 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERQA-Plus: A Diagnostic Benchmark for Reasoning in Embodied AI
Jun 17, 2026Generalist embodied agents require more than object recognition: they must reason about spatial relations, actions, procedures, human intentions, environmental constraints, and commonsense consequences from situated visual observations. Yet existing visual and embodied question answering benchmarks often provide limited control over the reasoning dependencies being tested, making it difficult to distinguish grounded embodied reasoning from shortcut-driven visual or linguistic pattern matching. We present ERQA-Plus, a diagnostic benchmark for reasoning in embodied AI. ERQA-Plus contains 1,766 question-answer instances grounded in 711 robot-centric images and organized according to a structured taxonomy spanning perceptual, action-centric, social-interaction, navigation-environmental, and contextual commonsense reasoning. The dataset is constructed using a multi-stage generation and validation pipeline that combines taxonomy-guided question generation, automatic quality judging, iterative revision, and human assessment to improve visual grounding, answer validity, and reasoning quality. We benchmark representative general-purpose vision-language models and embodied models, including LLaVA-NeXT-8B, Prismatic-7B, MiniCPM-V-4.5-8B, Qwen3-VL, RoboRefer-8B, and RoboBrain2.5-8B. Although the strongest model, Qwen3-VL-32B, achieves 83.4% overall accuracy and 61.4 SBERT score, category-level results reveal persistent weaknesses in spatial reasoning, procedural reasoning, event prediction, and intention inference. ERQA-Plus therefore provides a fine-grained evaluation framework for measuring not only whether embodied agents answer correctly, but also which forms of embodied reasoning they can and cannot perform reliably. The dataset is available https://huggingface.co/datasets/huggingdas/erqa-plus and the project page at https://github.com/LUNAProject22/erqa-plus.
IUU+DB: Tracking Illegal, Unreported, and Unregulated Fishing, Seafood Fraud, and Labor Abuse through LLM-driven Information Extraction
Jun 16, 2026Illegal, unreported, and unregulated fishing (IUU) traditionally refers to fishing activities that violate applicable laws or occur in areas that lack applicable laws. We propose the term IUU+ to capture a broader suite of fisheries sector environmental and associated supply chain trade-related crimes and behaviors. Although IUU+ activity is widely recognized as a serious threat to marine ecosystems, markets, and livelihoods, a quantitative understanding of these incidents, e.g., their frequency, geography, species, actors, and patterns in the type of illicit activity, remains difficult to obtain. We propose IUU+DB, a large language model driven system for building a global incident database of IUU+ activity. The system ingests heterogeneous documents, classifies whether they describe relevant incidents, extracts key data elements such as actors, locations, species, vessels, violations, and enforcement outcomes, and supports deduplication and trend analysis. Case studies and validation results show that IUU+DB can help organize fragmented evidence, surface geographic and behavioral hotspots, support fisheries-domain specific research in academia and non-government organizations, assist source and species risk assessments for industry, and provide support for policy implementation and targeted enforcement efforts to government agencies.
Modeling Vehicle-Type-Specific Pedestrian Crash Avoidance Behavior in Safety-Critical Interactions Using Smooth-Mamba Deep Reinforcement Learning
May 27, 2026As automated vehicles (AVs) increasingly share roadways with human-driven vehicles (HDVs), understanding how pedestrians respond to different vehicle types in safety-critical interactions is essential for the safe deployment of automated driving technologies. This study extracts safety-critical pedestrian-vehicle interactions from the Argoverse 2 dataset to capture real-world crash avoidance behaviors in encounters involving AVs and HDVs. To model vehicle-type-specific pedestrian crash avoidance behavior, we develop a Smooth-Mamba Deep Deterministic Policy Gradient framework, termed SMamba-DDPG, which integrates smooth action constraints with efficient temporal representation learning. To quantify pedestrian behavioral differences, the framework trains separate crash avoidance policies for pedestrian interactions with AVs and HDVs. Results show that SMamba-DDPG outperforms baseline reinforcement learning and supervised learning models in reproducing pedestrian crash avoidance behaviors. Reconstructed trajectories demonstrate strong behavioral realism, accurately reproducing crash avoidance kinematics in both AV and HDV scenarios. Reaction time analysis shows that the model captures human-like response delays and reveals that pedestrians respond more quickly to AVs than to HDVs. Counterfactual analysis further indicates that pedestrians adopt lower crossing speeds when interacting with AVs. Large-scale safety analysis of model-generated data revealed that pedestrian-AV interactions consistently yielded lower conflict rates and higher pedestrian yielding rates compared to pedestrian-HDV interactions. The findings highlight the importance of incorporating vehicle-type-specific pedestrian behavioral models for safer automated driving system design and more realistic traffic simulations in mixed-traffic environments.
