 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Machine Learning for Cyberattack Identification from Traffic Flows
May 02, 2025The increasing automation of traffic management systems has made them prime targets for cyberattacks, disrupting urban mobility and public safety. Traditional network-layer defenses are often inaccessible to transportation agencies, necessitating a machine learning-based approach that relies solely on traffic flow data. In this study, we simulate cyberattacks in a semi-realistic environment, using a virtualized traffic network to analyze disruption patterns. We develop a deep learning-based anomaly detection system, demonstrating that Longest Stop Duration and Total Jam Distance are key indicators of compromised signals. To enhance interpretability, we apply Explainable AI (XAI) techniques, identifying critical decision factors and diagnosing misclassification errors. Our analysis reveals two primary challenges: transitional data inconsistencies, where mislabeled recovery-phase traffic misleads the model, and model limitations, where stealth attacks in low-traffic conditions evade detection. This work enhances AI-driven traffic security, improving both detection accuracy and trustworthiness in smart transportation systems.
Machine Learning for Cyber-Attack Identification from Traffic Flows
May 02, 2025This paper presents our simulation of cyber-attacks and detection strategies on the traffic control system in Daytona Beach, FL. using Raspberry Pi virtual machines and the OPNSense firewall, along with traffic dynamics from SUMO and exploitation via the Metasploit framework. We try to answer the research questions: are we able to identify cyber attacks by only analyzing traffic flow patterns. In this research, the cyber attacks are focused particularly when lights are randomly turned all green or red at busy intersections by adversarial attackers. Despite challenges stemming from imbalanced data and overlapping traffic patterns, our best model shows 85\% accuracy when detecting intrusions purely using traffic flow statistics. Key indicators for successful detection included occupancy, jam length, and halting durations.
A Comparative Study of Variational Autoencoders, Normalizing Flows, and Score-based Diffusion Models for Electrical Impedance Tomography
Oct 24, 2023Electrical Impedance Tomography (EIT) is a widely employed imaging technique in industrial inspection, geophysical prospecting, and medical imaging. However, the inherent nonlinearity and ill-posedness of EIT image reconstruction present challenges for classical regularization techniques, such as the critical selection of regularization terms and the lack of prior knowledge. Deep generative models (DGMs) have been shown to play a crucial role in learning implicit regularizers and prior knowledge. This study aims to investigate the potential of three DGMs-variational autoencoder networks, normalizing flow, and score-based diffusion model-to learn implicit regularizers in learning-based EIT imaging. We first introduce background information on EIT imaging and its inverse problem formulation. Next, we propose three algorithms for performing EIT inverse problems based on corresponding DGMs. Finally, we present numerical and visual experiments, which reveal that (1) no single method consistently outperforms the others across all settings, and (2) when reconstructing an object with 2 anomalies using a well-trained model based on a training dataset containing 4 anomalies, the conditional normalizing flow model (CNF) exhibits the best generalization in low-level noise, while the conditional score-based diffusion model (CSD*) demonstrates the best generalization in high-level noise settings. We hope our preliminary efforts will encourage other researchers to assess their DGMs in EIT and other nonlinear inverse problems.
Enhancing Electrical Impedance Tomography reconstruction using Learned Half-Quadratic Splitting Networks with Anderson Acceleration
Apr 16, 2023Electrical Impedance Tomography (EIT) is widely applied in medical diagnosis, industrial inspection, and environmental monitoring. Combining the physical principles of the imaging system with the advantages of data-driven deep learning networks, physics-embedded deep unrolling networks have recently emerged as a promising solution in computational imaging. However, the inherent nonlinear and ill-posed properties of EIT image reconstruction still present challenges to existing methods in terms of accuracy and stability. To tackle this challenge, we propose the learned half-quadratic splitting (HQSNet) algorithm for incorporating physics into learning-based EIT imaging. We then apply Anderson acceleration (AA) to the HQSNet algorithm, denoted as AA-HQSNet, which can be interpreted as AA applied to the Gauss-Newton step and the learned proximal gradient descent step of the HQSNet, respectively. AA is a widely-used technique for accelerating the convergence of fixed-point iterative algorithms and has gained significant interest in numerical optimization and machine learning. However, the technique has received little attention in the inverse problems community thus far. Employing AA enhances the convergence rate compared to the standard HQSNet while simultaneously avoiding artifacts in the reconstructions. Lastly, we conduct rigorous numerical and visual experiments to show that the AA module strengthens the HQSNet, leading to robust, accurate, and considerably superior reconstructions compared to state-of-the-art methods. Our Anderson acceleration scheme to enhance HQSNet is generic and can be applied to improve the performance of various physics-embedded deep learning methods.
