 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS3PRL-VC: Open-source Voice Conversion Framework with Self-supervised Speech Representations
Oct 12, 2021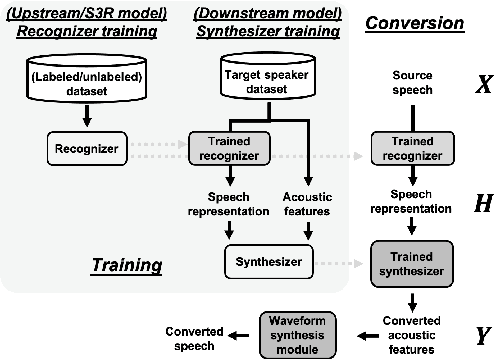
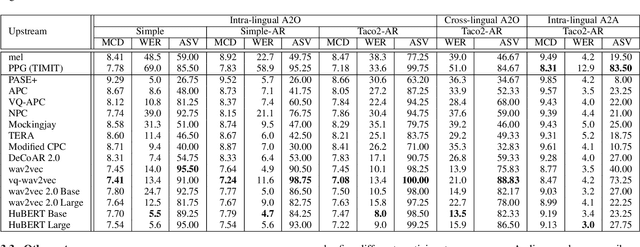
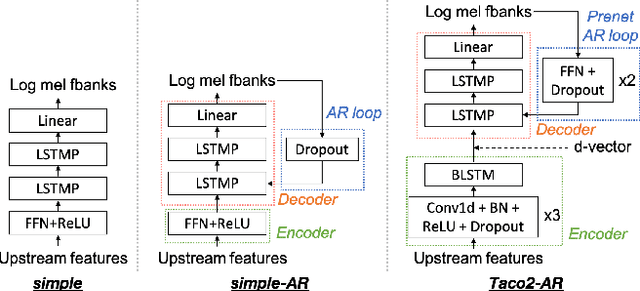
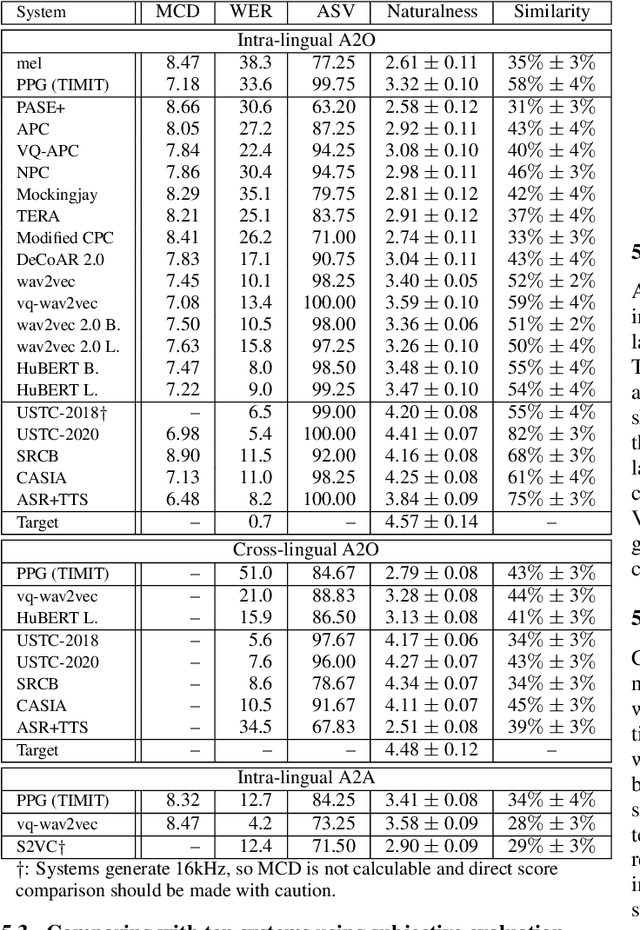
This paper introduces S3PRL-VC, an open-source voice conversion (VC) framework based on the S3PRL toolkit. In the context of recognition-synthesis VC, self-supervised speech representation (S3R) is valuable in its potential to replace the expensive supervised representation adopted by state-of-the-art VC systems. Moreover, we claim that VC is a good probing task for S3R analysis. In this work, we provide a series of in-depth analyses by benchmarking on the two tasks in VCC2020, namely intra-/cross-lingual any-to-one (A2O) VC, as well as an any-to-any (A2A) setting. We also provide comparisons between not only different S3Rs but also top systems in VCC2020 with supervised representations. Systematic objective and subjective evaluation were conducted, and we show that S3R is comparable with VCC2020 top systems in the A2O setting in terms of similarity, and achieves state-of-the-art in S3R-based A2A VC. We believe the extensive analysis, as well as the toolkit itself, contribute to not only the S3R community but also the VC community. The codebase is now open-sourced.
