 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Parameterized Task Structure for Generalization to Unseen Entities
Mar 28, 2022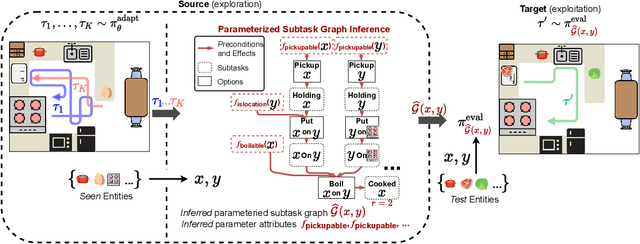


Real world tasks are hierarchical and compositional. Tasks can be composed of multiple subtasks (or sub-goals) that are dependent on each other. These subtasks are defined in terms of entities (e.g., "apple", "pear") that can be recombined to form new subtasks (e.g., "pickup apple", and "pickup pear"). To solve these tasks efficiently, an agent must infer subtask dependencies (e.g. an agent must execute "pickup apple" before "place apple in pot"), and generalize the inferred dependencies to new subtasks (e.g. "place apple in pot" is similar to "place apple in pan"). Moreover, an agent may also need to solve unseen tasks, which can involve unseen entities. To this end, we formulate parameterized subtask graph inference (PSGI), a method for modeling subtask dependencies using first-order logic with subtask entities. To facilitate this, we learn entity attributes in a zero-shot manner, which are used as quantifiers (e.g. "is_pickable(X)") for the parameterized subtask graph. We show this approach accurately learns the latent structure on hierarchical and compositional tasks more efficiently than prior work, and show PSGI can generalize by modelling structure on subtasks unseen during adaptation.
SURF: Semi-supervised Reward Learning with Data Augmentation for Feedback-efficient Preference-based Reinforcement Learning
Mar 18, 2022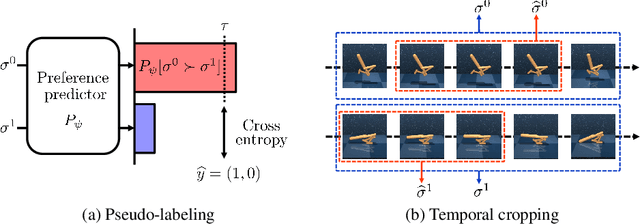

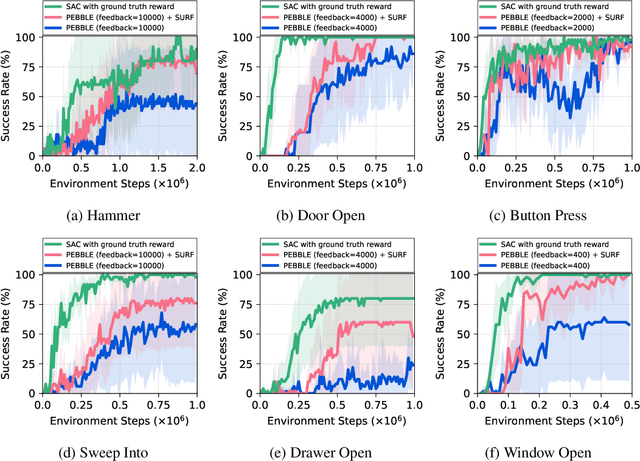

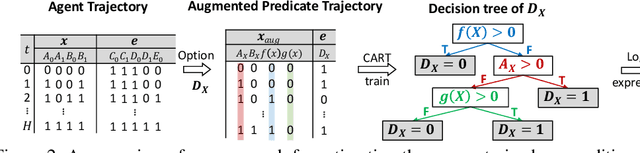
Preference-based reinforcement learning (RL) has shown potential for teaching agents to perform the target tasks without a costly, pre-defined reward function by learning the reward with a supervisor's preference between the two agent behaviors. However, preference-based learning often requires a large amount of human feedback, making it difficult to apply this approach to various applications. This data-efficiency problem, on the other hand, has been typically addressed by using unlabeled samples or data augmentation techniques in the context of supervised learning. Motivated by the recent success of these approaches, we present SURF, a semi-supervised reward learning framework that utilizes a large amount of unlabeled samples with data augmentation. In order to leverage unlabeled samples for reward learning, we infer pseudo-labels of the unlabeled samples based on the confidence of the preference predictor. To further improve the label-efficiency of reward learning, we introduce a new data augmentation that temporally crops consecutive subsequences from the original behaviors. Our experiments demonstrate that our approach significantly improves the feedback-efficiency of the state-of-the-art preference-based method on a variety of locomotion and robotic manipulation tasks.
