 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaptioning Daily Activity Images in Early Childhood Education: Benchmark and Algorithm
Apr 02, 2026Image captioning for Early Childhood Education (ECE) is essential for automated activity understanding and educational assessment. However, existing methods face two key challenges. First, the lack of large-scale, domain-specific datasets limits the model's ability to capture fine-grained semantic concepts unique to ECE scenarios, resulting in generic and imprecise descriptions. Second, conventional training paradigms exhibit limitations in enhancing professional object description capability, as supervised learning tends to favor high-frequency expressions, while reinforcement learning may suffer from unstable optimization on difficult samples. To address these limitations, we introduce ECAC, a large-scale benchmark for ECE daily activity image captioning, comprising 256,121 real-world images annotated with expert-level captions and fine-grained labels. ECAC is further equipped with a domain-oriented evaluation protocol, the Teaching Toy Recognition Score (TTS), to explicitly measure professional object naming accuracy. Furthermore, we propose RSRS (Reward-Conditional Switch of Reinforcement Learning and Supervised Fine-Tuning), a hybrid training framework that dynamically alternates between RL and supervised optimization. By rerouting hard samples with zero rewards to supervised fine-tuning, RSRS effectively mitigates advantage collapse and enables stable optimization for fine-grained recognition. Leveraging ECAC and RSRS, we develop KinderMM-Cap-3B, a domain-adapted multimodal large language model. Extensive experiments demonstrate that our model achieves a TTS of 51.06, substantially outperforming state-of-the-art baselines while maintaining superior caption quality, highlighting its potential for specialized educational applications.
Technique Report of CVPR 2024 PBDL Challenges
Jun 15, 2024



The intersection of physics-based vision and deep learning presents an exciting frontier for advancing computer vision technologies. By leveraging the principles of physics to inform and enhance deep learning models, we can develop more robust and accurate vision systems. Physics-based vision aims to invert the processes to recover scene properties such as shape, reflectance, light distribution, and medium properties from images. In recent years, deep learning has shown promising improvements for various vision tasks, and when combined with physics-based vision, these approaches can enhance the robustness and accuracy of vision systems. This technical report summarizes the outcomes of the Physics-Based Vision Meets Deep Learning (PBDL) 2024 challenge, held in CVPR 2024 workshop. The challenge consisted of eight tracks, focusing on Low-Light Enhancement and Detection as well as High Dynamic Range (HDR) Imaging. This report details the objectives, methodologies, and results of each track, highlighting the top-performing solutions and their innovative approaches.
Toward Minimal Misalignment at Minimal Cost in One-Stage and Anchor-Free Object Detection
Dec 22, 2021
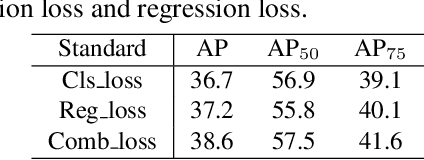
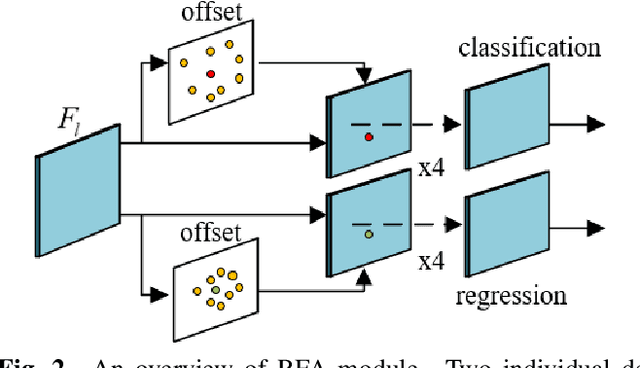
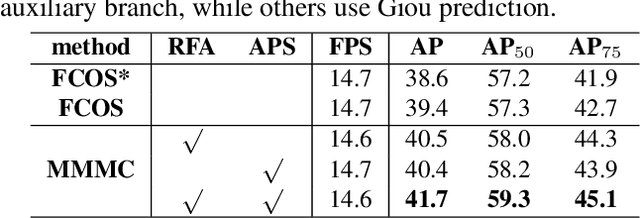
Common object detection models consist of classification and regression branches, due to different task drivers, these two branches have different sensibility to the features from the same scale level and the same spatial location. The point-based prediction method, which is based on the assumption that the high classification confidence point has the high regression quality, leads to the misalignment problem. Our analysis shows, the problem is further composed of scale misalignment and spatial misalignment specifically. We aim to resolve the phenomenon at minimal cost: a minor adjustment of the head network and a new label assignment method replacing the rigid one. Our experiments show that, compared to the baseline FCOS, a one-stage and anchor-free object detection model, our model consistently get around 3 AP improvement with different backbones, demonstrating both simplicity and efficiency of our method.
