 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLNSpeech: solving extended speech separation problem by the help of sign language
Jul 21, 2020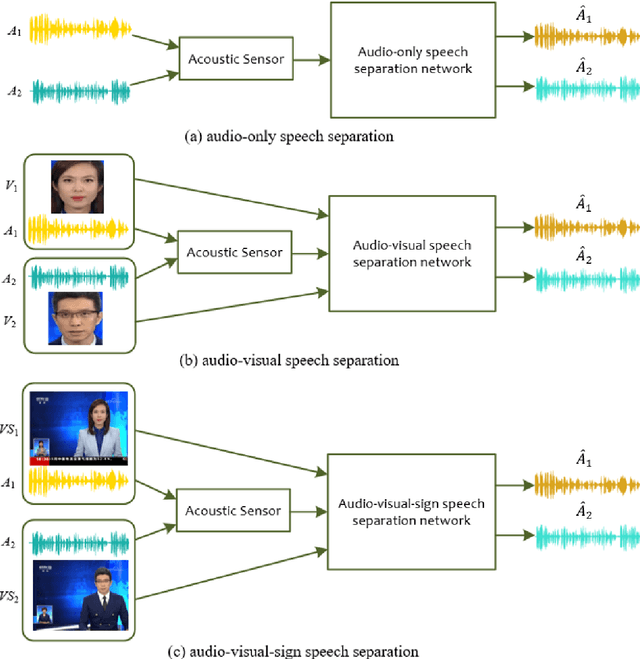


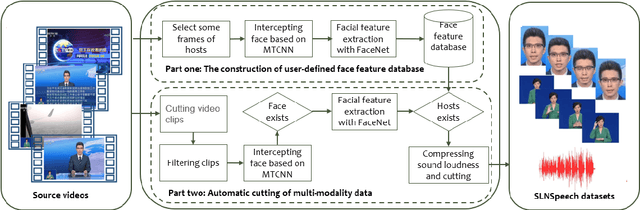
A speech separation task can be roughly divided into audio-only separation and audio-visual separation. In order to make speech separation technology applied in the real scenario of the disabled, this paper presents an extended speech separation problem which refers in particular to sign language assisted speech separation. However, most existing datasets for speech separation are audios and videos which contain audio and/or visual modalities. To address the extended speech separation problem, we introduce a large-scale dataset named Sign Language News Speech (SLNSpeech) dataset in which three modalities of audio, visual, and sign language are coexisted. Then, we design a general deep learning network for the self-supervised learning of three modalities, particularly, using sign language embeddings together with audio or audio-visual information for better solving the speech separation task. Specifically, we use 3D residual convolutional network to extract sign language features and use pretrained VGGNet model to exact visual features. After that, an improved U-Net with skip connections in feature extraction stage is applied for learning the embeddings among the mixed spectrogram transformed from source audios, the sign language features and visual features. Experiments results show that, besides visual modality, sign language modality can also be used alone to supervise speech separation task. Moreover, we also show the effectiveness of sign language assisted speech separation when the visual modality is disturbed. Source code will be released in http://cheertt.top/homepage/
Eikonal Region-based Active Contours for Image Segmentation
Dec 20, 2019
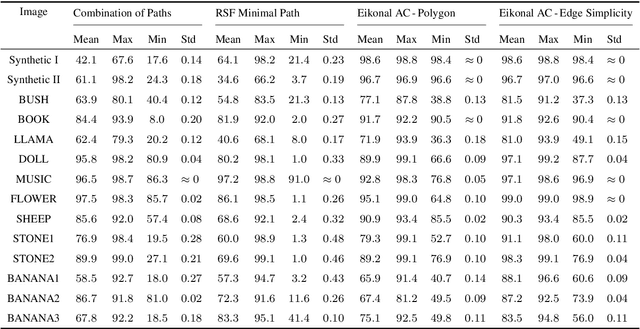
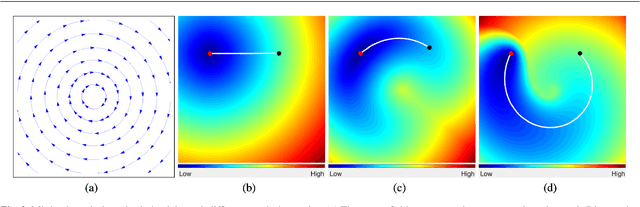

The minimal path model based on the Eikonal partial differential equation (PDE) has served as a fundamental tool for the applications of image segmentation and boundary detection in the passed three decades. However, the existing minimal paths-based image segmentation approaches commonly rely on the image boundary features, potentially limiting their performance in some situations. In this paper, we introduce a new variational image segmentation model based on the minimal path framework and the Eikonal PDE, where the region-based functional that defines the homogeneity criteria can be taken into account for estimating the associated geodesic paths. This is done by establishing a geodesic curve interpretation to the region-based active contour evolution problem. The image segmentation processing is carried out in an iterative manner in our approach. A crucial ingredient in each iteration is to construct an asymmetric Randers geodesic metric using a sufficiently small vector field, such that a set of geodesic paths can be tracked from the geodesic distance map which is the solution to an Eikonal PDE. The object boundary can be delineated by the concatenation of the final geodesic paths. We invoke the Finsler variant of the fast marching method to estimate the geodesic distance map, yielding an efficient implementation of the proposed Eikonal region-based active contour model. Experimental results on both of the synthetic and real images exhibit that our model indeed achieves encouraging segmentation performance.