Rich CNN-Transformer Feature Aggregation Networks for Super-Resolution
Mar 16, 2022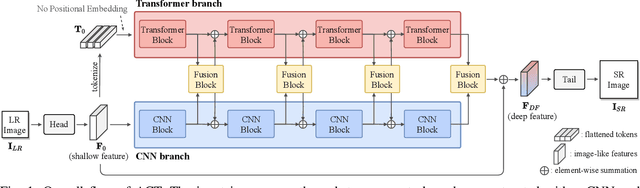


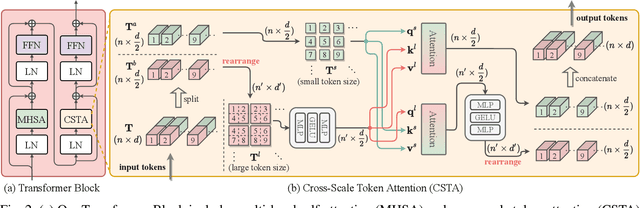
Recent vision transformers along with self-attention have achieved promising results on various computer vision tasks. In particular, a pure transformer-based image restoration architecture surpasses the existing CNN-based methods using multi-task pre-training with a large number of trainable parameters. In this paper, we introduce an effective hybrid architecture for super-resolution (SR) tasks, which leverages local features from CNNs and long-range dependencies captured by transformers to further improve the SR results. Specifically, our architecture comprises of transformer and convolution branches, and we substantially elevate the performance by mutually fusing two branches to complement each representation. Furthermore, we propose a cross-scale token attention module, which allows the transformer to efficiently exploit the informative relationships among tokens across different scales. Our proposed method achieves state-of-the-art SR results on numerous benchmark datasets.
Lipschitz-constrained Unsupervised Skill Discovery
Feb 08, 2022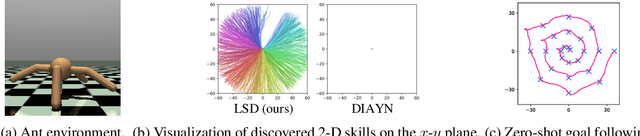

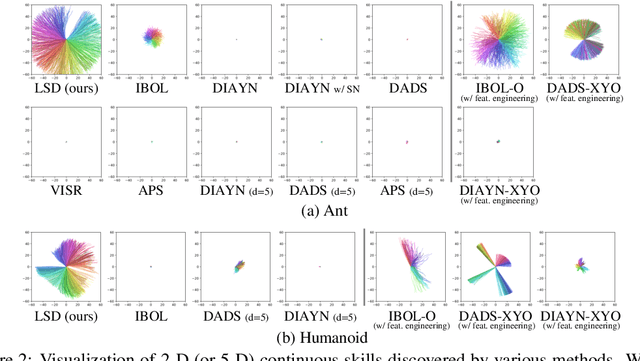
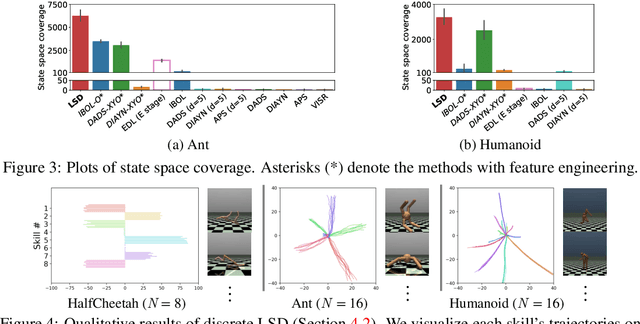
We study the problem of unsupervised skill discovery, whose goal is to learn a set of diverse and useful skills with no external reward. There have been a number of skill discovery methods based on maximizing the mutual information (MI) between skills and states. However, we point out that their MI objectives usually prefer static skills to dynamic ones, which may hinder the application for downstream tasks. To address this issue, we propose Lipschitz-constrained Skill Discovery (LSD), which encourages the agent to discover more diverse, dynamic, and far-reaching skills. Another benefit of LSD is that its learned representation function can be utilized for solving goal-following downstream tasks even in a zero-shot manner - i.e., without further training or complex planning. Through experiments on various MuJoCo robotic locomotion and manipulation environments, we demonstrate that LSD outperforms previous approaches in terms of skill diversity, state space coverage, and performance on seven downstream tasks including the challenging task of following multiple goals on Humanoid. Our code and videos are available at https://shpark.me/projects/lsd/.