Analyzing the Robustness of Unsupervised Speech Recognition
Oct 12, 2021
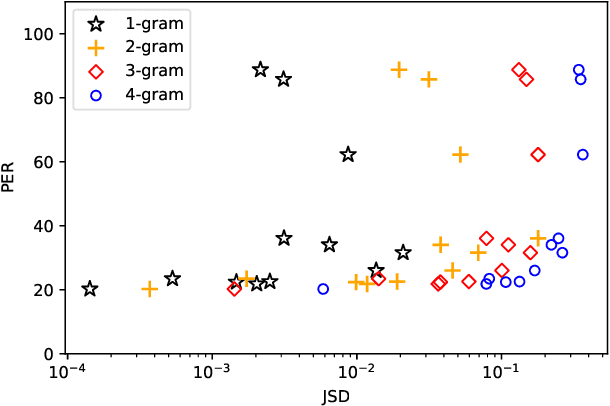
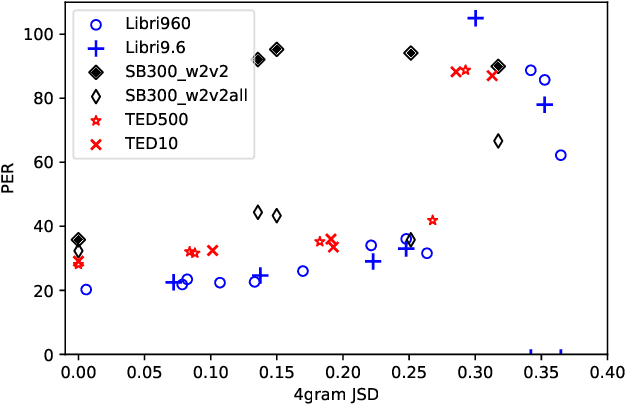
Unsupervised speech recognition (unsupervised ASR) aims to learn the ASR system with non-parallel speech and text corpus only. Wav2vec-U has shown promising results in unsupervised ASR by self-supervised speech representations coupled with Generative Adversarial Network (GAN) training, but the robustness of the unsupervised ASR framework is unknown. In this work, we further analyze the training robustness of unsupervised ASR on the domain mismatch scenarios in which the domains of unpaired speech and text are different. Three domain mismatch scenarios include: (1) using speech and text from different datasets, (2) utilizing noisy/spontaneous speech, and (3) adjusting the amount of speech and text data. We also quantify the degree of the domain mismatch by calculating the JS-divergence of phoneme n-gram between the transcription of speech and text. This metric correlates with the performance highly. Experimental results show that domain mismatch leads to inferior performance, but a self-supervised model pre-trained on the targeted speech domain can extract better representation to alleviate the performance drop.
