 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOMPASS: A Framework for Evaluating Organization-Specific Policy Alignment in LLMs
Jan 05, 2026As large language models are deployed in high-stakes enterprise applications, from healthcare to finance, ensuring adherence to organization-specific policies has become essential. Yet existing safety evaluations focus exclusively on universal harms. We present COMPASS (Company/Organization Policy Alignment Assessment), the first systematic framework for evaluating whether LLMs comply with organizational allowlist and denylist policies. We apply COMPASS to eight diverse industry scenarios, generating and validating 5,920 queries that test both routine compliance and adversarial robustness through strategically designed edge cases. Evaluating seven state-of-the-art models, we uncover a fundamental asymmetry: models reliably handle legitimate requests (>95% accuracy) but catastrophically fail at enforcing prohibitions, refusing only 13-40% of adversarial denylist violations. These results demonstrate that current LLMs lack the robustness required for policy-critical deployments, establishing COMPASS as an essential evaluation framework for organizational AI safety.
Improving Scientific Document Retrieval with Academic Concept Index
Jan 02, 2026Adapting general-domain retrievers to scientific domains is challenging due to the scarcity of large-scale domain-specific relevance annotations and the substantial mismatch in vocabulary and information needs. Recent approaches address these issues through two independent directions that leverage large language models (LLMs): (1) generating synthetic queries for fine-tuning, and (2) generating auxiliary contexts to support relevance matching. However, both directions overlook the diverse academic concepts embedded within scientific documents, often producing redundant or conceptually narrow queries and contexts. To address this limitation, we introduce an academic concept index, which extracts key concepts from papers and organizes them guided by an academic taxonomy. This structured index serves as a foundation for improving both directions. First, we enhance the synthetic query generation with concept coverage-based generation (CCQGen), which adaptively conditions LLMs on uncovered concepts to generate complementary queries with broader concept coverage. Second, we strengthen the context augmentation with concept-focused auxiliary contexts (CCExpand), which leverages a set of document snippets that serve as concise responses to the concept-aware CCQGen queries. Extensive experiments show that incorporating the academic concept index into both query generation and context augmentation leads to higher-quality queries, better conceptual alignment, and improved retrieval performance.
Personalized Federated Recommendation With Knowledge Guidance
Nov 18, 2025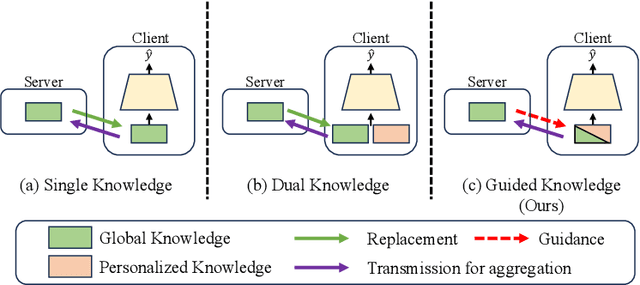


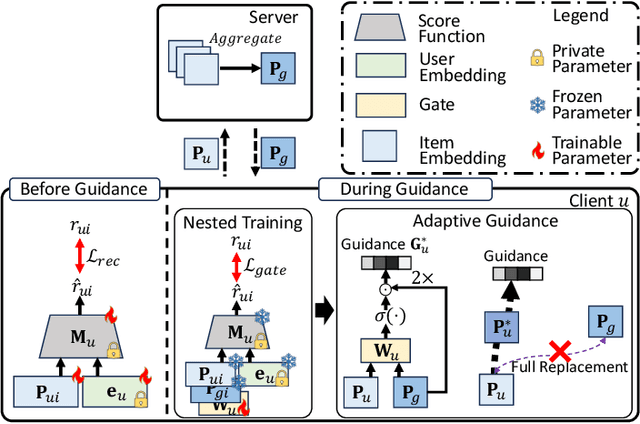
Federated Recommendation (FedRec) has emerged as a key paradigm for building privacy-preserving recommender systems. However, existing FedRec models face a critical dilemma: memory-efficient single-knowledge models suffer from a suboptimal knowledge replacement practice that discards valuable personalization, while high-performance dual-knowledge models are often too memory-intensive for practical on-device deployment. We propose Federated Recommendation with Knowledge Guidance (FedRKG), a model-agnostic framework that resolves this dilemma. The core principle, Knowledge Guidance, avoids full replacement and instead fuses global knowledge into preserved local embeddings, attaining the personalization benefits of dual-knowledge within a single-knowledge memory footprint. Furthermore, we introduce Adaptive Guidance, a fine-grained mechanism that dynamically modulates the intensity of this guidance for each user-item interaction, overcoming the limitations of static fusion methods. Extensive experiments on benchmark datasets demonstrate that FedRKG significantly outperforms state-of-the-art methods, validating the effectiveness of our approach. The code is available at https://github.com/Jaehyung-Lim/fedrkg.
