 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerception- and Fidelity-aware Reduced-Reference Super-Resolution Image Quality Assessment
May 15, 2024



With the advent of image super-resolution (SR) algorithms, how to evaluate the quality of generated SR images has become an urgent task. Although full-reference methods perform well in SR image quality assessment (SR-IQA), their reliance on high-resolution (HR) images limits their practical applicability. Leveraging available reconstruction information as much as possible for SR-IQA, such as low-resolution (LR) images and the scale factors, is a promising way to enhance assessment performance for SR-IQA without HR for reference. In this letter, we attempt to evaluate the perceptual quality and reconstruction fidelity of SR images considering LR images and scale factors. Specifically, we propose a novel dual-branch reduced-reference SR-IQA network, \ie, Perception- and Fidelity-aware SR-IQA (PFIQA). The perception-aware branch evaluates the perceptual quality of SR images by leveraging the merits of global modeling of Vision Transformer (ViT) and local relation of ResNet, and incorporating the scale factor to enable comprehensive visual perception. Meanwhile, the fidelity-aware branch assesses the reconstruction fidelity between LR and SR images through their visual perception. The combination of the two branches substantially aligns with the human visual system, enabling a comprehensive SR image evaluation. Experimental results indicate that our PFIQA outperforms current state-of-the-art models across three widely-used SR-IQA benchmarks. Notably, PFIQA excels in assessing the quality of real-world SR images.
Real-Time Vehicle Detection and Urban Traffic Behavior Analysis Based on UAV Traffic Videos on Mobile Devices
Feb 26, 2024This paper focuses on a real-time vehicle detection and urban traffic behavior analysis system based on Unmanned Aerial Vehicle (UAV) traffic video. By using UAV to collect traffic data and combining the YOLOv8 model and SORT tracking algorithm, the object detection and tracking functions are implemented on the iOS mobile platform. For the problem of traffic data acquisition and analysis, the dynamic computing method is used to process the performance in real time and calculate the micro and macro traffic parameters of the vehicles, and real-time traffic behavior analysis is conducted and visualized. The experiment results reveals that the vehicle object detection can reach 98.27% precision rate and 87.93% recall rate, and the real-time processing capacity is stable at 30 frames per seconds. This work integrates drone technology, iOS development, and deep learning techniques to integrate traffic video acquisition, object detection, object tracking, and traffic behavior analysis functions on mobile devices. It provides new possibilities for lightweight traffic information collection and data analysis, and offers innovative solutions to improve the efficiency of analyzing road traffic conditions and addressing transportation issues for transportation authorities.
Heterogeneous Graph Neural Architecture Search with GPT-4
Dec 14, 2023



Heterogeneous graph neural architecture search (HGNAS) represents a powerful tool for automatically designing effective heterogeneous graph neural networks. However, existing HGNAS algorithms suffer from inefficient searches and unstable results. In this paper, we present a new GPT-4 based HGNAS model to improve the search efficiency and search accuracy of HGNAS. Specifically, we present a new GPT-4 enhanced Heterogeneous Graph Neural Architecture Search (GHGNAS for short). The basic idea of GHGNAS is to design a set of prompts that can guide GPT-4 toward the task of generating new heterogeneous graph neural architectures. By iteratively asking GPT-4 with the prompts, GHGNAS continually validates the accuracy of the generated HGNNs and uses the feedback to further optimize the prompts. Experimental results show that GHGNAS can design new HGNNs by leveraging the powerful generalization capability of GPT-4. Moreover, GHGNAS runs more effectively and stably than previous HGNAS models based on reinforcement learning and differentiable search algorithms.
Predicted Embedding Power Regression for Large-Scale Out-of-Distribution Detection
Mar 14, 2023



Out-of-distribution (OOD) inputs can compromise the performance and safety of real world machine learning systems. While many methods exist for OOD detection and work well on small scale datasets with lower resolution and few classes, few methods have been developed for large-scale OOD detection. Existing large-scale methods generally depend on maximum classification probability, such as the state-of-the-art grouped softmax method. In this work, we develop a novel approach that calculates the probability of the predicted class label based on label distributions learned during the training process. Our method performs better than current state-of-the-art methods with only a negligible increase in compute cost. We evaluate our method against contemporary methods across $14$ datasets and achieve a statistically significant improvement with respect to AUROC (84.2 vs 82.4) and AUPR (96.2 vs 93.7).
