 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Cannulation of Femoral Vessels in a Porcine Shock Model
Jun 17, 2025Rapid and reliable vascular access is critical in trauma and critical care. Central vascular catheterization enables high-volume resuscitation, hemodynamic monitoring, and advanced interventions like ECMO and REBOA. While peripheral access is common, central access is often necessary but requires specialized ultrasound-guided skills, posing challenges in prehospital settings. The complexity arises from deep target vessels and the precision needed for needle placement. Traditional techniques, like the Seldinger method, demand expertise to avoid complications. Despite its importance, ultrasound-guided central access is underutilized due to limited field expertise. While autonomous needle insertion has been explored for peripheral vessels, only semi-autonomous methods exist for femoral access. This work advances toward full automation, integrating robotic ultrasound for minimally invasive emergency procedures. Our key contribution is the successful femoral vein and artery cannulation in a porcine hemorrhagic shock model.
* 2 pages, 2 figures, conference
A Complete and Bounded-Suboptimal Algorithm for a Moving Target Traveling Salesman Problem with Obstacles in 3D
Apr 20, 2025The moving target traveling salesman problem with obstacles (MT-TSP-O) seeks an obstacle-free trajectory for an agent that intercepts a given set of moving targets, each within specified time windows, and returns to the agent's starting position. Each target moves with a constant velocity within its time windows, and the agent has a speed limit no smaller than any target's speed. We present FMC*-TSP, the first complete and bounded-suboptimal algorithm for the MT-TSP-O, and results for an agent whose configuration space is $\mathbb{R}^3$. Our algorithm interleaves a high-level search and a low-level search, where the high-level search solves a generalized traveling salesman problem with time windows (GTSP-TW) to find a sequence of targets and corresponding time windows for the agent to visit. Given such a sequence, the low-level search then finds an associated agent trajectory. To solve the low-level planning problem, we develop a new algorithm called FMC*, which finds a shortest path on a graph of convex sets (GCS) via implicit graph search and pruning techniques specialized for problems with moving targets. We test FMC*-TSP on 280 problem instances with up to 40 targets and demonstrate its smaller median runtime than a baseline based on prior work.
Multi-Agent Ergodic Exploration under Smoke-Based, Time-Varying Sensor Visibility Constraints
Mar 06, 2025



In this work, we consider the problem of multi-agent informative path planning (IPP) for robots whose sensor visibility continuously changes as a consequence of a time-varying natural phenomenon. We leverage ergodic trajectory optimization (ETO), which generates paths such that the amount of time an agent spends in an area is proportional to the expected information in that area. We focus specifically on the problem of multi-agent drone search of a wildfire, where we use the time-varying environmental process of smoke diffusion to construct a sensor visibility model. This sensor visibility model is used to repeatedly calculate an expected information distribution (EID) to be used in the ETO algorithm. Our experiments show that our exploration method achieves improved information gathering over both baseline search methods and naive ergodic search formulations.
Ergodic Exploration over Meshable Surfaces
Mar 06, 2025



Robotic search and rescue, exploration, and inspection require trajectory planning across a variety of domains. A popular approach to trajectory planning for these types of missions is ergodic search, which biases a trajectory to spend time in parts of the exploration domain that are believed to contain more information. Most prior work on ergodic search has been limited to searching simple surfaces, like a 2D Euclidean plane or a sphere, as they rely on projecting functions defined on the exploration domain onto analytically obtained Fourier basis functions. In this paper, we extend ergodic search to any surface that can be approximated by a triangle mesh. The basis functions are approximated through finite element methods on a triangle mesh of the domain. We formally prove that this approximation converges to the continuous case as the mesh approximation converges to the true domain. We demonstrate that on domains where analytical basis functions are available (plane, sphere), the proposed method obtains equivalent results, and while on other domains (torus, bunny, wind turbine), the approach is versatile enough to still search effectively. Lastly, we also compare with an existing ergodic search technique that can handle complex domains and show that our method results in a higher quality exploration.
A Mixed-Integer Conic Program for the Multi-Agent Moving-Target Traveling Salesman Problem
Jan 10, 2025The Moving-Target Traveling Salesman Problem (MT-TSP) aims to find a shortest path for an agent that starts at a stationary depot, visits a set of moving targets exactly once, each within one of their respective time windows, and then returns to the depot. In this paper, we introduce a new Mixed-Integer Conic Program (MICP) formulation that finds the optimum for the Multi-Agent Moving-Target Traveling Salesman Problem (MA-MT-TSP), a generalization of the MT-TSP involving multiple agents. We obtain our formulation by first restating the current state-of-the-art MICP formulation for MA-MT-TSP as a Mixed-Integer Nonlinear Nonconvex Program, and then reformulating it as a new MICP. We present computational results to demonstrate the performance of our approach. The results show that our formulation significantly outperforms the state-of-the-art, with up to a two-order-of-magnitude reduction in runtime, and up to over 90% tighter optimality gap.
Implicit Graph Search for Planning on Graphs of Convex Sets
Oct 11, 2024