Environment Generation for Zero-Shot Compositional Reinforcement Learning
Jan 21, 2022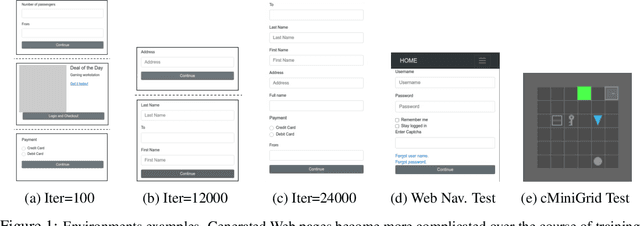
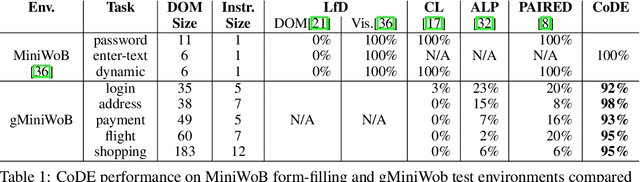

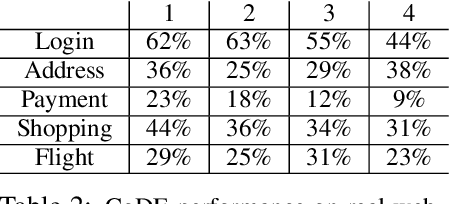
Many real-world problems are compositional - solving them requires completing interdependent sub-tasks, either in series or in parallel, that can be represented as a dependency graph. Deep reinforcement learning (RL) agents often struggle to learn such complex tasks due to the long time horizons and sparse rewards. To address this problem, we present Compositional Design of Environments (CoDE), which trains a Generator agent to automatically build a series of compositional tasks tailored to the RL agent's current skill level. This automatic curriculum not only enables the agent to learn more complex tasks than it could have otherwise, but also selects tasks where the agent's performance is weak, enhancing its robustness and ability to generalize zero-shot to unseen tasks at test-time. We analyze why current environment generation techniques are insufficient for the problem of generating compositional tasks, and propose a new algorithm that addresses these issues. Our results assess learning and generalization across multiple compositional tasks, including the real-world problem of learning to navigate and interact with web pages. We learn to generate environments composed of multiple pages or rooms, and train RL agents capable of completing wide-range of complex tasks in those environments. We contribute two new benchmark frameworks for generating compositional tasks, compositional MiniGrid and gMiniWoB for web navigation.CoDE yields 4x higher success rate than the strongest baseline, and demonstrates strong performance of real websites learned on 3500 primitive tasks.