A Large-Scale Annotated Multivariate Time Series Aviation Maintenance Dataset from the NGAFID
Oct 13, 2022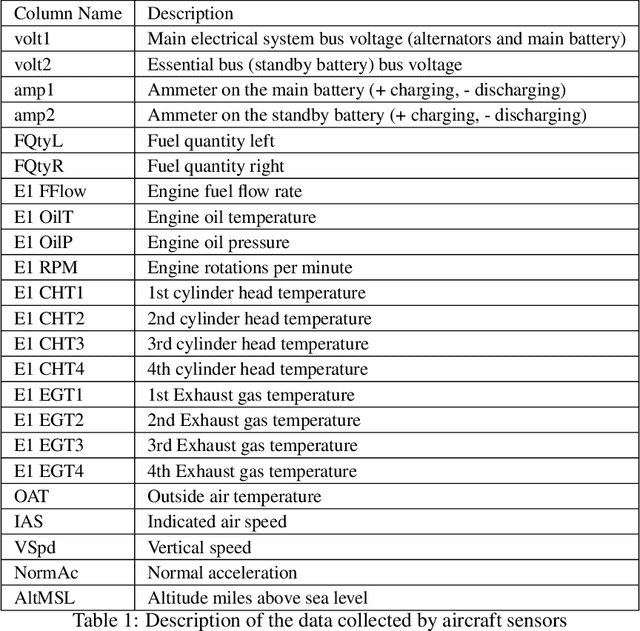
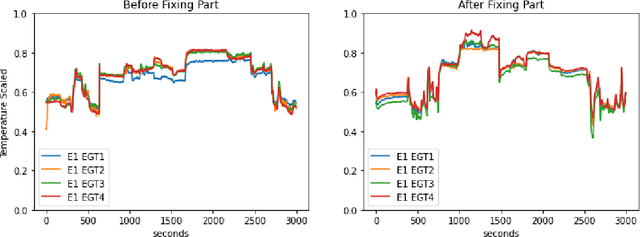
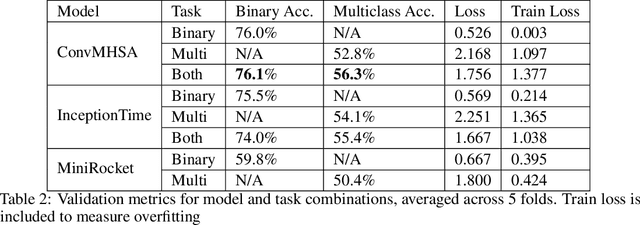
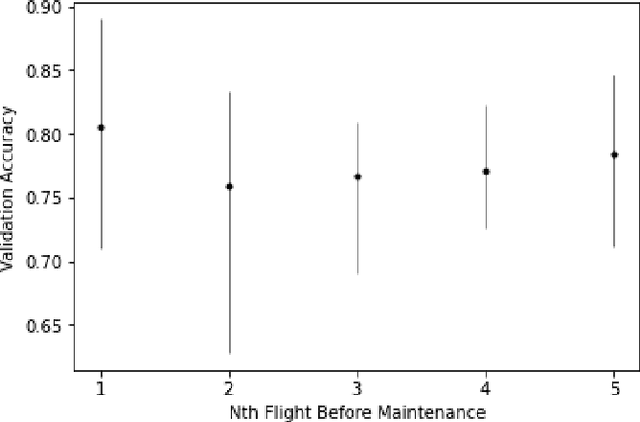
This paper presents the largest publicly available, non-simulated, fleet-wide aircraft flight recording and maintenance log data for use in predicting part failure and maintenance need. We present 31,177 hours of flight data across 28,935 flights, which occur relative to 2,111 unplanned maintenance events clustered into 36 types of maintenance issues. Flights are annotated as before or after maintenance, with some flights occurring on the day of maintenance. Collecting data to evaluate predictive maintenance systems is challenging because it is difficult, dangerous, and unethical to generate data from compromised aircraft. To overcome this, we use the National General Aviation Flight Information Database (NGAFID), which contains flights recorded during regular operation of aircraft, and maintenance logs to construct a part failure dataset. We use a novel framing of Remaining Useful Life (RUL) prediction and consider the probability that the RUL of a part is greater than 2 days. Unlike previous datasets generated with simulations or in laboratory settings, the NGAFID Aviation Maintenance Dataset contains real flight records and maintenance logs from different seasons, weather conditions, pilots, and flight patterns. Additionally, we provide Python code to easily download