph-based retrieval and multi-step reasoning. ProGraph-R1 introduces a structure-aware hypergraph retrieval mechanism that jointly considers semantic relevance and graph connectivity, encouraging coherent traversal along multi-hop reasoning paths. We also design a progress-based step-wise policy optimization, which provides dense learning signals by modulating advantages according to intermediate reasoning progress within a graph, rather than relying solely on final outcomes. Experiments on multi-hop question answering benchmarks demonstrate that ProGraph-R1 consistently improves reasoning accuracy and generation quality over existing GraphRAG methods.
Improving Large Molecular Language Model via Relation-aware Multimodal Collaboration
Jan 18, 2026Large language models (LLMs) have demonstrated their instruction-following capabilities and achieved powerful performance on various tasks. Inspired by their success, recent works in the molecular domain have led to the development of large molecular language models (LMLMs) that integrate 1D molecular strings or 2D molecular graphs into the language models. However, existing LMLMs often suffer from hallucination and limited robustness, largely due to inadequate integration of diverse molecular modalities such as 1D sequences, 2D molecular graphs, and 3D conformations. To address these limitations, we propose CoLLaMo, a large language model-based molecular assistant equipped with a multi-level molecular modality-collaborative projector. The relation-aware modality-collaborative attention mechanism in the projector facilitates fine-grained and relation-guided information exchange between atoms by incorporating 2D structural and 3D spatial relations. Furthermore, we present a molecule-centric new automatic measurement, including a hallucination assessment metric and GPT-based caption quality evaluation to address the limitations of token-based generic evaluation metrics (i.e., BLEU) widely used in assessing molecular comprehension of LMLMs. Our extensive experiments demonstrate that our CoLLaMo enhances the molecular modality generalization capabilities of LMLMs, achieving the best performance on multiple tasks, including molecule captioning, computed property QA, descriptive property QA, motif counting, and IUPAC name prediction.
TabFlash: Efficient Table Understanding with Progressive Question Conditioning and Token Focusing
Nov 17, 2025Table images present unique challenges for effective and efficient understanding due to the need for question-specific focus and the presence of redundant background regions. Existing Multimodal Large Language Model (MLLM) approaches often overlook these characteristics, resulting in uninformative and redundant visual representations. To address these issues, we aim to generate visual features that are both informative and compact to improve table understanding. We first propose progressive question conditioning, which injects the question into Vision Transformer layers with gradually increasing frequency, considering each layer's capacity to handle additional information, to generate question-aware visual features. To reduce redundancy, we introduce a pruning strategy that discards background tokens, thereby improving efficiency. To mitigate information loss from pruning, we further propose token focusing, a training strategy that encourages the model to concentrate essential information in the retained tokens. By combining these approaches, we present TabFlash, an efficient and effective MLLM for table understanding. TabFlash achieves state-of-the-art performance, outperforming both open-source and proprietary MLLMs, while requiring 27% less FLOPs and 30% less memory usage compared to the second-best MLLM.
Transferable Model-agnostic Vision-Language Model Adaptation for Efficient Weak-to-Strong Generalization
Aug 13, 2025



Vision-Language Models (VLMs) have been widely used in various visual recognition tasks due to their remarkable generalization capabilities. As these models grow in size and complexity, fine-tuning becomes costly, emphasizing the need to reuse adaptation knowledge from 'weaker' models to efficiently enhance 'stronger' ones. However, existing adaptation transfer methods exhibit limited transferability across models due to their model-specific design and high computational demands. To tackle this, we propose Transferable Model-agnostic adapter (TransMiter), a light-weight adapter that improves vision-language models 'without backpropagation'. TransMiter captures the knowledge gap between pre-trained and fine-tuned VLMs, in an 'unsupervised' manner. Once trained, this knowledge can be seamlessly transferred across different models without the need for backpropagation. Moreover, TransMiter consists of only a few layers, inducing a negligible additional inference cost. Notably, supplementing the process with a few labeled data further yields additional performance gain, often surpassing a fine-tuned stronger model, with a marginal training cost. Experimental results and analyses demonstrate that TransMiter effectively and efficiently transfers adaptation knowledge while preserving generalization abilities across VLMs of different sizes and architectures in visual recognition tasks.