Deep Octonion Networks
Mar 20, 2019
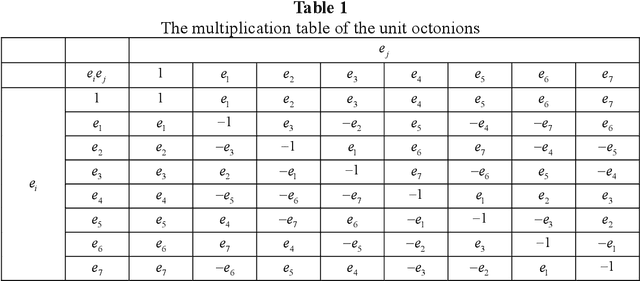
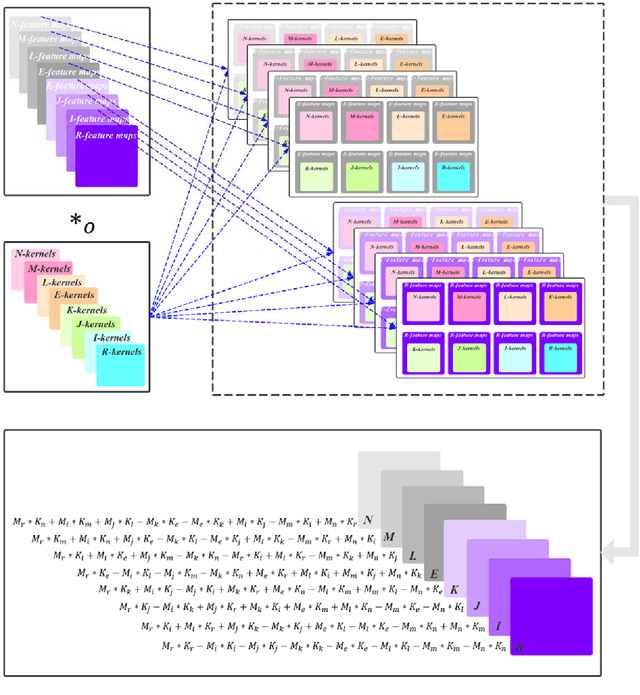
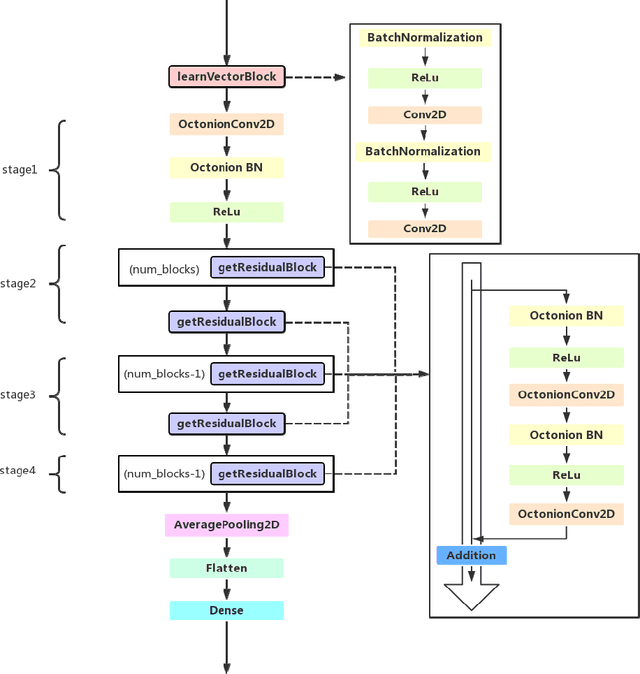
Deep learning is a research hot topic in the field of machine learning. Real-value neural networks (Real NNs), especially deep real networks (DRNs), have been widely used in many research fields. In recent years, the deep complex networks (DCNs) and the deep quaternion networks (DQNs) have attracted more and more attentions. The octonion algebra, which is an extension of complex algebra and quaternion algebra, can provide more efficient and compact expression. This paper constructs a general framework of deep octonion networks (DONs) and provides the main building blocks of DONs such as octonion convolution, octonion batch normalization and octonion weight initialization; DONs are then used in image classification tasks for CIFAR-10 and CIFAR-100 data sets. Compared with the DRNs, the DCNs, and the DQNs, the proposed DONs have better convergence and higher classification accuracy. The success of DONs is also explained by multi-task learning.