WSSS4LUAD: Grand Challenge on Weakly-supervised Tissue Semantic Segmentation for Lung Adenocarcinoma
Apr 14, 2022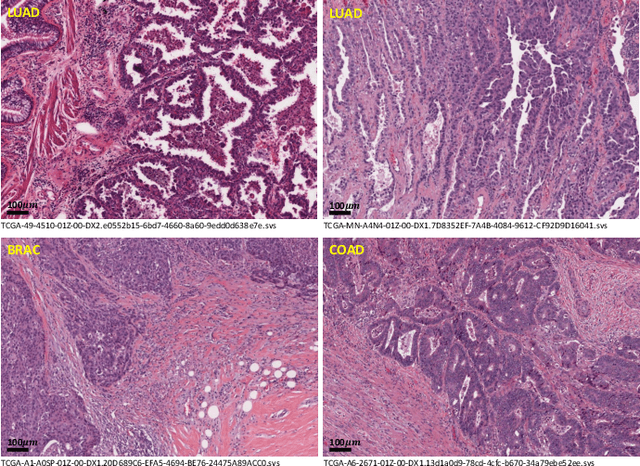
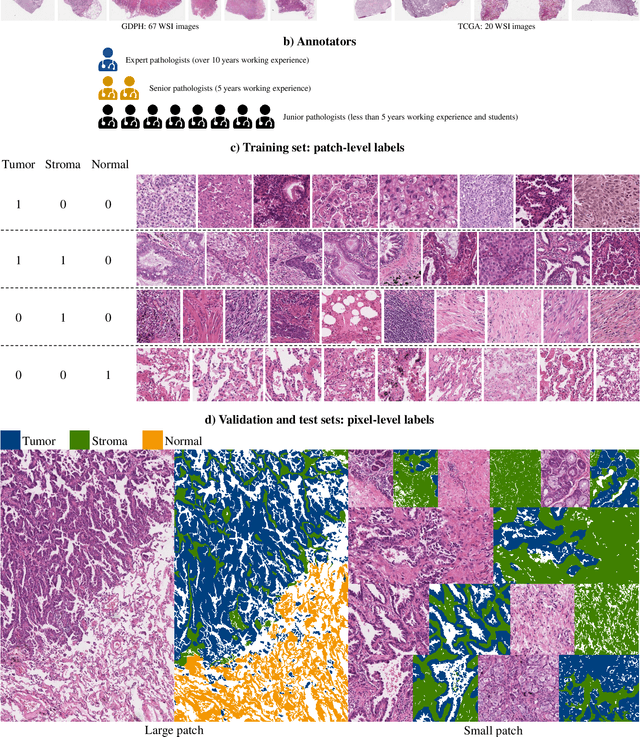
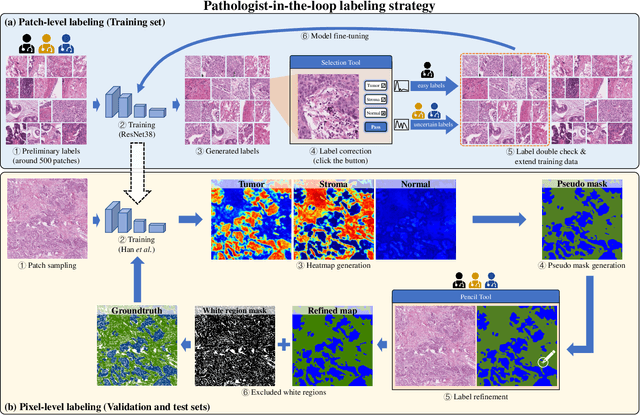
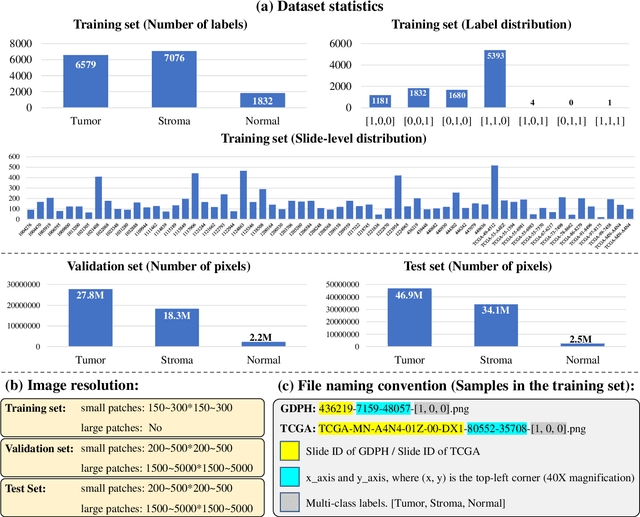
Lung cancer is the leading cause of cancer death worldwide, and adenocarcinoma (LUAD) is the most common subtype. Exploiting the potential value of the histopathology images can promote precision medicine in oncology. Tissue segmentation is the basic upstream task of histopathology image analysis. Existing deep learning models have achieved superior segmentation performance but require sufficient pixel-level annotations, which is time-consuming and expensive. To enrich the label resources of LUAD and to alleviate the annotation efforts, we organize this challenge WSSS4LUAD to call for the outstanding weakly-supervised semantic segmentation (WSSS) techniques for histopathology images of LUAD. Participants have to design the algorithm to segment tumor epithelial, tumor-associated stroma and normal tissue with only patch-level labels. This challenge includes 10,091 patch-level annotations (the training set) and over 130 million labeled pixels (the validation and test sets), from 87 WSIs (67 from GDPH, 20 from TCGA). All the labels were generated by a pathologist-in-the-loop pipeline with the help of AI models and checked by the label review board. Among 532 registrations, 28 teams submitted the results in the test phase with over 1,000 submissions. Finally, the first place team achieved mIoU of 0.8413 (tumor: 0.8389, stroma: 0.7931, normal: 0.8919). According to the technical reports of the top-tier teams, CAM is still the most popular approach in WSSS. Cutmix data augmentation has been widely adopted to generate more reliable samples. With the success of this challenge, we believe that WSSS approaches with patch-level annotations can be a complement to the traditional pixel annotations while reducing the annotation efforts. The entire dataset has been released to encourage more researches on computational pathology in LUAD and more novel WSSS techniques.
Online Attentive Kernel-Based Temporal Difference Learning
Jan 22, 2022