Robust Multi-Stream Massive MIMO Satellite Systems Based on Statistical CSI
Apr 10, 2026This paper investigates multi-stream downlink precoding for massive multiple-input multiple-output low-Earthorbit satellite (SAT) communication systems. We adopt a delay and Doppler precompensation approach to achieve coherent transmission. Under this setting, we formulate a signal transmission model that incorporates the near-independent properties of inter-SAT interference and compensation errors. We then demonstrate that moving beyond single-stream transmission requires both multi-SAT cooperation and multi-antenna UTs. Based on this configuration and the established signal transmission model, we derive the first- and second-order statistical channel characteristics and utilize them to design locally optimal precoding algorithms for both total power constraint (TPC) and per-antenna power constraint (PAPC) conditions, which rely only on statistical channel state information (sCSI). In particular, the designed PAPC algorithm achieves linear complexity with respect to the number of antennas on the cooperative SATs. To reduce the computational complexity of the locally optimal precoder under TPC, we propose a low-complexity and robust precoding scheme optimized for both minimum mean squared error and sum-rate maximization objectives. Using majorization theory, we also provide a rigorous theoretical analysis of the optimal precoding structure under TPC. Moreover, the Lanczos algorithm is adopted to further reduce the complexity of the proposed robust designs. Simulation results show that when each SAT is equipped with a sufficiently large number of antennas, the proposed sCSI-based designs achieve performance comparable to that of instantaneous CSI-based designs.
Beyond the Class Subspace: Teacher-Guided Training for Reliable Out-of-Distribution Detection in Single-Domain Models
Mar 11, 2026Out-of-distribution (OOD) detection methods perform well on multi-domain benchmarks, yet many practical systems are trained on single-domain data. We show that this regime induces a geometric failure mode, Domain-Sensitivity Collapse (DSC): supervised training compresses features into a low-rank class subspace and suppresses directions that carry domain-shift signal. We provide theory showing that, under DSC, distance- and logit-based OOD scores lose sensitivity to domain shift. We then introduce Teacher-Guided Training (TGT), which distills class-suppressed residual structure from a frozen multi-domain teacher (DINOv2) into the student during training. The teacher and auxiliary head are discarded after training, adding no inference overhead. Across eight single-domain benchmarks, TGT yields large far-OOD FPR@95 reductions for distance-based scorers: MDS improves by 11.61 pp, ViM by 10.78 pp, and kNN by 12.87 pp (ResNet-50 average), while maintaining or slightly improving in-domain OOD and classification accuracy.
A Vision-and-Knowledge Enhanced Large Language Model for Generalizable Pedestrian Crossing Behavior Inference
Jan 02, 2026Existing paradigms for inferring pedestrian crossing behavior, ranging from statistical models to supervised learning methods, demonstrate limited generalizability and perform inadequately on new sites. Recent advances in Large Language Models (LLMs) offer a shift from numerical pattern fitting to semantic, context-aware behavioral reasoning, yet existing LLM applications lack domain-specific adaptation and visual context. This study introduces Pedestrian Crossing LLM (PedX-LLM), a vision-and-knowledge enhanced framework designed to transform pedestrian crossing inference from site-specific pattern recognition to generalizable behavioral reasoning. By integrating LLaVA-extracted visual features with textual data and transportation domain knowledge, PedX-LLM fine-tunes a LLaMA-2-7B foundation model via Low-Rank Adaptation (LoRA) to infer crossing decisions. PedX-LLM achieves 82.0% balanced accuracy, outperforming the best statistical and supervised learning methods. Results demonstrate that the vision-augmented module contributes a 2.9% performance gain by capturing the built environment and integrating domain knowledge yields an additional 4.1% improvement. To evaluate generalizability across unseen environments, cross-site validation was conducted using site-based partitioning. The zero-shot PedX-LLM configuration achieves 66.9% balanced accuracy on five unseen test sites, outperforming the baseline data-driven methods by at least 18 percentage points. Incorporating just five validation examples via few-shot learning to PedX-LLM further elevates the balanced accuracy to 72.2%. PedX-LLM demonstrates strong generalizability to unseen scenarios, confirming that vision-and-knowledge-enhanced reasoning enables the model to mimic human-like decision logic and overcome the limitations of purely data-driven methods.
VALLR-Pin: Uncertainty-Factorized Visual Speech Recognition for Mandarin with Pinyin Guidance
Dec 29, 2025Visual speech recognition (VSR) aims to transcribe spoken content from silent lip-motion videos and is particularly challenging in Mandarin due to severe viseme ambiguity and pervasive homophones. We propose VALLR-Pin, a two-stage Mandarin VSR framework that extends the VALLR architecture by explicitly incorporating Pinyin as an intermediate representation. In the first stage, a shared visual encoder feeds dual decoders that jointly predict Mandarin characters and their corresponding Pinyin sequences, encouraging more robust visual-linguistic representations. In the second stage, an LLM-based refinement module takes the predicted Pinyin sequence together with an N-best list of character hypotheses to resolve homophone-induced ambiguities. To further adapt the LLM to visual recognition errors, we fine-tune it on synthetic instruction data constructed from model-generated Pinyin-text pairs, enabling error-aware correction. Experiments on public Mandarin VSR benchmarks demonstrate that VALLR-Pin consistently improves transcription accuracy under multi-speaker conditions, highlighting the effectiveness of combining phonetic guidance with lightweight LLM refinement.