Supporting Regularized Logistic Regression Privately and Efficiently
Oct 01, 2015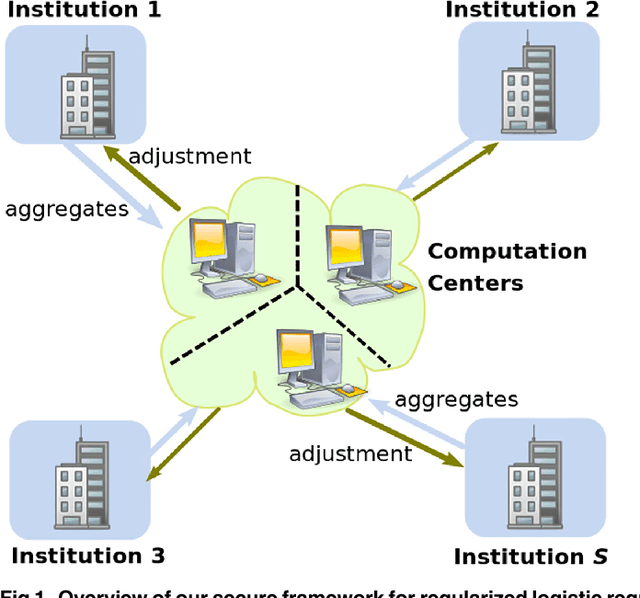
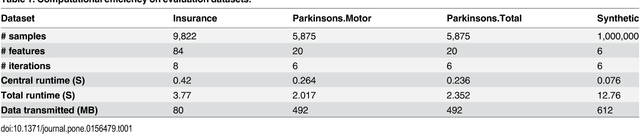
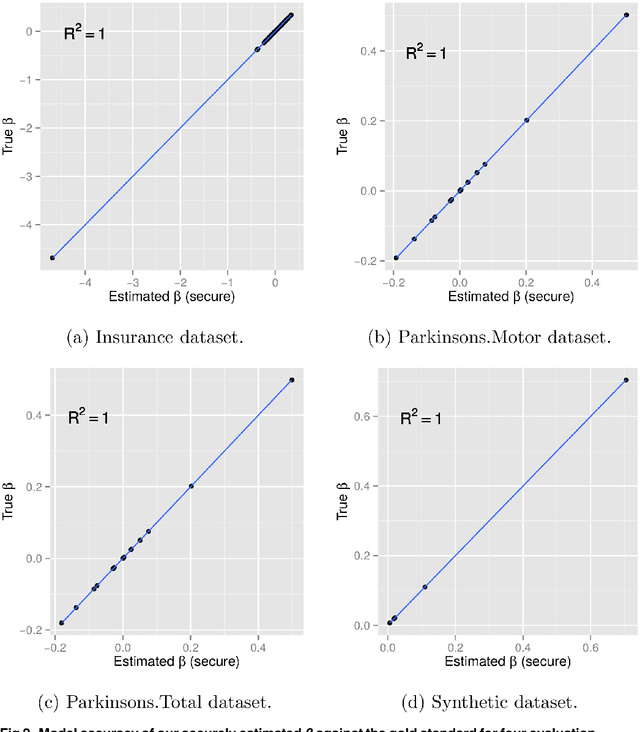
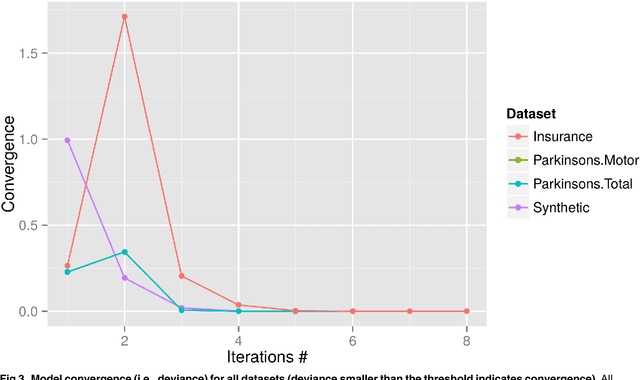
As one of the most popular statistical and machine learning models, logistic regression with regularization has found wide adoption in biomedicine, social sciences, information technology, and so on. These domains often involve data of human subjects that are contingent upon strict privacy regulations. Increasing concerns over data privacy make it more and more difficult to coordinate and conduct large-scale collaborative studies, which typically rely on cross-institution data sharing and joint analysis. Our work here focuses on safeguarding regularized logistic regression, a widely-used machine learning model in various disciplines while at the same time has not been investigated from a data security and privacy perspective. We consider a common use scenario of multi-institution collaborative studies, such as in the form of research consortia or networks as widely seen in genetics, epidemiology, social sciences, etc. To make our privacy-enhancing solution practical, we demonstrate a non-conventional and computationally efficient method leveraging distributing computing and strong cryptography to provide comprehensive protection over individual-level and summary data. Extensive empirical evaluation on several studies validated the privacy guarantees, efficiency and scalability of our proposal. We also discuss the practical implications of our solution for large-scale studies and applications from various disciplines, including genetic and biomedical studies, smart grid, network analysis, etc.