CheerBots: Chatbots toward Empathy and Emotionusing Reinforcement Learning
Oct 08, 2021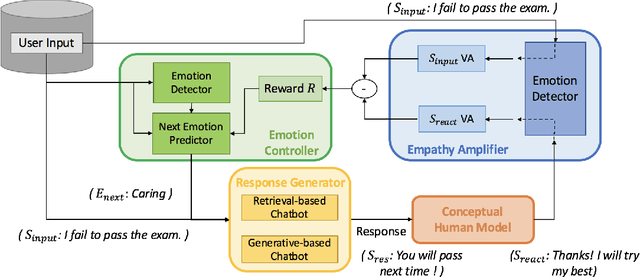
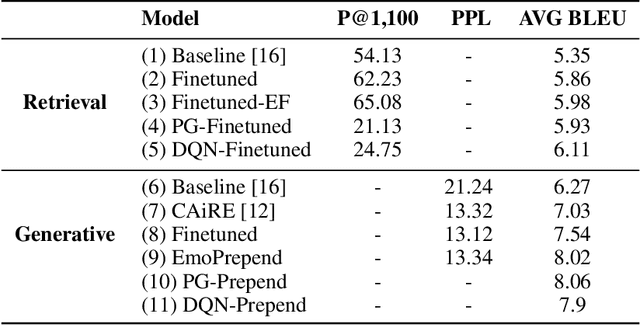
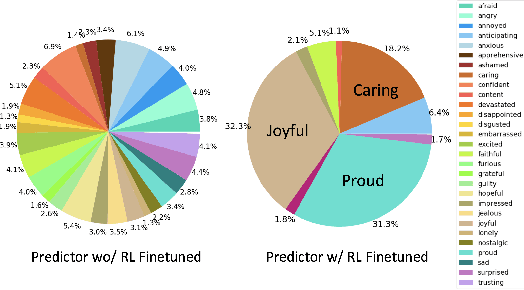
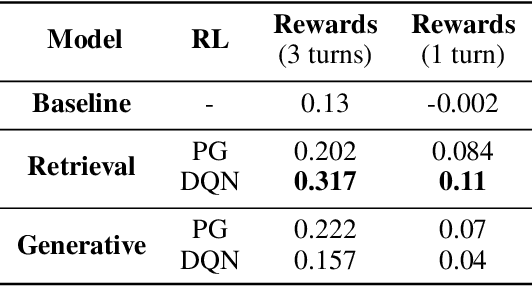
Apart from the coherence and fluency of responses, an empathetic chatbot emphasizes more on people's feelings. By considering altruistic behaviors between human interaction, empathetic chatbots enable people to get a better interactive and supportive experience. This study presents a framework whereby several empathetic chatbots are based on understanding users' implied feelings and replying empathetically for multiple dialogue turns. We call these chatbots CheerBots. CheerBots can be retrieval-based or generative-based and were finetuned by deep reinforcement learning. To respond in an empathetic way, we develop a simulating agent, a Conceptual Human Model, as aids for CheerBots in training with considerations on changes in user's emotional states in the future to arouse sympathy. Finally, automatic metrics and human rating results demonstrate that CheerBots outperform other baseline chatbots and achieves reciprocal altruism. The code and the pre-trained models will be made available.
Is BERT a Cross-Disciplinary Knowledge Learner? A Surprising Finding of Pre-trained Models' Transferability
Mar 12, 2021
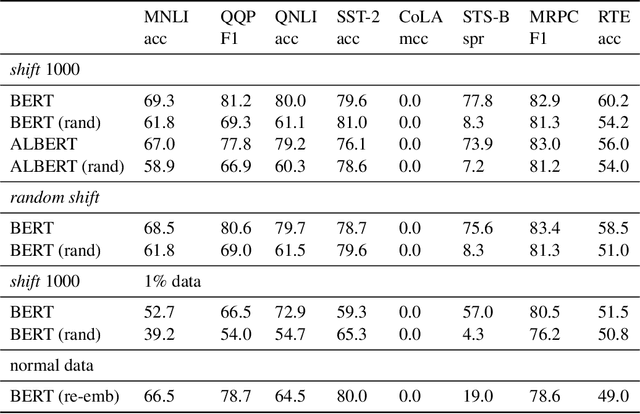
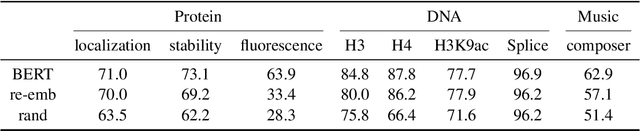
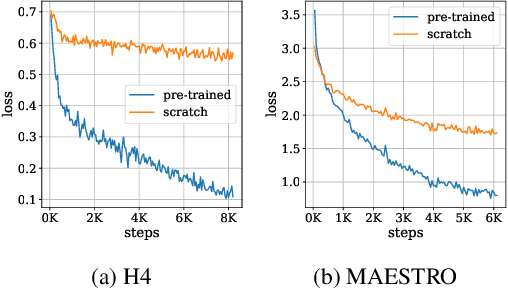
In this paper, we investigate whether the power of the models pre-trained on text data, such as BERT, can be transferred to general token sequence classification applications. To verify pre-trained models' transferability, we test the pre-trained models on (1) text classification tasks with meanings of tokens mismatches, and (2) real-world non-text token sequence classification data, including amino acid sequence, DNA sequence, and music. We find that even on non-text data, the models pre-trained on text converge faster than the randomly initialized models, and the testing performance of the pre-trained models is merely slightly worse than the models designed for the specific tasks.