Compressing complex convolutional neural network based on an improved deep compression algorithm
Mar 06, 2019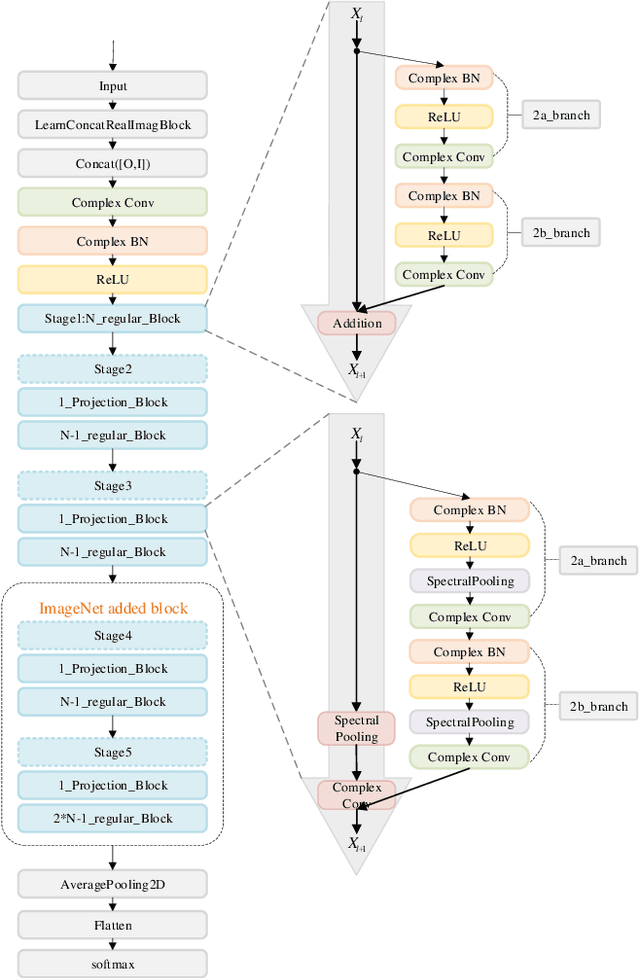
Although convolutional neural network (CNN) has made great progress, large redundant parameters restrict its deployment on embedded devices, especially mobile devices. The recent compression works are focused on real-value convolutional neural network (Real CNN), however, to our knowledge, there is no attempt for the compression of complex-value convolutional neural network (Complex CNN). Compared with the real-valued network, the complex-value neural network is easier to optimize, generalize, and has better learning potential. This paper extends the commonly used deep compression algorithm from real domain to complex domain and proposes an improved deep compression algorithm for the compression of Complex CNN. The proposed algorithm compresses the network about 8 times on CIFAR-10 dataset with less than 3% accuracy loss. On the ImageNet dataset, our method compresses the model about 16 times and the accuracy loss is about 2% without retraining.