L-Verse: Bidirectional Generation Between Image and Text
Dec 03, 2021
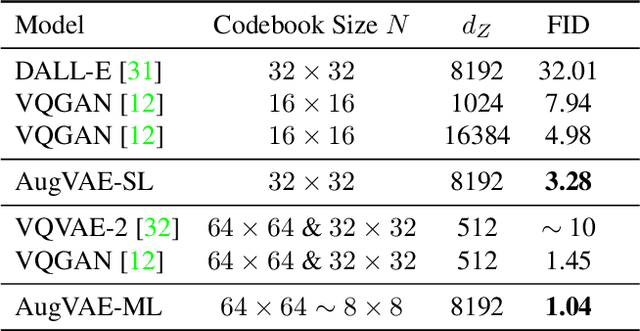
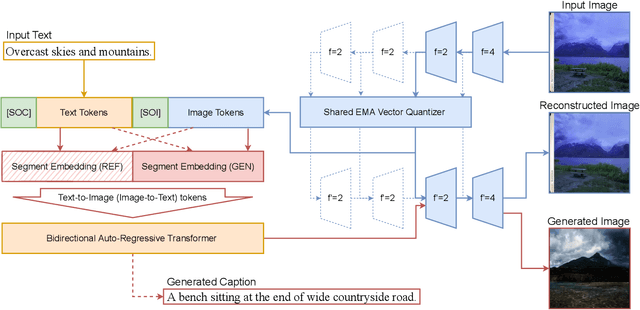
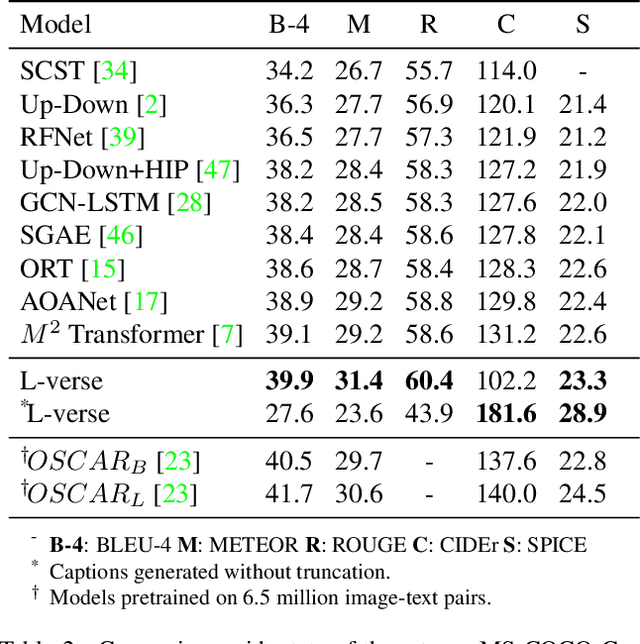
Far beyond learning long-range interactions of natural language, transformers are becoming the de-facto standard for many vision tasks with their power and scalabilty. Especially with cross-modal tasks between image and text, vector quantized variational autoencoders (VQ-VAEs) are widely used to make a raw RGB image into a sequence of feature vectors. To better leverage the correlation between image and text, we propose L-Verse, a novel architecture consisting of feature-augmented variational autoencoder (AugVAE) and bidirectional auto-regressive transformer (BiART) for text-to-image and image-to-text generation. Our AugVAE shows the state-of-the-art reconstruction performance on ImageNet1K validation set, along with the robustness to unseen images in the wild. Unlike other models, BiART can distinguish between image (or text) as a conditional reference and a generation target. L-Verse can be directly used for image-to-text or text-to-image generation tasks without any finetuning or extra object detection frameworks. In quantitative and qualitative experiments, L-Verse shows impressive results against previous methods in both image-to-text and text-to-image generation on MS-COCO Captions. We furthermore assess the scalability of L-Verse architecture on Conceptual Captions and present the initial results of bidirectional vision-language representation learning on general domain.
Successor Feature Landmarks for Long-Horizon Goal-Conditioned Reinforcement Learning
Nov 18, 2021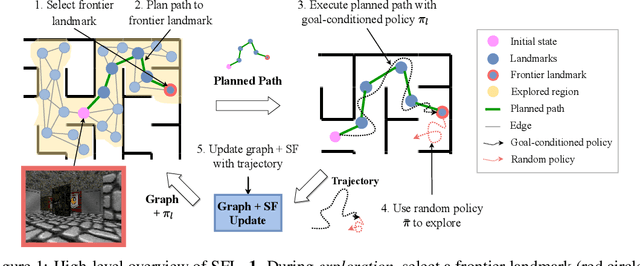
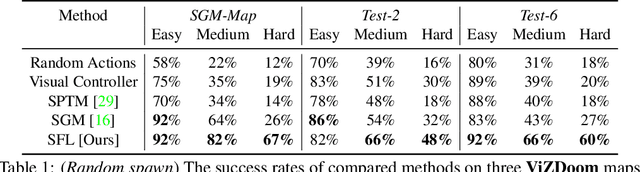
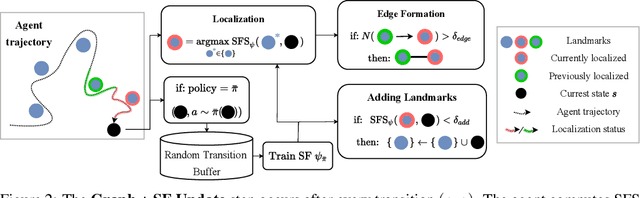
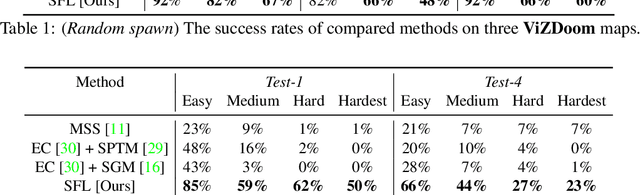
Operating in the real-world often requires agents to learn about a complex environment and apply this understanding to achieve a breadth of goals. This problem, known as goal-conditioned reinforcement learning (GCRL), becomes especially challenging for long-horizon goals. Current methods have tackled this problem by augmenting goal-conditioned policies with graph-based planning algorithms. However, they struggle to scale to large, high-dimensional state spaces and assume access to exploration mechanisms for efficiently collecting training data. In this work, we introduce Successor Feature Landmarks (SFL), a