TaylorGAN: Neighbor-Augmented Policy Update for Sample-Efficient Natural Language Generation
Nov 27, 2020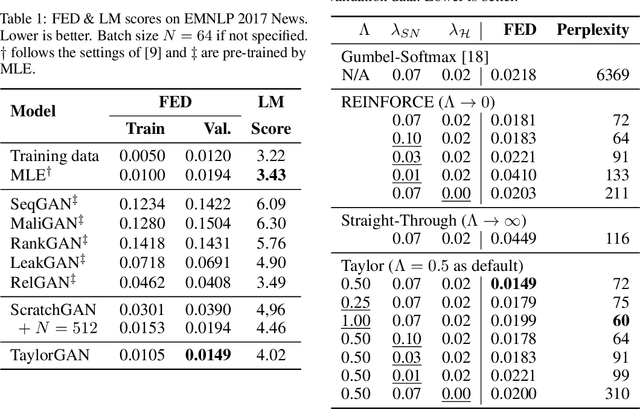
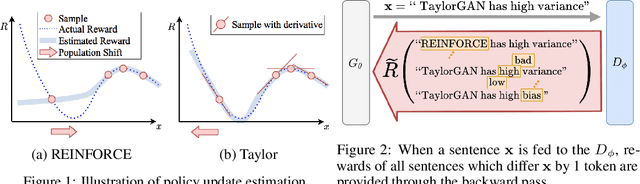
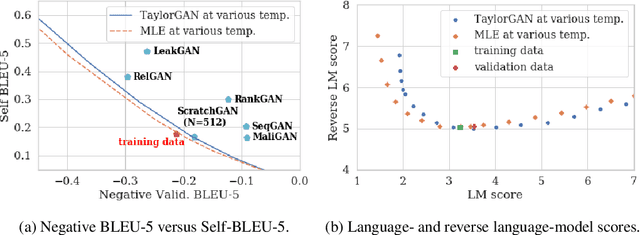
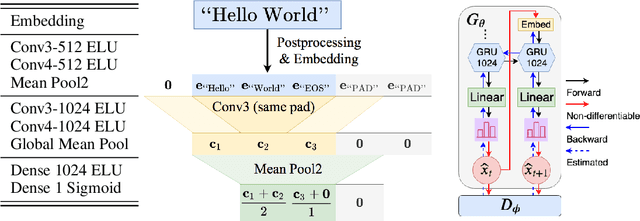
Score function-based natural language generation (NLG) approaches such as REINFORCE, in general, suffer from low sample efficiency and training instability problems. This is mainly due to the non-differentiable nature of the discrete space sampling and thus these methods have to treat the discriminator as a black box and ignore the gradient information. To improve the sample efficiency and reduce the variance of REINFORCE, we propose a novel approach, TaylorGAN, which augments the gradient estimation by off-policy update and the first-order Taylor expansion. This approach enables us to train NLG models from scratch with smaller batch size -- without maximum likelihood pre-training, and outperforms existing GAN-based methods on multiple metrics of quality and diversity. The source code and data are available at https://github.com/MiuLab/TaylorGAN
Semi-Supervised Spoken Language Understanding via Self-Supervised Speech and Language Model Pretraining
Oct 26, 2020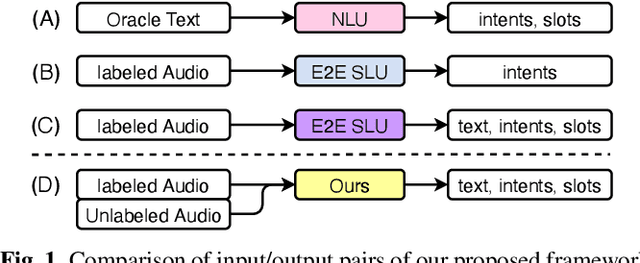
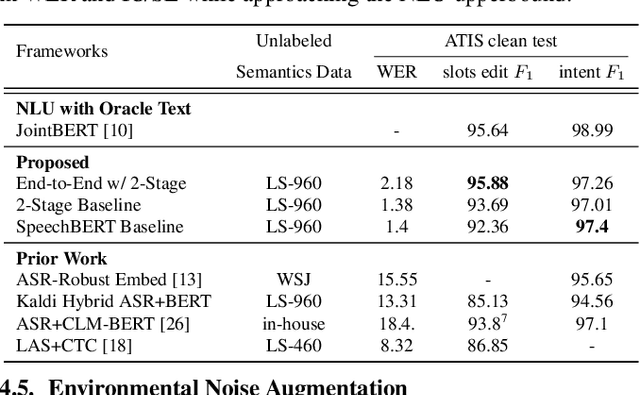