Fractional spectral graph wavelets and their applications
Feb 27, 2019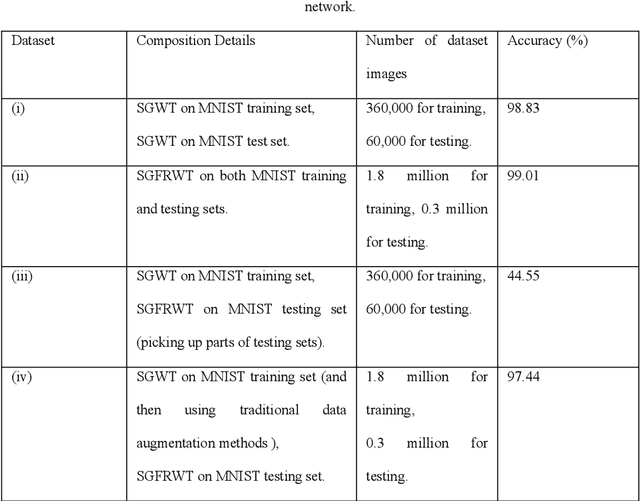
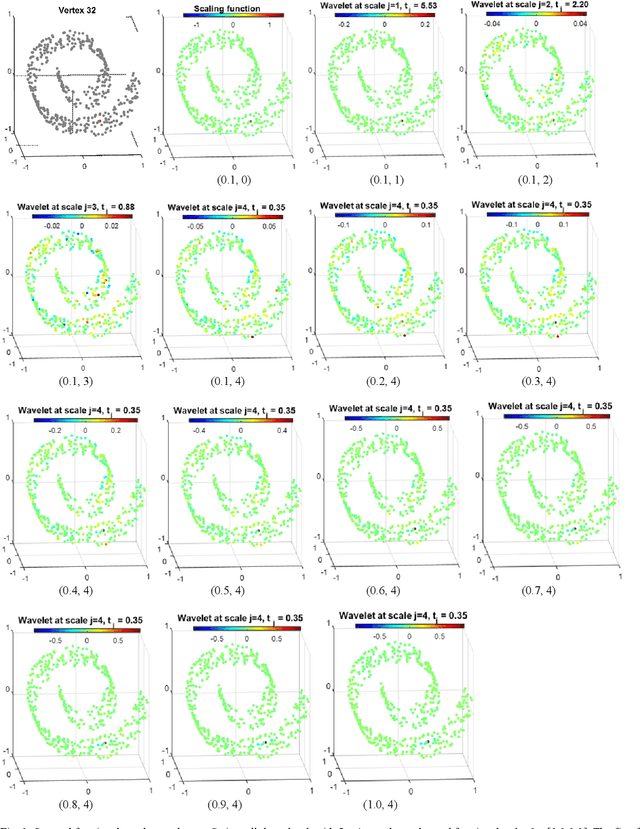


One of the key challenges in the area of signal processing on graphs is to design transforms and dictionaries methods to identify and exploit structure in signals on weighted graphs. In this paper, we first generalize graph Fourier transform (GFT) to graph fractional Fourier transform (GFRFT), which is then used to define a novel transform named spectral graph fractional wavelet transform (SGFRWT), which is a generalized and extended version of spectral graph wavelet transform (SGWT). A fast algorithm for SGFRWT is also derived and implemented based on Fourier series approximation. The potential applications of SGFRWT are also presented.