MAP4TS: A Multi-Aspect Prompting Framework for Time-Series Forecasting with Large Language Models
Oct 27, 2025



Recent advances have investigated the use of pretrained large language models (LLMs) for time-series forecasting by aligning numerical inputs with LLM embedding spaces. However, existing multimodal approaches often overlook the distinct statistical properties and temporal dependencies that are fundamental to time-series data. To bridge this gap, we propose MAP4TS, a novel Multi-Aspect Prompting Framework that explicitly incorporates classical time-series analysis into the prompt design. Our framework introduces four specialized prompt components: a Global Domain Prompt that conveys dataset-level context, a Local Domain Prompt that encodes recent trends and series-specific behaviors, and a pair of Statistical and Temporal Prompts that embed handcrafted insights derived from autocorrelation (ACF), partial autocorrelation (PACF), and Fourier analysis. Multi-Aspect Prompts are combined with raw time-series embeddings and passed through a cross-modality alignment module to produce unified representations, which are then processed by an LLM and projected for final forecasting. Extensive experiments across eight diverse datasets show that MAP4TS consistently outperforms state-of-the-art LLM-based methods. Our ablation studies further reveal that prompt-aware designs significantly enhance performance stability and that GPT-2 backbones, when paired with structured prompts, outperform larger models like LLaMA in long-term forecasting tasks.
STEPER: Step-wise Knowledge Distillation for Enhancing Reasoning Ability in Multi-Step Retrieval-Augmented Language Models
Oct 09, 2025Answering complex real-world questions requires step-by-step retrieval and integration of relevant information to generate well-grounded responses. However, existing knowledge distillation methods overlook the need for different reasoning abilities at different steps, hindering transfer in multi-step retrieval-augmented frameworks. To address this, we propose Stepwise Knowledge Distillation for Enhancing Reasoning Ability in Multi-Step Retrieval-Augmented Language Models (StepER). StepER employs step-wise supervision to align with evolving information and reasoning demands across stages. Additionally, it incorporates difficulty-aware training to progressively optimize learning by prioritizing suitable steps. Our method is adaptable to various multi-step retrieval-augmented language models, including those that use retrieval queries for reasoning paths or decomposed questions. Extensive experiments show that StepER outperforms prior methods on multi-hop QA benchmarks, with an 8B model achieving performance comparable to a 70B teacher model.
Topic Coverage-based Demonstration Retrieval for In-Context Learning
Sep 15, 2025The effectiveness of in-context learning relies heavily on selecting demonstrations that provide all the necessary information for a given test input. To achieve this, it is crucial to identify and cover fine-grained knowledge requirements. However, prior methods often retrieve demonstrations based solely on embedding similarity or generation probability, resulting in irrelevant or redundant examples. In this paper, we propose TopicK, a topic coverage-based retrieval framework that selects demonstrations to comprehensively cover topic-level knowledge relevant to both the test input and the model. Specifically, TopicK estimates the topics required by the input and assesses the model's knowledge on those topics. TopicK then iteratively selects demonstrations that introduce previously uncovered required topics, in which the model exhibits low topical knowledge. We validate the effectiveness of TopicK through extensive experiments across various datasets and both open- and closed-source LLMs. Our source code is available at https://github.com/WonbinKweon/TopicK_EMNLP2025.