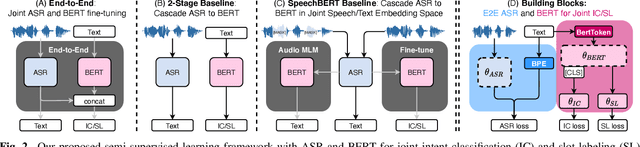
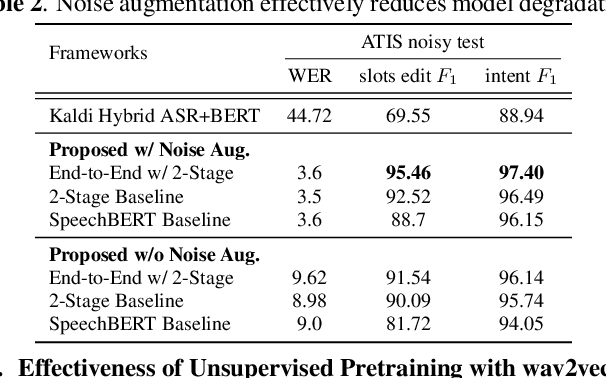
Much recent work on Spoken Language Understanding (SLU) is limited in at least one of three ways: models were trained on oracle text input and neglected ASR errors, models were trained to predict only intents without the slot values, or models were trained on a large amount of in-house data. In this paper, we propose a clean and general framework to learn semantics directly from speech with semi-supervision from transcribed or untranscribed speech to address these issues. Our framework is built upon pretrained end-to-end (E2E) ASR and self-supervised language models, such as BERT, and fine-tuned on a limited amount of target SLU data. We study two semi-supervised settings for the ASR component: supervised pretraining on transcribed speech, and unsupervised pretraining by replacing the ASR encoder with self-supervised speech representations, such as wav2vec. In parallel, we identify two essential criteria for evaluating SLU models: environmental noise-robustness and E2E semantics evaluation. Experiments on ATIS show that our SLU framework with speech as input can perform on par with those using oracle text as input in semantics understanding, even though environmental noise is present and a limited amount of labeled semantics data is available for training.
