 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Normalizing Constants for Log-Concave Distributions: Algorithms and Lower Bounds
Nov 08, 2019Estimating the normalizing constant of an unnormalized probability distribution has important applications in computer science, statistical physics, machine learning, and statistics. In this work, we consider the problem of estimating the normalizing constant $Z=\int_{\mathbb{R}^d} e^{-f(x)}\,\mathrm{d}x$ to within a multiplication factor of $1 \pm \varepsilon$ for a $\mu$-strongly convex and $L$-smooth function $f$, given query access to $f(x)$ and $\nabla f(x)$. We give both algorithms and lowerbounds for this problem. Using an annealing algorithm combined with a multilevel Monte Carlo method based on underdamped Langevin dynamics, we show that $\widetilde{\mathcal{O}}\Bigl(\frac{d^{4/3}\kappa + d^{7/6}\kappa^{7/6}}{\varepsilon^2}\Bigr)$ queries to $\nabla f$ are sufficient, where $\kappa= L / \mu$ is the condition number. Moreover, we provide an information theoretic lowerbound, showing that at least $\frac{d^{1-o(1)}}{\varepsilon^{2-o(1)}}$ queries are necessary. This provides a first nontrivial lowerbound for the problem.
Explaining Landscape Connectivity of Low-cost Solutions for Multilayer Nets
Jun 14, 2019
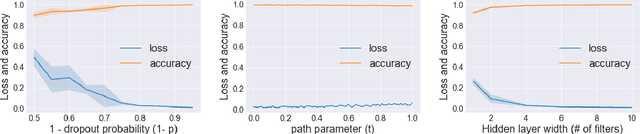
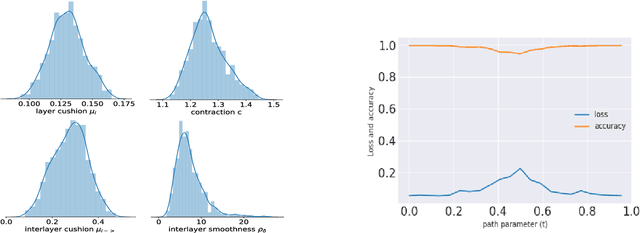

Mode connectivity is a surprising phenomenon in the loss landscape of deep nets. Optima---at least those discovered by gradient-based optimization---turn out to be connected by simple paths on which the loss function is almost constant. Often, these paths can be chosen to be piece-wise linear, with as few as two segments. We give mathematical explanations for this phenomenon, assuming generic properties (such as dropout stability and noise stability) of well-trained deep nets, which have previously been identified as part of understanding the generalization properties of deep nets. Our explanation holds for realistic multilayer nets, and experiments are presented to verify the theory.
Robust guarantees for learning an autoregressive filter
May 23, 2019The optimal predictor for a linear dynamical system (with hidden state and Gaussian noise) takes the form of an autoregressive linear filter, namely the Kalman filter. However, a fundamental problem in reinforcement learning and control theory is to make optimal predictions in an unknown dynamical system. To this end, we take the approach of directly learning an autoregressive filter for time-series prediction under unknown dynamics. Our analysis differs from previous statistical analyses in that we regress not only on the inputs to the dynamical system, but also the outputs, which is essential to dealing with process noise. The main challenge is to estimate the filter under worst case input (in $\mathcal H_\infty$ norm), for which we use an $L^\infty$-based objective rather than ordinary least-squares. For learning an autoregressive model, our algorithm has optimal sample complexity in terms of the rollout length, which does not seem to be attained by naive least-squares.