Federated Continual Recommendation
Aug 06, 2025The increasing emphasis on privacy in recommendation systems has led to the adoption of Federated Learning (FL) as a privacy-preserving solution, enabling collaborative training without sharing user data. While Federated Recommendation (FedRec) effectively protects privacy, existing methods struggle with non-stationary data streams, failing to maintain consistent recommendation quality over time. On the other hand, Continual Learning Recommendation (CLRec) methods address evolving user preferences but typically assume centralized data access, making them incompatible with FL constraints. To bridge this gap, we introduce Federated Continual Recommendation (FCRec), a novel task that integrates FedRec and CLRec, requiring models to learn from streaming data while preserving privacy. As a solution, we propose F3CRec, a framework designed to balance knowledge retention and adaptation under the strict constraints of FCRec. F3CRec introduces two key components: Adaptive Replay Memory on the client side, which selectively retains past preferences based on user-specific shifts, and Item-wise Temporal Mean on the server side, which integrates new knowledge while preserving prior information. Extensive experiments demonstrate that F3CRec outperforms existing approaches in maintaining recommendation quality over time in a federated environment.
From What to Respond to When to Respond: Timely Response Generation for Open-domain Dialogue Agents
Jun 17, 2025While research on dialogue response generation has primarily focused on generating coherent responses conditioning on textual context, the critical question of when to respond grounded on the temporal context remains underexplored. To bridge this gap, we propose a novel task called timely dialogue response generation and introduce the TimelyChat benchmark, which evaluates the capabilities of language models to predict appropriate time intervals and generate time-conditioned responses. Additionally, we construct a large-scale training dataset by leveraging unlabeled event knowledge from a temporal commonsense knowledge graph and employing a large language model (LLM) to synthesize 55K event-driven dialogues. We then train Timer, a dialogue agent designed to proactively predict time intervals and generate timely responses that align with those intervals. Experimental results show that Timer outperforms prompting-based LLMs and other fine-tuned baselines in both turn-level and dialogue-level evaluations. We publicly release our data, model, and code.
Delving into Instance-Dependent Label Noise in Graph Data: A Comprehensive Study and Benchmark
Jun 14, 2025



Graph Neural Networks (GNNs) have achieved state-of-the-art performance in node classification tasks but struggle with label noise in real-world data. Existing studies on graph learning with label noise commonly rely on class-dependent label noise, overlooking the complexities of instance-dependent noise and falling short of capturing real-world corruption patterns. We introduce BeGIN (Benchmarking for Graphs with Instance-dependent Noise), a new benchmark that provides realistic graph datasets with various noise types and comprehensively evaluates noise-handling strategies across GNN architectures, noisy label detection, and noise-robust learning. To simulate instance-dependent corruptions, BeGIN introduces algorithmic methods and LLM-based simulations. Our experiments reveal the challenges of instance-dependent noise, particularly LLM-based corruption, and underscore the importance of node-specific parameterization to enhance GNN robustness. By comprehensively evaluating noise-handling strategies, BeGIN provides insights into their effectiveness, efficiency, and key performance factors. We expect that BeGIN will serve as a valuable resource for advancing research on label noise in graphs and fostering the development of robust GNN training methods. The code is available at https://github.com/kimsu55/BeGIN.
* 17 pages
On the Effectiveness of Integration Methods for Multimodal Dialogue Response Retrieval
Jun 13, 2025Multimodal chatbots have become one of the major topics for dialogue systems in both research community and industry. Recently, researchers have shed light on the multimodality of responses as well as dialogue contexts. This work explores how a dialogue system can output responses in various modalities such as text and image. To this end, we first formulate a multimodal dialogue response retrieval task for retrieval-based systems as the combination of three subtasks. We then propose three integration methods based on a two-step approach and an end-to-end approach, and compare the merits and demerits of each method. Experimental results on two datasets demonstrate that the end-to-end approach achieves comparable performance without an intermediate step in the two-step approach. In addition, a parameter sharing strategy not only reduces the number of parameters but also boosts performance by transferring knowledge across the subtasks and the modalities.