Graphs of Convex Sets (GCS) is a recent method for synthesizing smooth trajectories by decomposing the planning space into convex sets, forming a graph to encode the adjacency relationships within the decomposition, and then simultaneously searching this graph and optimizing parts of the trajectory to obtain the final trajectory. To do this, one must solve a Mixed Integer Convex Program (MICP) and to mitigate computational time, GCS proposes a convex relaxation that is empirically very tight. Despite this tight relaxation, motion planning with GCS for real-world robotics problems translates to solving the simultaneous batch optimization problem that may contain millions of constraints and therefore can be slow. This is further exacerbated by the fact that the size of the GCS problem is invariant to the planning query. Motivated by the observation that the trajectory solution lies only on a fraction of the set of convex sets, we present two implicit graph search methods for planning on the graph of convex sets called INSATxGCS (IxG) and IxG*. INterleaved Search And Trajectory optimization (INSAT) is a previously developed algorithm that alternates between searching on a graph and optimizing partial paths to find a smooth trajectory. By using an implicit graph search method INSAT on the graph of convex sets, we achieve faster planning while ensuring stronger guarantees on completeness and optimality. Moveover, introducing a search-based technique to plan on the graph of convex sets enables us to easily leverage well-established techniques such as search parallelization, lazy planning, anytime planning, and replanning as future work. Numerical comparisons against GCS demonstrate the superiority of IxG across several applications, including planning for an 18-degree-of-freedom multi-arm assembly scenario.
LiPO: LiDAR Inertial Odometry for ICP Comparison
Oct 10, 2024



We introduce a LiDAR inertial odometry (LIO) framework, called LiPO, that enables direct comparisons of different iterative closest point (ICP) point cloud registration methods. The two common ICP methods we compare are point-to-point (P2P) and point-to-feature (P2F). In our experience, within the context of LIO, P2F-ICP results in less drift and improved mapping accuracy when robots move aggressively through challenging environments when compared to P2P-ICP. However, P2F-ICP methods require more hand-tuned hyper-parameters that make P2F-ICP less general across all environments and motions. In real-world field robotics applications where robots are used across different environments, more general P2P-ICP methods may be preferred despite increased drift. In this paper, we seek to better quantify the trade-off between P2P-ICP and P2F-ICP to help inform when each method should be used. To explore this trade-off, we use LiPO to directly compare ICP methods and test on relevant benchmark datasets as well as on our custom unpiloted ground vehicle (UGV). We find that overall, P2F-ICP has reduced drift and improved mapping accuracy, but, P2P-ICP is more consistent across all environments and motions with minimal drift increase.
A Complete Algorithm for a Moving Target Traveling Salesman Problem with Obstacles
Sep 15, 2024