the dataset and a Colab environment to reproduce our benchmarks on three different models. Our dataset presents a difficult challenge for machine learning researchers and a valuable opportunity to test and develop prognostic health management methods
Smart Hybrid Beamforming and Pilot Assignment for 6G Cell-Free Massive MIMO
Oct 11, 2022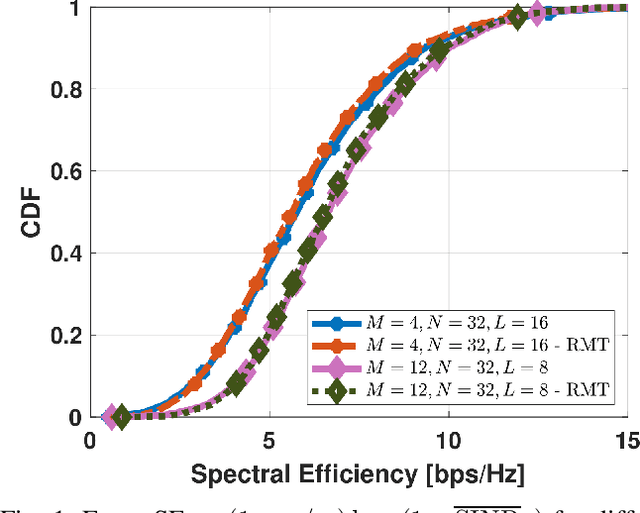
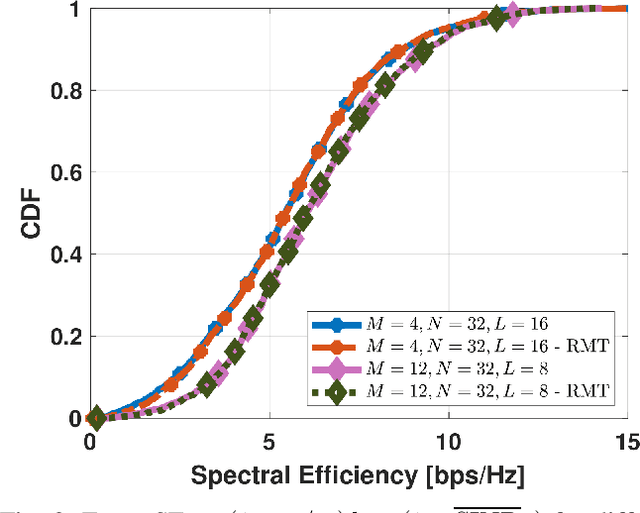
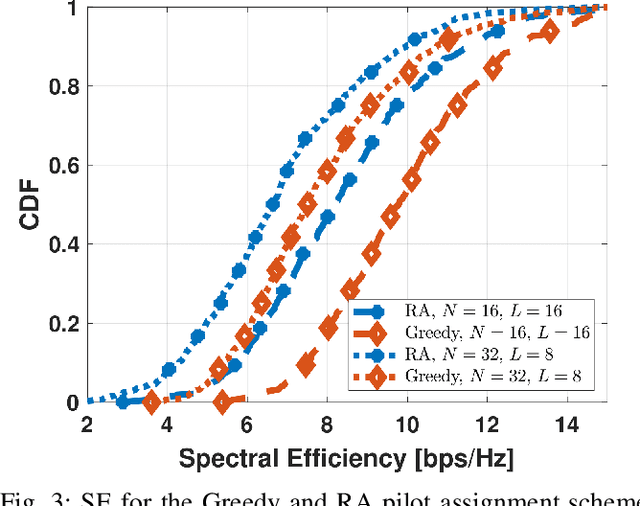
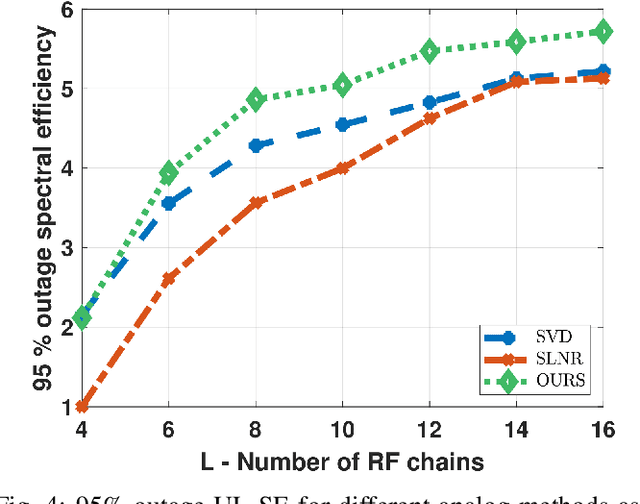
This paper investigates Cell-Free massive MIMO networks, where each access point (AP) is equipped with a hybrid transceiver, reducing the complexity and cost compared to a fully digital transceiver. Asymptotic approximations for the spectral efficiency are derived for uplink and downlink. Capitalizing on these expressions, a max-min problem is formulated to optimize the (i) analog beamformer at the APs and (ii) pilot assignment. Simulations show that the optimization of these variables substantially increases the network performance.
LAB-Net: LAB Color-Space Oriented Lightweight Network for Shadow Removal
Aug 27, 2022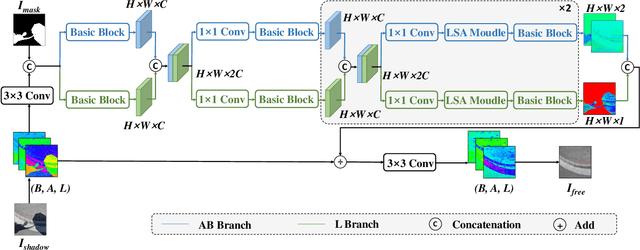
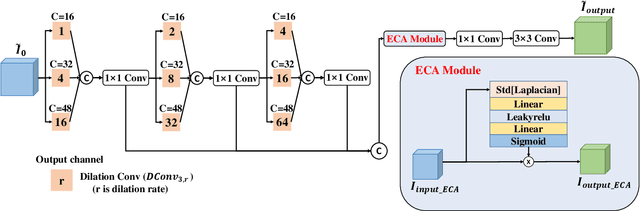
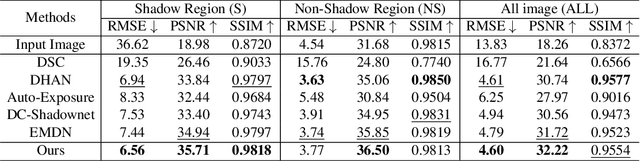

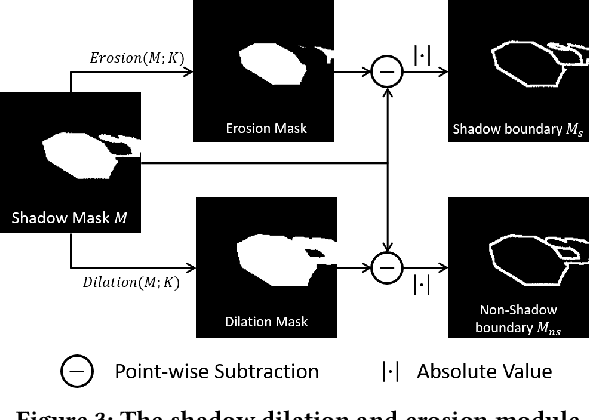
This paper focuses on the limitations of current over-parameterized shadow removal models. We present a novel lightweight deep neural network that processes shadow images in the LAB color space. The proposed network termed "LAB-Net", is motivated by the following three observations: First, the LAB color space can well separate the luminance information and color properties. Second, sequentially-stacked convolutional layers fail to take full use of features from different receptive fields. Third, non-shadow regions are important prior knowledge to diminish the drastic color difference between shadow and non-shadow regions. Consequently, we design our LAB-Net by involving a two-branch structure: L and AB branches. Thus the shadow-related luminance information can well be processed in the L branch, while the color property is well retained in the AB branch. In addition, each branch is composed of several Basic Blocks, local spatial attention modules (LSA), and convolutional filters. Each Basic Block consists of multiple parallelized dilated convolutions of divergent dilation rates to receive different receptive fields that are operated with distinct network widths to save model parameters and computational costs. Then, an enhanced channel attention module (ECA) is constructed to aggregate features from different receptive fields for better shadow removal. Finally, the LSA modules are further developed to fully use the prior information in non-shadow regions to cleanse the shadow regions. We perform extensive experiments on the both ISTD and SRD datasets. Experimental results show that our LAB-Net well outperforms state-of-the-art methods. Also, our model's parameters and computational costs are reduced by several orders of magnitude. Our code is available at https://github.com/ngrxmu/LAB-Net.