When Model Knowledge meets Diffusion Model: Diffusion-assisted Data-free Image Synthesis with Alignment of Domain and Class
Jun 18, 2025Open-source pre-trained models hold great potential for diverse applications, but their utility declines when their training data is unavailable. Data-Free Image Synthesis (DFIS) aims to generate images that approximate the learned data distribution of a pre-trained model without accessing the original data. However, existing DFIS meth ods produce samples that deviate from the training data distribution due to the lack of prior knowl edge about natural images. To overcome this limitation, we propose DDIS, the first Diffusion-assisted Data-free Image Synthesis method that leverages a text-to-image diffusion model as a powerful image prior, improving synthetic image quality. DDIS extracts knowledge about the learned distribution from the given model and uses it to guide the diffusion model, enabling the generation of images that accurately align with the training data distribution. To achieve this, we introduce Domain Alignment Guidance (DAG) that aligns the synthetic data domain with the training data domain during the diffusion sampling process. Furthermore, we optimize a single Class Alignment Token (CAT) embedding to effectively capture class-specific attributes in the training dataset. Experiments on PACS and Ima geNet demonstrate that DDIS outperforms prior DFIS methods by generating samples that better reflect the training data distribution, achieving SOTA performance in data-free applications.
Efficient multi-view training for 3D Gaussian Splatting
Jun 15, 20253D Gaussian Splatting (3DGS) has emerged as a preferred choice alongside Neural Radiance Fields (NeRF) in inverse rendering due to its superior rendering speed. Currently, the common approach in 3DGS is to utilize "single-view" mini-batch training, where only one image is processed per iteration, in contrast to NeRF's "multi-view" mini-batch training, which leverages multiple images. We observe that such single-view training can lead to suboptimal optimization due to increased variance in mini-batch stochastic gradients, highlighting the necessity for multi-view training. However, implementing multi-view training in 3DGS poses challenges. Simply rendering multiple images per iteration incurs considerable overhead and may result in suboptimal Gaussian densification due to its reliance on single-view assumptions. To address these issues, we modify the rasterization process to minimize the overhead associated with multi-view training and propose a 3D distance-aware D-SSIM loss and multi-view adaptive density control that better suits multi-view scenarios. Our experiments demonstrate that the proposed methods significantly enhance the performance of 3DGS and its variants, freeing 3DGS from the constraints of single-view training.
DeepVideo-R1: Video Reinforcement Fine-Tuning via Difficulty-aware Regressive GRPO
Jun 09, 2025Recent works have demonstrated the effectiveness of reinforcement learning (RL)-based post-training in enhancing the reasoning capabilities of large language models (LLMs). In particular, Group Relative Policy Optimization (GRPO) has shown impressive success by employing a PPO-style reinforcement algorithm with group-based normalized rewards. However, the application of GRPO to Video Large Language Models (Video LLMs) has been less studied. In this paper, we explore GRPO for video LLMs and identify two primary issues that impede its effective learning: (1) reliance on safeguards, and (2) the vanishing advantage problem. To mitigate these challenges, we propose DeepVideo-R1, a video large language model trained with our proposed Reg-GRPO (Regressive GRPO) and difficulty-aware data augmentation strategy. Reg-GRPO reformulates the GRPO objective as a regression task, directly predicting the advantage in GRPO. This design eliminates the need for safeguards like clipping and min functions, thereby facilitating more direct policy guidance by aligning the model with the advantage values. We also design the difficulty-aware data augmentation strategy that dynamically augments training samples at solvable difficulty levels, fostering diverse and informative reward signals. Our comprehensive experiments show that DeepVideo-R1 significantly improves video reasoning performance across multiple video reasoning benchmarks.
Latent Bayesian Optimization via Autoregressive Normalizing Flows
Apr 21, 2025Bayesian Optimization (BO) has been recognized for its effectiveness in optimizing expensive and complex objective functions. Recent advancements in Latent Bayesian Optimization (LBO) have shown promise by integrating generative models such as variational autoencoders (VAEs) to manage the complexity of high-dimensional and structured data spaces. However, existing LBO approaches often suffer from the value discrepancy problem, which arises from the reconstruction gap between input and latent spaces. This value discrepancy problem propagates errors throughout the optimization process, leading to suboptimal outcomes. To address this issue, we propose a Normalizing Flow-based Bayesian Optimization (NF-BO), which utilizes normalizing flow as a generative model to establish one-to-one encoding function from the input space to the latent space, along with its left-inverse decoding function, eliminating the reconstruction gap. Specifically, we introduce SeqFlow, an autoregressive normalizing flow for sequence data. In addition, we develop a new candidate sampling strategy that dynamically adjusts the exploration probability for each token based on its importance. Through extensive experiments, our NF-BO method demonstrates superior performance in molecule generation tasks, significantly outperforming both traditional and recent LBO approaches.