VALLR-Pin: Dual-Decoding Visual Speech Recognition for Mandarin with Pinyin-Guided LLM Refinement
Dec 23, 2025Visual Speech Recognition aims to transcribe spoken words from silent lip-motion videos. This task is particularly challenging for Mandarin, as visemes are highly ambiguous and homophones are prevalent. We propose VALLR-Pin, a novel two-stage framework that extends the recent VALLR architecture from English to Mandarin. First, a shared video encoder feeds into dual decoders, which jointly predict both Chinese character sequences and their standard Pinyin romanization. The multi-task learning of character and phonetic outputs fosters robust visual-semantic representations. During inference, the text decoder generates multiple candidate transcripts. We construct a prompt by concatenating the Pinyin output with these candidate Chinese sequences and feed it to a large language model to resolve ambiguities and refine the transcription. This provides the LLM with explicit phonetic context to correct homophone-induced errors. Finally, we fine-tune the LLM on synthetic noisy examples: we generate imperfect Pinyin-text pairs from intermediate VALLR-Pin checkpoints using the training data, creating instruction-response pairs for error correction. This endows the LLM with awareness of our model's specific error patterns. In summary, VALLR-Pin synergizes visual features with phonetic and linguistic context to improve Mandarin lip-reading performance.
Can We Ignore Labels In Out of Distribution Detection?
Apr 20, 2025
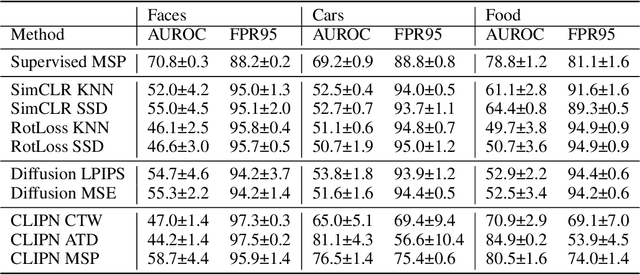

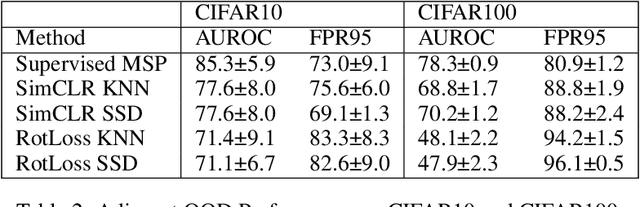
Out-of-distribution (OOD) detection methods have recently become more prominent, serving as a core element in safety-critical autonomous systems. One major purpose of OOD detection is to reject invalid inputs that could lead to unpredictable errors and compromise safety. Due to the cost of labeled data, recent works have investigated the feasibility of self-supervised learning (SSL) OOD detection, unlabeled OOD detection, and zero shot OOD detection. In this work, we identify a set of conditions for a theoretical guarantee of failure in unlabeled OOD detection algorithms from an information-theoretic perspective. These conditions are present in all OOD tasks dealing with real-world data: I) we provide theoretical proof of unlabeled OOD detection failure when there exists zero mutual information between the learning objective and the in-distribution labels, a.k.a. 'label blindness', II) we define a new OOD task - Adjacent OOD detection - that tests for label blindness and accounts for a previously ignored safety gap in all OOD detection benchmarks, and III) we perform experiments demonstrating that existing unlabeled OOD methods fail under conditions suggested by our label blindness theory and analyze the implications for future research in unlabeled OOD methods.
HEAT:History-Enhanced Dual-phase Actor-Critic Algorithm with A Shared Transformer
Apr 13, 2025

For a single-gateway LoRaWAN network, this study proposed a history-enhanced two-phase actor-critic algorithm with a shared transformer algorithm (HEAT) to improve network performance. HEAT considers uplink parameters and often neglected downlink parameters, and effectively integrates offline and online reinforcement learning, using historical data and real-time interaction to improve model performance. In addition, this study developed an open source LoRaWAN network simulator LoRaWANSim. The simulator considers the demodulator lock effect and supports multi-channel, multi-demodulator and bidirectional communication. Simulation experiments show that compared with the best results of all compared algorithms, HEAT improves the packet success rate and energy efficiency by 15% and 95%, respectively.