Online Sampling from Log-Concave Distributions
Mar 08, 2019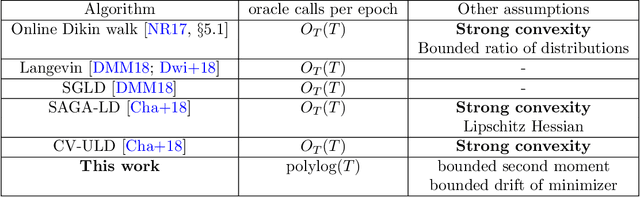
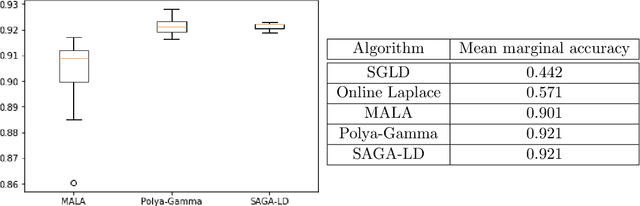
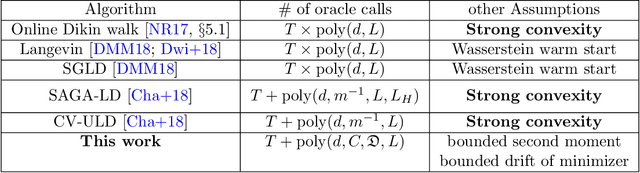
Given a sequence of convex functions $f_0, f_1, \ldots, f_T$, we study the problem of sampling from the Gibbs distribution $\pi_t \propto e^{-\sum_{k=0}^t f_k}$ for each epoch $t$ in an online manner. This problem occurs in applications to machine learning, Bayesian statistics, and optimization where one constantly acquires new data, and must continuously update the distribution. Our main result is an algorithm that generates independent samples from a distribution that is a fixed $\varepsilon$ TV-distance from $\pi_t$ for every $t$ and, under mild assumptions on the functions, makes poly$\log(T)$ gradient evaluations per epoch. All previous results for this problem imply a bound on the number of gradient or function evaluations which is at least linear in $T$. While we assume the functions have bounded second moment, we do not assume strong convexity. In particular, we show that our assumptions hold for online Bayesian logistic regression, when the data satisfy natural regularity properties. In simulations, our algorithm achieves accuracy comparable to that of a Markov chain specialized to logistic regression. Our main result also implies the first algorithm to sample from a $d$-dimensional log-concave distribution $\pi_T \propto e^{-\sum_{k=0}^T f_k}$ where the $f_k$'s are not assumed to be strongly convex and the total number of gradient evaluations is roughly $T\log(T)+\mathrm{poly}(d),$ as opposed to $T\cdot \mathrm{poly}(d)$ implied by prior works. Key to our algorithm is a novel stochastic gradient Langevin dynamics Markov chain that has a carefully designed variance reduction step built-in with fixed constant batch size. Technically, lack of strong convexity is a significant barrier to the analysis, and, here, our main contribution is a martingale exit time argument showing the chain is constrained to a ball of radius roughly poly$\log(T)$ for the duration of the algorithm.
Simulated Tempering Langevin Monte Carlo II: An Improved Proof using Soft Markov Chain Decomposition
Nov 29, 2018
A key task in Bayesian machine learning is sampling from distributions that are only specified up to a partition function (i.e., constant of proportionality). One prevalent example of this is sampling posteriors in parametric distributions, such as latent-variable generative models. However sampling (even very approximately) can be #P-hard. Classical results going back to Bakry and \'Emery (1985) on sampling focus on log-concave distributions, and show a natural Markov chain called Langevin diffusion mixes in polynomial time. However, all log-concave distributions are uni-modal, while in practice it is very common for the distribution of interest to have multiple modes. In this case, Langevin diffusion suffers from torpid mixing. We address this problem by combining Langevin diffusion with simulated tempering. The result is a Markov chain that mixes more rapidly by transitioning between different temperatures of the distribution. We analyze this Markov chain for a mixture of (strongly) log-concave distributions of the same shape. In particular, our technique applies to the canonical multi-modal distribution: a mixture of gaussians (of equal variance). Our algorithm efficiently samples from these distributions given only access to the gradient of the log-pdf. For the analysis, we introduce novel techniques for proving spectral gaps based on decomposing the action of the generator of the diffusion. Previous approaches rely on decomposing the state space as a partition of sets, while our approach can be thought of as decomposing the stationary measure as a mixture of distributions (a "soft partition"). Additional materials for the paper can be found at http://tiny.cc/glr17. The proof and results have been improved and generalized from the precursor at www.arxiv.org/abs/1710.02736.