framework for exploring large, high-dimensional environments so as to obtain a policy that is proficient for any goal. SFL leverages the ability of successor features (SF) to capture transition dynamics, using it to drive exploration by estimating state-novelty and to enable high-level planning by abstracting the state-space as a non-parametric landmark-based graph. We further exploit SF to directly compute a goal-conditioned policy for inter-landmark traversal, which we use to execute plans to "frontier" landmarks at the edge of the explored state space. We show in our experiments on MiniGrid and ViZDoom that SFL enables efficient exploration of large, high-dimensional state spaces and outperforms state-of-the-art baselines on long-horizon GCRL tasks.
Improving Transferability of Representations via Augmentation-Aware Self-Supervision
Nov 18, 2021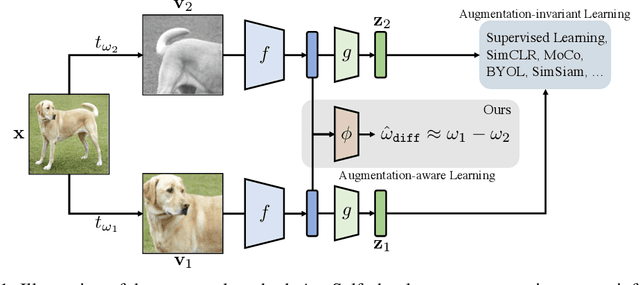
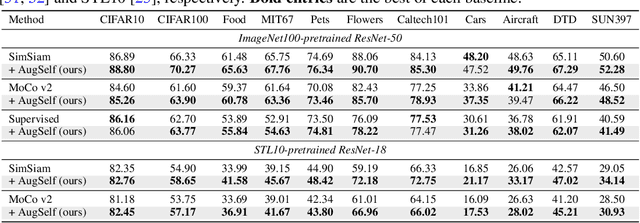
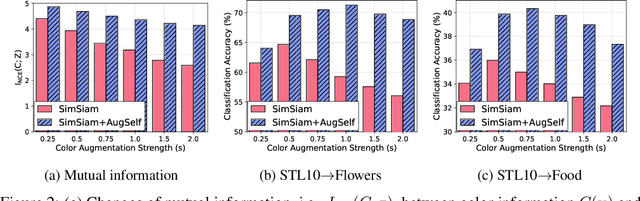
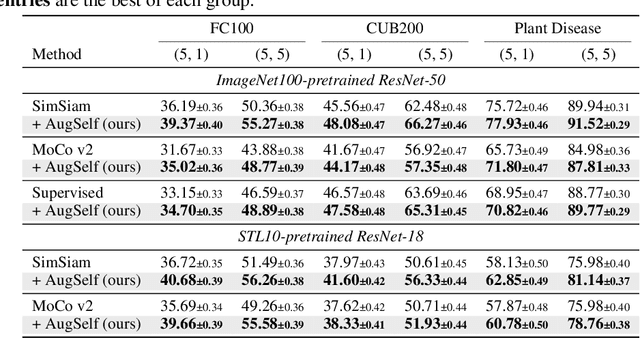
Recent unsupervised representation learning methods have shown to be effective in a range of vision tasks by learning representations invariant to data augmentations such as random cropping and color jittering. However, such invariance could be harmful to downstream tasks if they rely on the characteristics of the data augmentations, e.g., location- or color-sensitive. This is not an issue just for unsupervised learning; we found that this occurs even in supervised learning because it also learns to predict the same label for all augmented samples of an instance. To avoid such failures and obtain more generalizable representations, we suggest to optimize an auxiliary self-supervised loss, coined AugSelf, that learns the difference of augmentation parameters (e.g., cropping positions, color adjustment intensities) between two randomly augmented samples. Our intuition is that AugSelf encourages to preserve augmentation-aware information in learned representations, which could be beneficial for their transferability. Furthermore, AugSelf can easily be incorporated into recent state-of-the-art representation learning methods with a negligible additional training cost. Extensive experiments demonstrate that our simple idea consistently improves the transferability of representations learned by supervised and unsupervised methods in various transfer learning scenarios. The code is available at https://github.com/hankook/AugSelf.