Modulated binary cliquenet
Feb 27, 2019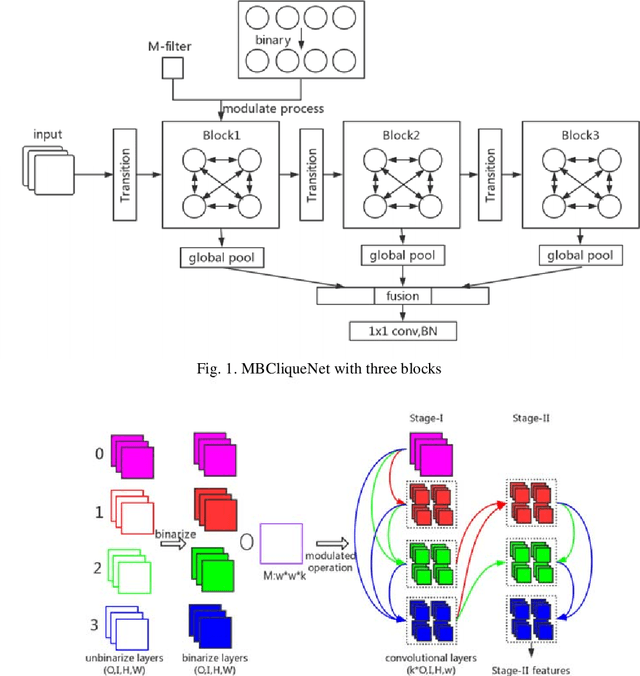

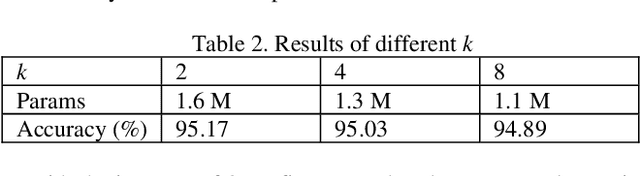
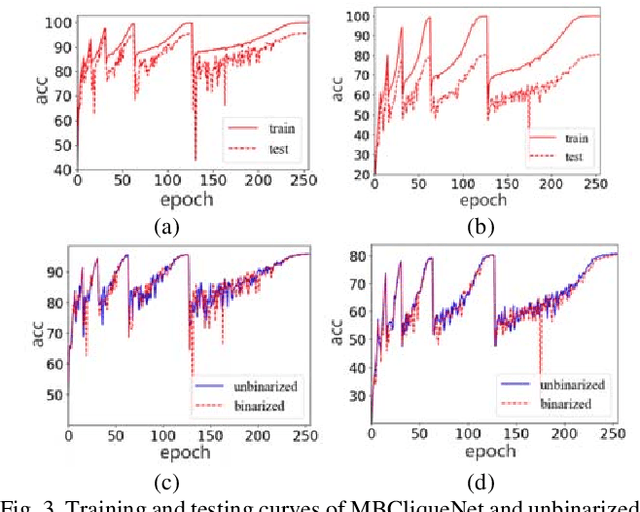
Although Convolutional Neural Networks (CNNs) achieve effectiveness in various computer vision tasks, the significant requirement of storage of such networks hinders the deployment on computationally limited devices. In this paper, we propose a new compact and portable deep learning network named Modulated Binary Cliquenet (MBCliqueNet) aiming to improve the portability of CNNs based on binarized filters while achieving comparable performance with the full-precision CNNs like Resnet. In MBCliqueNet, we introduce a novel modulated operation to approximate the unbinarized filters and gives an initialization method to speed up its convergence. We reduce the extra parameters caused by modulated operation with parameters sharing. As a result, the proposed MBCliqueNet can reduce the required storage space of convolutional filters by a factor of at least 32, in contrast to the full-precision model, and achieve better performance than other state-of-the-art binarized models. More importantly, our model compares even better with some full-precision models like Resnet on the dataset we used.
Robust low-rank multilinear tensor approximation for a joint estimation of the multilinear rank and the loading matrices
Nov 30, 2018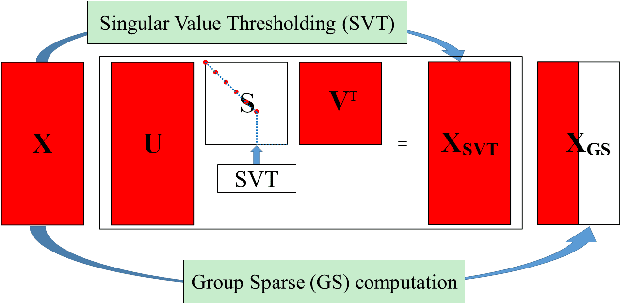
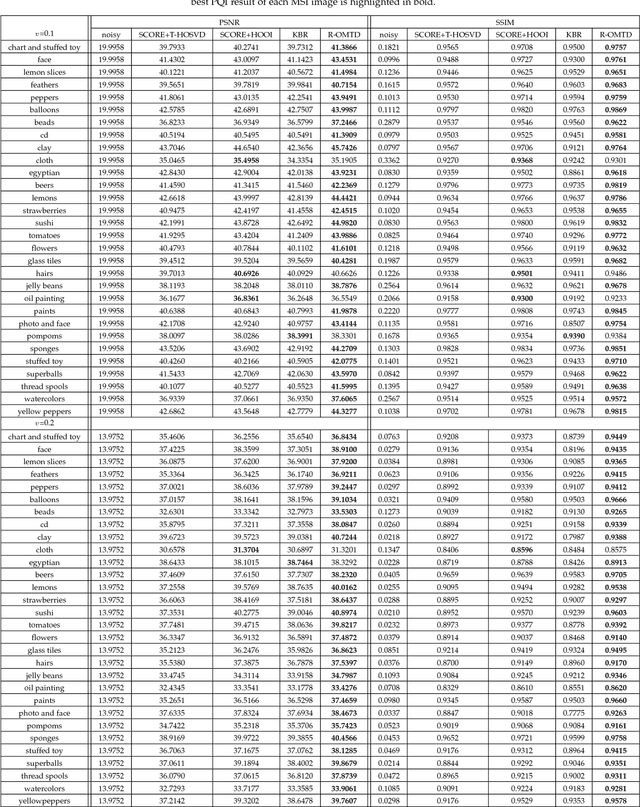
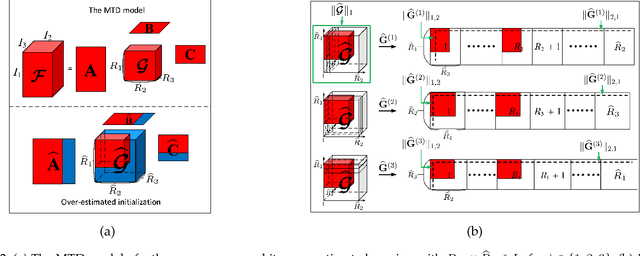
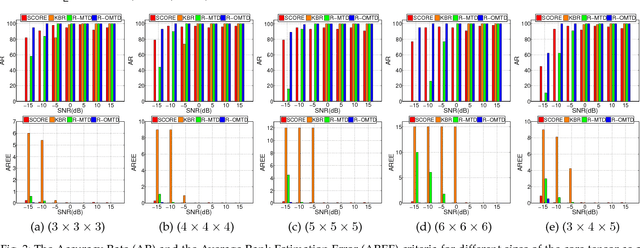
In order to compute the best low-rank tensor approximation using the Multilinear Tensor Decomposition (MTD) model, it is essential to estimate the rank of the underlying multilinear tensor from the noisy observation tensor. In this paper, we propose a Robust MTD (R-MTD) method, which jointly estimates the multilinear