VQVC+: One-Shot Voice Conversion by Vector Quantization and U-Net architecture
Jun 07, 2020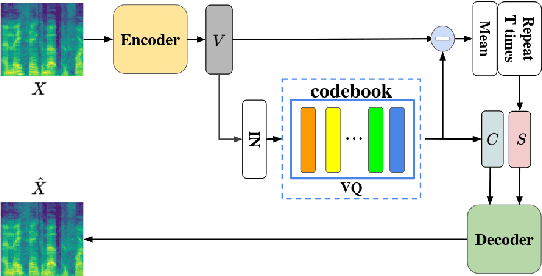
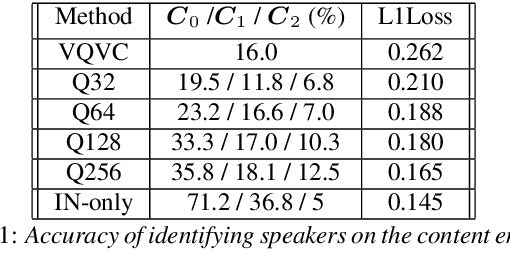
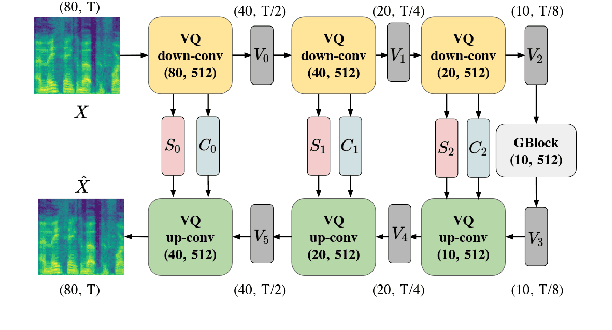
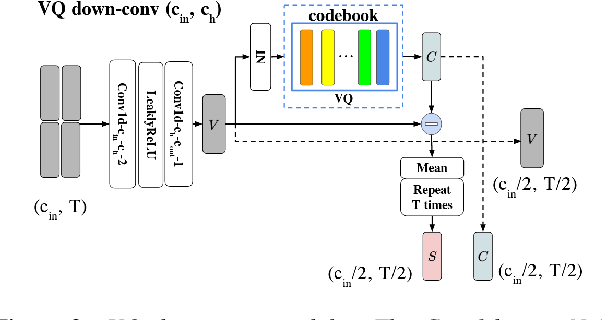
Voice conversion (VC) is a task that transforms the source speaker's timbre, accent, and tones in audio into another one's while preserving the linguistic content. It is still a challenging work, especially in a one-shot setting. Auto-encoder-based VC methods disentangle the speaker and the content in input speech without given the speaker's identity, so these methods can further generalize to unseen speakers. The disentangle capability is achieved by vector quantization (VQ), adversarial training, or instance normalization (IN). However, the imperfect disentanglement may harm the quality of output speech. In this work, to further improve audio quality, we use the U-Net architecture within an auto-encoder-based VC system. We find that to leverage the U-Net architecture, a strong information bottleneck is necessary. The VQ-based method, which quantizes the latent vectors, can serve the purpose. The objective and the subjective evaluations show that the proposed method performs well in both audio naturalness and speaker similarity.