Shadow-Aware Dynamic Convolution for Shadow Removal
May 10, 2022
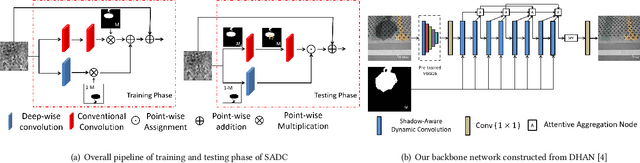
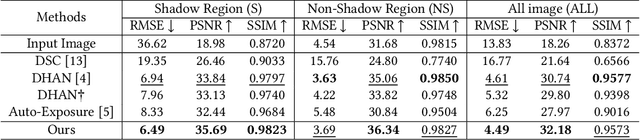
With a wide range of shadows in many collected images, shadow removal has aroused increasing attention since uncontaminated images are of vital importance for many downstream multimedia tasks. Current methods consider the same convolution operations for both shadow and non-shadow regions while ignoring the large gap between the color mappings for the shadow region and the non-shadow region, leading to poor quality of reconstructed images and a heavy computation burden. To solve this problem, this paper introduces a novel plug-and-play Shadow-Aware Dynamic Convolution (SADC) module to decouple the interdependence between the shadow region and the non-shadow region. Inspired by the fact that the color mapping of the non-shadow region is easier to learn, our SADC processes the non-shadow region with a lightweight convolution module in a computationally cheap manner and recovers the shadow region with a more complicated convolution module to ensure the quality of image reconstruction. Given that the non-shadow region often contains more background color information, we further develop a novel intra-convolution distillation loss to strengthen the information flow from the non-shadow region to the shadow region. Extensive experiments on the ISTD and SRD datasets show our method achieves better performance in shadow removal over many state-of-the-arts. Our code is available at https://github.com/xuyimin0926/SADC.
Robust Augmentation for Multivariate Time Series Classification
Jan 27, 2022Neural networks are capable of learning powerful representations of data, but they are susceptible to overfitting due to the number of parameters. This is particularly challenging in the domain of time series classification, where datasets may contain fewer than 100 training examples. In this paper, we show that the simple methods of cutout, cutmix, mixup, and window warp improve the robustness and overall performance in a statistically significant way for convolutional, recurrent, and self-attention based architectures for time series classification. We evaluate these methods on 26 datasets from the University of East Anglia Multivariate Time Series Classification (UEA MTSC) archive and analyze how these methods perform on different types of time series data.. We show that the InceptionTime network with augmentation improves accuracy by 1% to 45% in 18 different datasets compared to without augmentation. We also show that augmentation improves accuracy for recurrent and self attention based architectures.