rank and the loading matrices. Based on the low-rank property and an over-estimation of the core tensor, this joint estimation problem is solved by promoting (group) sparsity of the over-estimated core tensor. Group sparsity is promoted using mixed-norms. Then we establish a link between the mixed-norms and the nuclear norm, showing that mixed-norms are better candidates for a convex envelope of the rank. After several iterations of the Alternating Direction Method of Multipliers (ADMM), the Minimum Description Length (MDL) criterion computed from the eigenvalues of the unfolding matrices of the estimated core tensor is minimized in order to estimate the multilinear rank. The latter is then used to estimate more accurately the loading matrices. We further develop another R-MTD method, called R-OMTD, by imposing an orthonormality constraint on each loading matrix in order to decrease the computation complexity. A series of simulated noisy tensor and real-world data are used to show the effectiveness of the proposed methods compared with state-of-the-art methods.
Fractional Wavelet Scattering Network and Applications
Jun 30, 2018
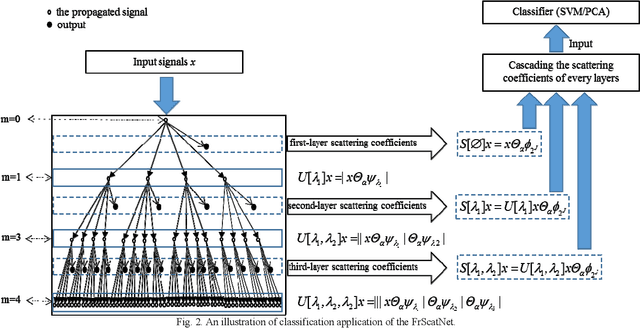
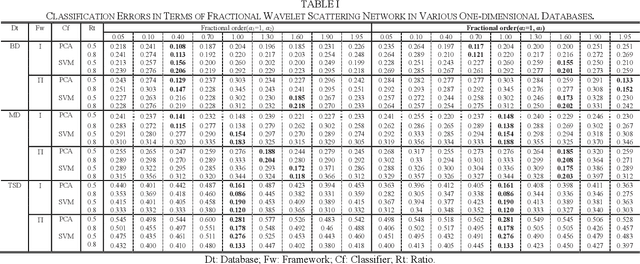
Objective: The present study introduces a fractional wavelet scattering network (FrScatNet), which is a generalized translation invariant version of the classical wavelet scattering network (ScatNet). Methods: In our approach, the FrScatNet is constructed based on the fractional wavelet transform (FRWT). The fractional scattering coefficients are iteratively computed using FRWTs and modulus operators. The feature vectors constructed by fractional scattering coefficients are usually used for signal classification. In this work, an application example of FrScatNet is provided in order to assess its performance on pathological images. Firstly, the