The moving target traveling salesman problem with obstacles (MT-TSP-O) is a generalization of the traveling salesman problem (TSP) where, as its name suggests, the targets are moving. A solution to the MT-TSP-O is a trajectory that visits each moving target during a certain time window(s), and this trajectory avoids stationary obstacles. We assume each target moves at a constant velocity during each of its time windows. The agent has a speed limit, and this speed limit is no smaller than any target's speed. This paper presents the first complete algorithm for finding feasible solutions to the MT-TSP-O. Our algorithm builds a tree where the nodes are agent trajectories intercepting a unique sequence of targets within a unique sequence of time windows. We generate each of a parent node's children by extending the parent's trajectory to intercept one additional target, each child corresponding to a different choice of target and time window. This extension consists of planning a trajectory from the parent trajectory's final point in space-time to a moving target. To solve this point-to-moving-target subproblem, we define a novel generalization of a visibility graph called a moving target visibility graph (MTVG). Our overall algorithm is called MTVG-TSP. To validate MTVG-TSP, we test it on 570 instances with up to 30 targets. We implement a baseline method that samples trajectories of targets into points, based on prior work on special cases of the MT-TSP-O. MTVG-TSP finds feasible solutions in all cases where the baseline does, and when the sum of the targets' time window lengths enters a critical range, MTVG-TSP finds a feasible solution with up to 38 times less computation time.
Measure Preserving Flows for Ergodic Search in Convoluted Environments
Sep 13, 2024
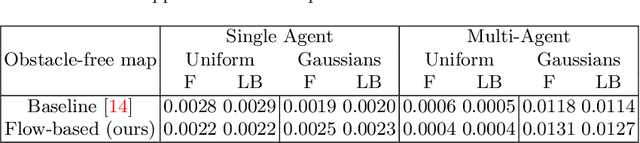
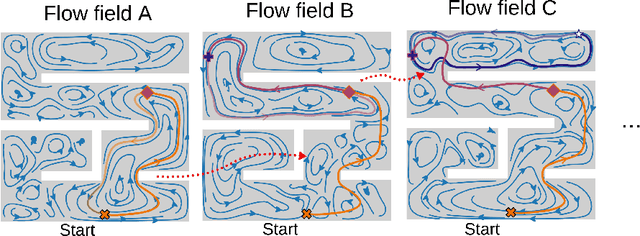
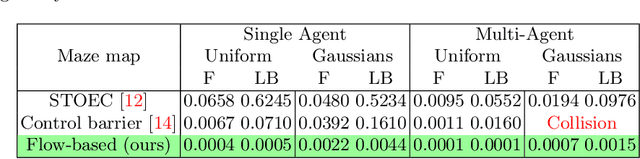
Autonomous robotic search has important applications in robotics, such as the search for signs of life after a disaster. When \emph{a priori} information is available, for example in the form of a distribution, a planner can use that distribution to guide the search. Ergodic search is one method that uses the information distribution to generate a trajectory that minimizes the ergodic metric, in that it encourages the robot to spend more time in regions with high information and proportionally less time in the remaining regions. Unfortunately, prior works in ergodic search do not perform well in complex environments with obstacles such as a building's interior or a maze. To address this, our work presents a modified ergodic metric using the Laplace-Beltrami eigenfunctions to capture map geometry and obstacle locations within the ergodic metric. Further, we introduce an approach to generate trajectories that minimize the ergodic metric while guaranteeing obstacle avoidance using measure-preserving vector fields. Finally, we leverage the divergence-free nature of these vector fields to generate collision-free trajectories for multiple agents. We demonstrate our approach via simulations with single and multi-agent systems on maps representing interior hallways and long corridors with non-uniform information distribution. In particular, we illustrate the generation of feasible trajectories in complex environments where prior methods fail.
Assigning Credit with Partial Reward Decoupling in Multi-Agent Proximal Policy Optimization
Aug 08, 2024Multi-agent proximal policy optimization (MAPPO) has recently demonstrated state-of-the-art performance on challenging multi-agent reinforcement learning tasks. However, MAPPO still struggles with the credit assignment problem, wherein the sheer difficulty in ascribing credit to individual agents' actions scales poorly with team size. In this paper, we propose a multi-agent reinforcement learning algorithm that adapts recent developments in credit assignment to improve upon MAPPO. Our approach leverages partial reward decoupling (PRD), which uses a learned attention mechanism to estimate which of a particular agent's teammates are relevant to its learning updates. We use this estimate to dynamically decompose large groups of agents into smaller, more manageable subgroups. We empirically demonstrate that our approach, PRD-MAPPO, decouples agents from teammates that do not influence their expected future reward, thereby streamlining credit assignment. We additionally show that PRD-MAPPO yields significantly higher data efficiency and asymptotic performance compared to both MAPPO and other state-of-the-art methods across several multi-agent tasks, including StarCraft II. Finally, we propose a version of PRD-MAPPO that is applicable to \textit{shared} reward settings, where PRD was previously not applicable, and empirically show that this also leads to performance improvements over MAPPO.