With rising uncertainty in the real world, online Reinforcement Learning (RL) has been receiving increasing attention due to its fast learning capability and improving data efficiency. However, online RL often suffers from complex Value Function Approximation (VFA) and catastrophic interference, creating difficulty for the deep neural network to be applied to an online RL algorithm in a fully online setting. Therefore, a simpler and more adaptive approach is introduced to evaluate value function with the kernel-based model. Sparse representations are superior at handling interference, indicating that competitive sparse representations should be learnable, non-prior, non-truncated and explicit when compared with current sparse representation methods. Moreover, in learning sparse representations, attention mechanisms are utilized to represent the degree of sparsification, and a smooth attentive function is introduced into the kernel-based VFA. In this paper, we propose an Online Attentive Kernel-Based Temporal Difference (OAKTD) algorithm using two-timescale optimization and provide convergence analysis of our proposed algorithm. Experimental evaluations showed that OAKTD outperformed several Online Kernel-based Temporal Difference (OKTD) learning algorithms in addition to the Temporal Difference (TD) learning algorithm with Tile Coding on public Mountain Car, Acrobot, CartPole and Puddle World tasks.
Neural network algorithm and its application in reactive distillation
Nov 16, 2020Reactive distillation is a special distillation technology based on the coupling of chemical reaction and distillation. It has the characteristics of low energy consumption and high separation efficiency. However, because the combination of reaction and separation produces highly nonlinear robust behavior, the control and optimization of the reactive distillation process cannot use conventional methods, but must rely on neural network algorithms. This paper briefly describes the characteristics and research progress of reactive distillation technology and neural network algorithms, and summarizes the application of neural network algorithms in reactive distillation, aiming to provide reference for the development and innovation of industry technology.