FrScatNet extracts feature vectors from patches of the original histological images under different orders. Then we classify those patches into target (benign or malignant) and background groups. And the FrScatNet property is analyzed by comparing error rates computed from different fractional orders respectively. Based on the above pathological image classification, a gland segmentation algorithm is proposed by combining the boundary information and the gland location. Results: The error rates for different fractional orders of FrScatNet are examined and show that the classification accuracy is significantly improved in fractional scattering domain. We also compare the FrScatNet based gland segmentation method with those proposed in the 2015 MICCAI Gland Segmentation Challenge and our method achieves comparable results. Conclusion: The FrScatNet is shown to achieve accurate and robust results. More stable and discriminative fractional scattering coefficients are obtained by the FrScatNet in this work. Significance: The added fractional order parameter is able to analyze the image in the fractional scattering domain.
MomentsNet: a simple learning-free method for binary image recognition
Feb 22, 2017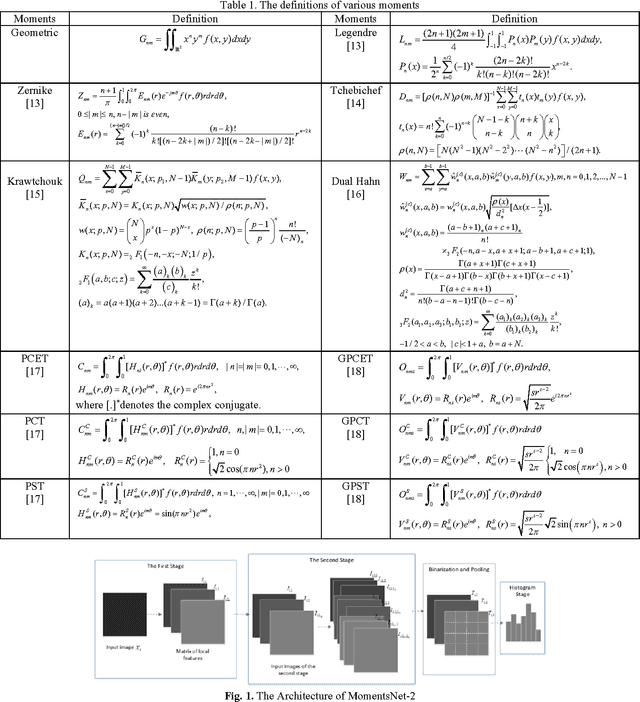

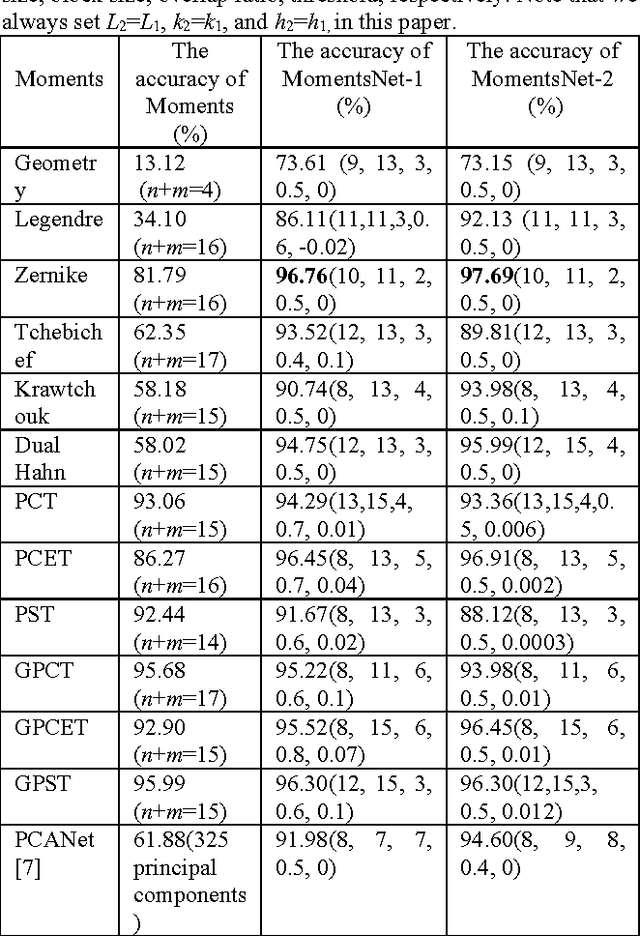
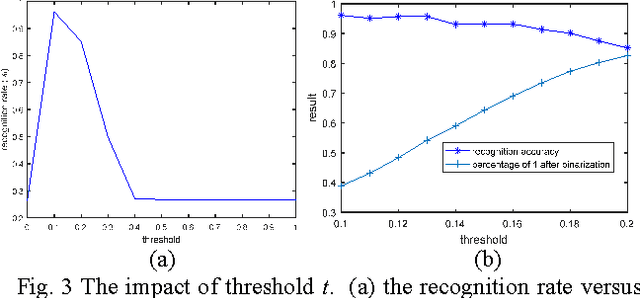
In this paper, we propose a new simple and learning-free deep learning network named MomentsNet, whose convolution layer, nonlinear processing layer and pooling layer are constructed by Moments kernels, binary hashing and block-wise histogram, respectively. Twelve typical moments (including geometrical moment, Zernike moment, Tchebichef moment, etc.) are used to construct the MomentsNet whose recognition performance for binary image is studied. The results reveal that MomentsNet has better recognition performance than its corresponding