Contrastive Representation Learning for Rapid Intraoperative Diagnosis of Skull Base Tumors Imaged Using Stimulated Raman Histology
Aug 08, 2021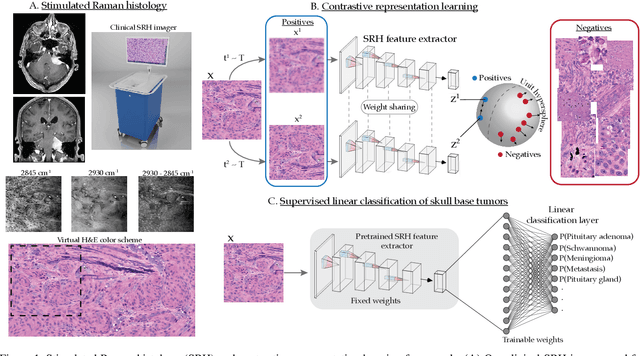

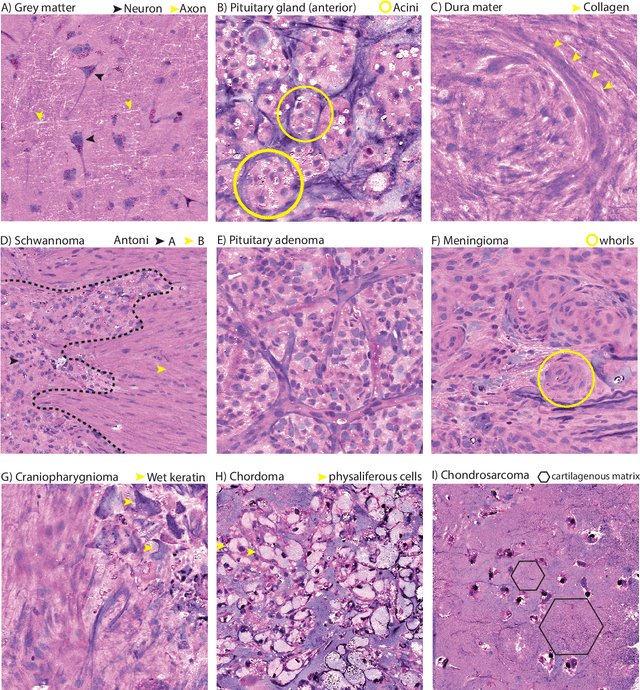
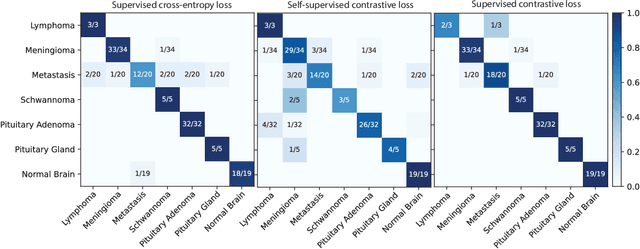
Background: Accurate diagnosis of skull base tumors is essential for providing personalized surgical treatment strategies. Intraoperative diagnosis can be challenging due to tumor diversity and lack of intraoperative pathology resources. Objective: To develop an independent and parallel intraoperative pathology workflow that can provide rapid and accurate skull base tumor diagnoses using label-free optical imaging and artificial intelligence (AI). Method: We used a fiber laser-based, label-free, non-consumptive, high-resolution microscopy method ($<$ 60 sec per 1 $\times$ 1 mm$^\text{2}$), called stimulated Raman histology (SRH), to image a consecutive, multicenter cohort of skull base tumor patients. SRH images were then used to train a convolutional neural network (CNN) model using three representation learning strategies: cross-entropy, self-supervised contrastive learning, and supervised contrastive learning. Our trained CNN models were tested on a held-out, multicenter SRH dataset. Results: SRH was able to image the diagnostic features of both benign and malignant skull base tumors. Of the three representation learning strategies, supervised contrastive learning most effectively learned the distinctive and diagnostic SRH image features for each of the skull base tumor types. In our multicenter testing set, cross-entropy achieved an overall diagnostic accuracy of 91.5%, self-supervised contrastive learning 83.9%, and supervised contrastive learning 96.6%. Our trained model was able to identify tumor-normal margins and detect regions of microscopic tumor infiltration in whole-slide SRH images. Conclusion: SRH with AI models trained using contrastive representation learning can provide rapid and accurate intraoperative diagnosis of skull base tumors.