Learning Interpretable and Discrete Representations with Adversarial Training for Unsupervised Text Classification
Apr 28, 2020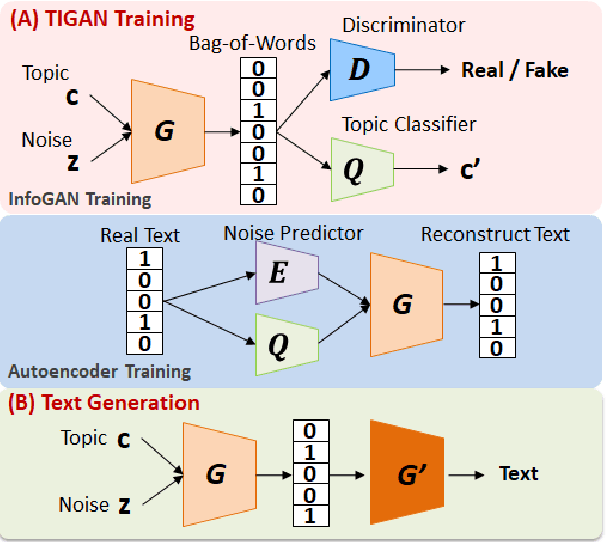
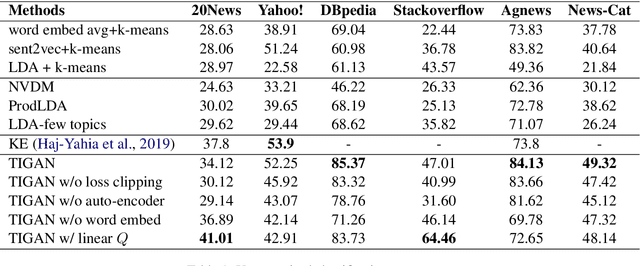
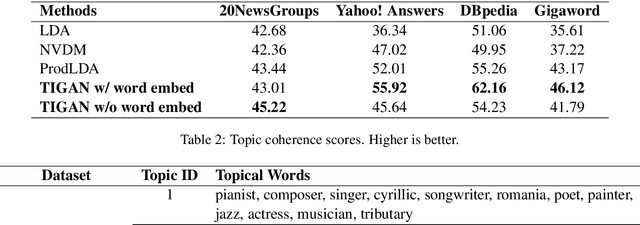

Learning continuous representations from unlabeled textual data has been increasingly studied for benefiting semi-supervised learning. Although it is relatively easier to interpret discrete representations, due to the difficulty of training, learning discrete representations for unlabeled textual data has not been widely explored. This work proposes TIGAN that learns to encode texts into two disentangled representations, including a discrete code and a continuous noise, where the discrete code represents interpretable topics, and the noise controls the variance within the topics. The discrete code learned by TIGAN can be used for unsupervised text classification. Compared to other unsupervised baselines, the proposed TIGAN achieves superior performance on six different corpora. Also, the performance is on par with a recently proposed weakly-supervised text classification method. The extracted topical words for representing latent topics show that TIGAN learns coherent and highly interpretable topics.
A Study of Cross-Lingual Ability and Language-specific Information in Multilingual BERT
Apr 20, 2020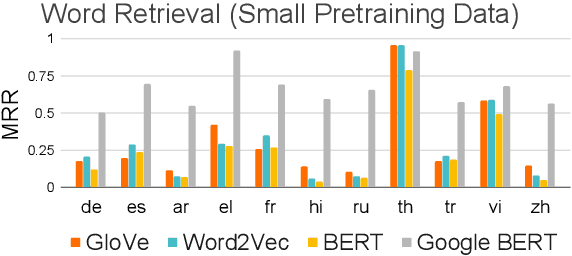

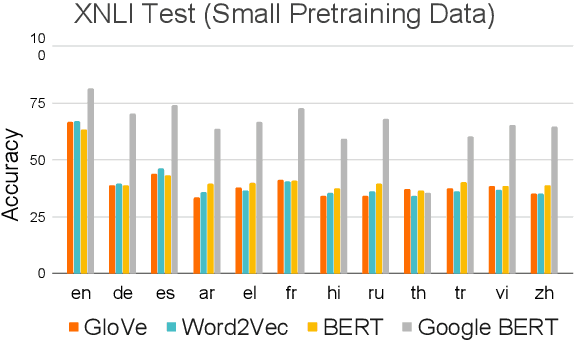
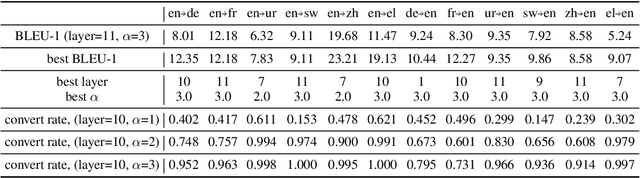
Recently, multilingual BERT works remarkably well on cross-lingual transfer tasks, superior to static non-contextualized word embeddings. In this work, we provide an in-depth experimental study to supplement the existing literature of cross-lingual ability. We compare the cross-lingual ability of non-contextualized and contextualized representation model with the same data. We found that datasize and context window size are crucial factors to the transferability. We also observe the language-specific information in multilingual BERT. By manipulating the latent representations, we can control the output languages of multilingual BERT, and achieve unsupervised token translation. We further show that based on the observation, there is a computationally cheap but effective approach to improve the cross-lingual ability of multilingual BERT.