moments in almost all cases and ZernikeNet achieves the best recognition performance among MomentsNet constructed by twelve moments. ZernikeNet also shows better recognition performance on binary image database than that of PCANet, which is a learning-based deep learning network.
Heart Rate Variability and Respiration Signal as Diagnostic Tools for Late Onset Sepsis in Neonatal Intensive Care Units
May 12, 2016

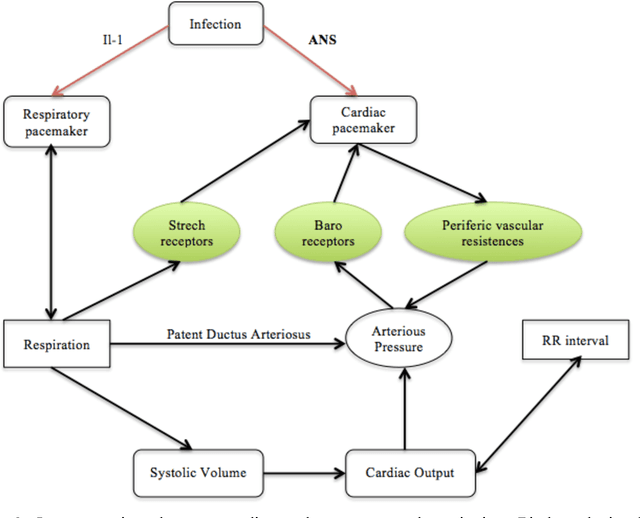

Apnea-bradycardia is one of the major clinical early indicators of late-onset sepsis occurring in approximately 7% to 10% of all neonates and in more than 25% of very low birth weight infants in NICU. The objective of this paper was to determine if HRV, respiration and their relationships help to diagnose infection in premature infants via non-invasive ways in NICU. Therefore, we implement Mono-Channel (MC) and Bi-Channel (BC) Analysis in two groups: sepsis (S) vs. non-sepsis (NS). Firstly, we studied RR series not only by linear methods: time domain and frequency domain, but also by non-linear methods: chaos theory and information theory. The results show that alpha Slow, alpha Fast and Sample Entropy are significant parameters to distinguish S from NS. Secondly, the question about the functional coupling of HRV and nasal respiration is addressed. Local linear correlation coefficient r2t,f has been explored, while non-linear regression coefficient h2 was calculated in two directions. It is obvious that r2t,f within the third frequency band (0.2<f<0.4 Hz) and h2 in two directions were complementary approaches to diagnose sepsis. Thirdly, feasibility study is carried out on the candidate parameters selected from MC and BC respectively. We discovered that the proposed test based on optimal fusion of 6 features shows good performance with the largest AUC and a reduced probability of false alarm (PFA).