ST-VLM: Kinematic Instruction Tuning for Spatio-Temporal Reasoning in Vision-Language Models
Mar 26, 2025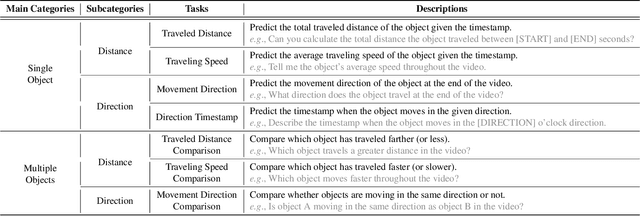

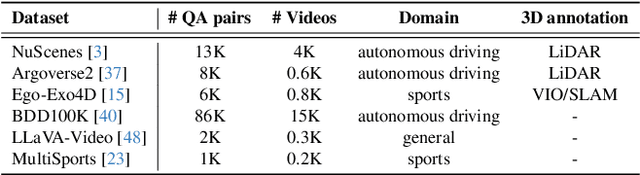
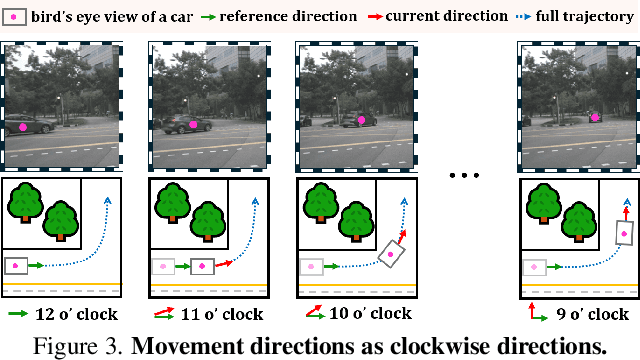
Spatio-temporal reasoning is essential in understanding real-world environments in various fields, eg, autonomous driving and sports analytics. Recent advances have improved the spatial reasoning ability of Vision-Language Models (VLMs) by introducing large-scale data, but these models still struggle to analyze kinematic elements like traveled distance and speed of moving objects. To bridge this gap, we construct a spatio-temporal reasoning dataset and benchmark involving kinematic instruction tuning, referred to as STKit and STKit-Bench. They consist of real-world videos with 3D annotations, detailing object motion dynamics: traveled distance, speed, movement direction, inter-object distance comparisons, and relative movement direction. To further scale such data construction to videos without 3D labels, we propose an automatic pipeline to generate pseudo-labels using 4D reconstruction in real-world scale. With our kinematic instruction tuning data for spatio-temporal reasoning, we present ST-VLM, a VLM enhanced for spatio-temporal reasoning, which exhibits outstanding performance on STKit-Bench. Furthermore, we show that ST-VLM generalizes robustly across diverse domains and tasks, outperforming baselines on other spatio-temporal benchmarks (eg, ActivityNet, TVQA+). Finally, by integrating learned spatio-temporal reasoning with existing abilities, ST-VLM enables complex multi-step reasoning. Project page: https://ikodoh.github.io/ST-VLM.
Super-class guided Transformer for Zero-Shot Attribute Classification
Jan 16, 2025



Attribute classification is crucial for identifying specific characteristics within image regions. Vision-Language Models (VLMs) have been effective in zero-shot tasks by leveraging their general knowledge from large-scale datasets. Recent studies demonstrate that transformer-based models with class-wise queries can effectively address zero-shot multi-label classification. However, poor utilization of the relationship between seen and unseen attributes makes the model lack generalizability. Additionally, attribute classification generally involves many attributes, making maintaining the model's scalability difficult. To address these issues, we propose Super-class guided transFormer (SugaFormer), a novel framework that leverages super-classes to enhance scalability and generalizability for zero-shot attribute classification. SugaFormer employs Super-class Query Initialization (SQI) to reduce the number of queries, utilizing common semantic information from super-classes, and incorporates Multi-context Decoding (MD) to handle diverse visual cues. To strengthen generalizability, we introduce two knowledge transfer strategies that utilize VLMs. During training, Super-class guided Consistency Regularization (SCR) aligns model's features with VLMs using super-class guided prompts, and during inference, Zero-shot Retrieval-based Score Enhancement (ZRSE) refines predictions for unseen attributes. Extensive experiments demonstrate that SugaFormer achieves state-of-the-art performance across three widely-used attribute classification benchmarks under zero-shot, and cross-dataset transfer settings. Our code is available at https://github.com/mlvlab/SugaFormer.