Further Boosting BERT-based Models by Duplicating Existing Layers: Some Intriguing Phenomena inside BERT
Jan 25, 2020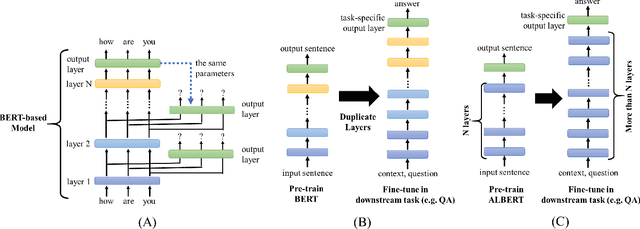
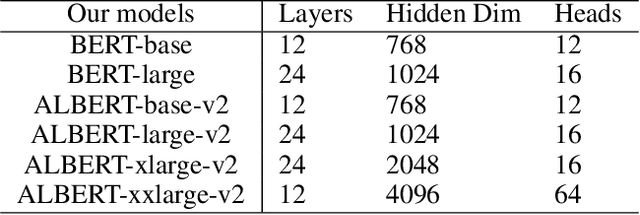
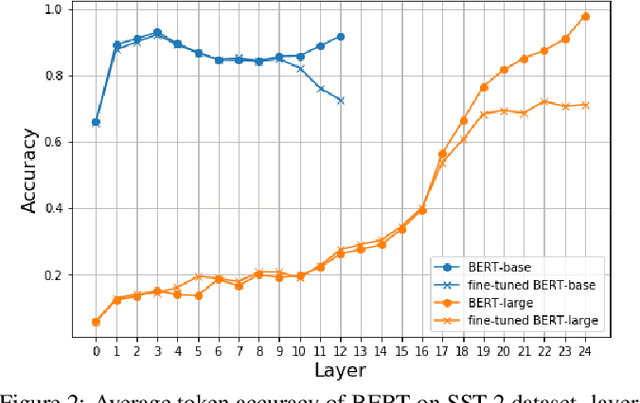
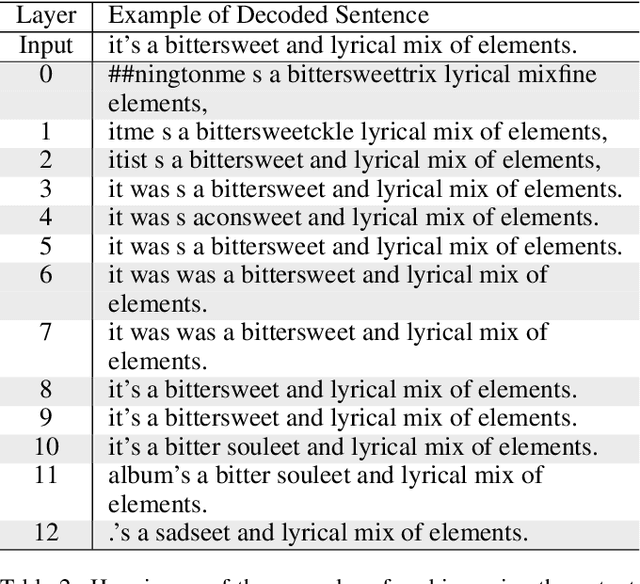
Although Bidirectional Encoder Representations from Transformers (BERT) have achieved tremendous success in many natural language processing (NLP) tasks, it remains a black box, so much previous work has tried to lift the veil of BERT and understand the functionality of each layer. In this paper, we found that removing or duplicating most layers in BERT would not change their outputs. This fact remains true across a wide variety of BERT-based models. Based on this observation, we propose a quite simple method to boost the performance of BERT. By duplicating some layers in the BERT-based models to make it deeper (no extra training required in this step), they obtain better performance in the down-stream tasks after fine-tuning.