Shortest-Path Constrained Reinforcement Learning for Sparse Reward Tasks
Jul 13, 2021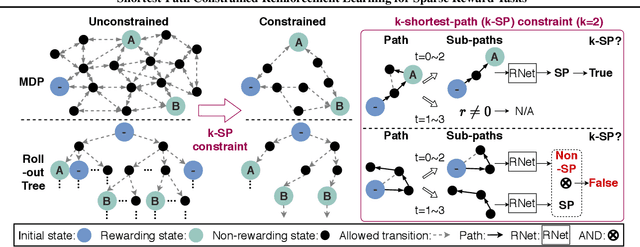
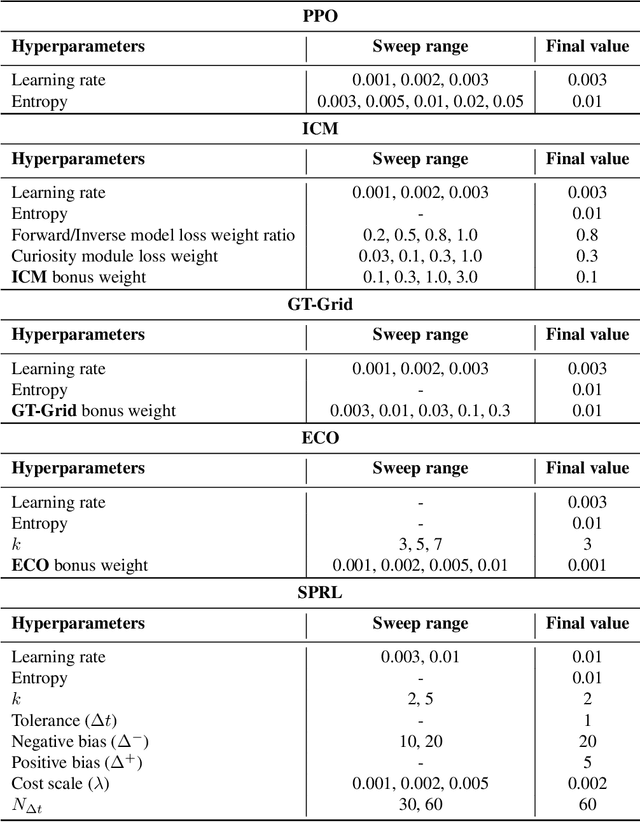

We propose the k-Shortest-Path (k-SP) constraint: a novel constraint on the agent's trajectory that improves the sample efficiency in sparse-reward MDPs. We show that any optimal policy necessarily satisfies the k-SP constraint. Notably, the k-SP constraint prevents the policy from exploring state-action pairs along the non-k-SP trajectories (e.g., going back and forth). However, in practice, excluding state-action pairs may hinder the convergence of RL algorithms. To overcome this, we propose a novel cost function that penalizes the policy violating SP constraint, instead of completely excluding it. Our numerical experiment in a tabular RL setting demonstrates that the SP constraint can significantly reduce the trajectory space of policy. As a result, our constraint enables more sample efficient learning by suppressing redundant exploration and exploitation. Our experiments on MiniGrid, DeepMind Lab, Atari, and Fetch show that the proposed method significantly improves proximal policy optimization (PPO) and outperforms existing novelty-seeking exploration methods including count-based exploration even in continuous control tasks, indicating that it improves the sample efficiency by preventing the agent from taking redundant actions.