Predictive Maintenance for General Aviation Using Convolutional Transformers
Oct 07, 2021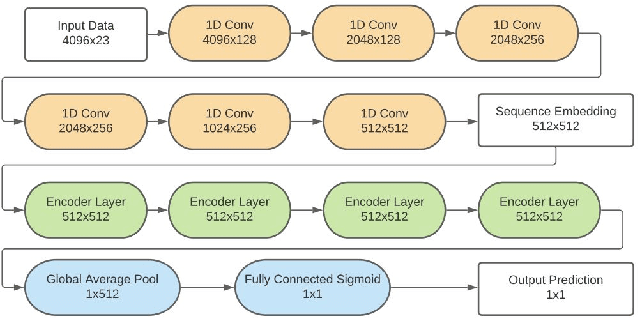
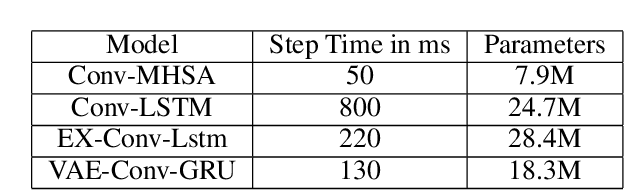
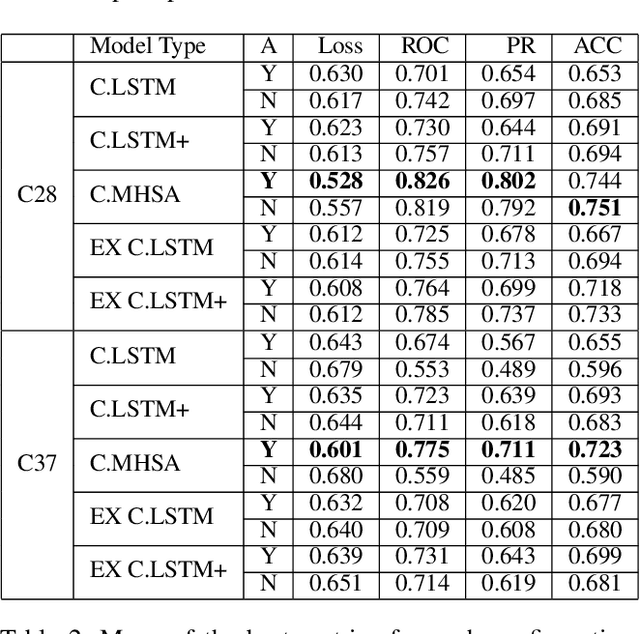
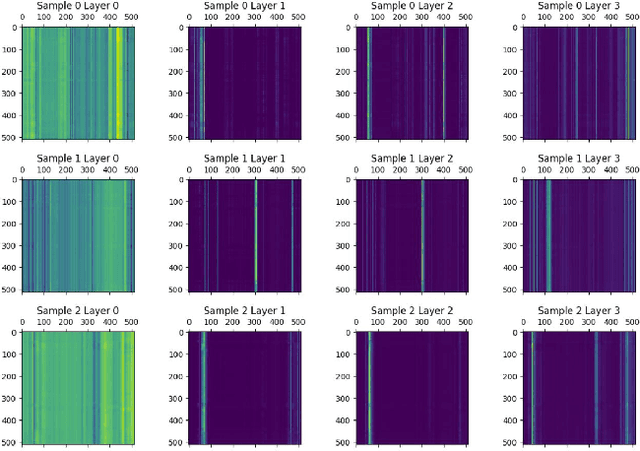
Predictive maintenance systems have the potential to significantly reduce costs for maintaining aircraft fleets as well as provide improved safety by detecting maintenance issues before they come severe. However, the development of such systems has been limited due to a lack of publicly labeled multivariate time series (MTS) sensor data. MTS classification has advanced greatly over the past decade, but there is a lack of sufficiently challenging benchmarks for new methods. This work introduces the NGAFID Maintenance Classification (NGAFID-MC) dataset as a novel benchmark in terms of difficulty, number of samples, and sequence length. NGAFID-MC consists of over 7,500 labeled flights, representing over 11,500 hours of per second flight data recorder readings of 23 sensor parameters. Using this benchmark, we demonstrate that Recurrent Neural Network (RNN) methods are not well suited for capturing temporally distant relationships and propose a new architecture called Convolutional Multiheaded Self Attention (Conv-MHSA) that achieves greater classification performance at greater computational efficiency. We also demonstrate that image inspired augmentations of cutout, mixup, and cutmix, can be used to reduce overfitting and improve generalization in MTS classification. Our best trained models have been incorporated back into the NGAFID to allow users to potentially detect flights that require maintenance as well as provide feedback to further expand and refine the NGAFID-MC dataset.