* 55 pages. arXiv admin note: text overlap with arXiv:1710.02736
Spectral Filtering for General Linear Dynamical Systems
Feb 12, 2018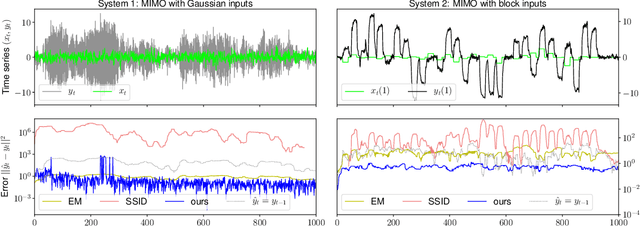
We give a polynomial-time algorithm for learning latent-state linear dynamical systems without system identification, and without assumptions on the spectral radius of the system's transition matrix. The algorithm extends the recently introduced technique of spectral filtering, previously applied only to systems with a symmetric transition matrix, using a novel convex relaxation to allow for the efficient identification of phases.
Beyond Log-concavity: Provable Guarantees for Sampling Multi-modal Distributions using Simulated Tempering Langevin Monte Carlo
Nov 06, 2017
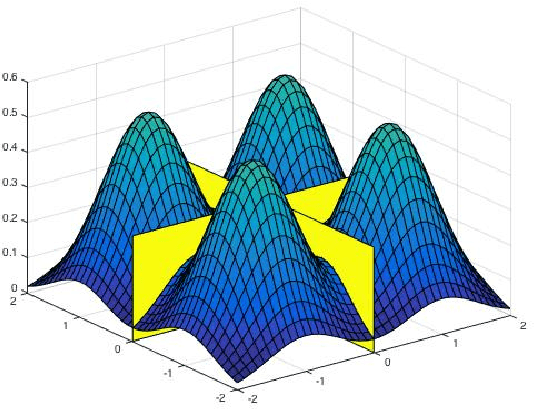
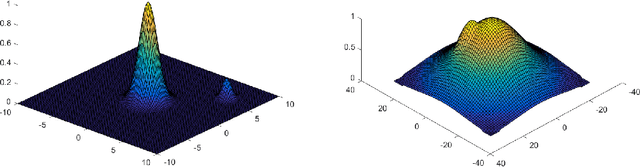
A key task in Bayesian statistics is sampling from distributions that are only specified up to a partition function (i.e., constant of proportionality). However, without any assumptions, sampling (even approximately) can be #P-hard, and few works have provided "beyond worst-case" guarantees for such settings. For log-concave distributions, classical results going back to Bakry and \'Emery (1985) show that natural continuous-time Markov chains called Langevin diffusions mix in polynomial time. The most salient feature of log-concavity violated in practice is uni-modality: commonly, the distributions we wish to sample from are multi-modal. In the presence of multiple deep and well-separated modes, Langevin diffusion suffers from torpid mixing. We address this problem by combining Langevin diffusion with simulated tempering. The result is a Markov chain that mixes more rapidly by transitioning between different temperatures of the distribution. We analyze this Markov chain for the canonical multi-modal distribution: a mixture of gaussians (of equal variance). The algorithm based on our Markov chain provably samples from distributions that are close to mixtures of gaussians, given access to the gradient of the log-pdf. For the analysis, we use a spectral decomposition theorem for graphs (Gharan and Trevisan, 2014) and a Markov chain decomposition technique (Madras and Randall, 2002).
On the ability of neural nets to express distributions
Jun 02, 2017Deep neural nets have caused a revolution in many classification tasks. A related ongoing revolution---also theoretically not understood---concerns their ability to serve as generative models for complicated types of data such as images and texts. These models are trained using ideas like variational autoencoders and Generative Adversarial Networks. We take a first cut at explaining the expressivity of multilayer nets by giving a sufficient criterion for a function to be approximable by a neural network with $n$ hidden layers. A key ingredient is Barron's Theorem \cite{Barron1993}, which gives a Fourier criterion for approximability of a function by a neural network with 1 hidden layer. We show that a composition of $n$ functions which satisfy certain Fourier conditions ("Barron functions") can be approximated by a $n+1$-layer neural network. For probability distributions, this translates into a criterion for a probability distribution to be approximable in Wasserstein distance---a natural metric on probability distributions---by a neural network applied to a fixed base distribution (e.g., multivariate gaussian). Building up recent lower bound work, we also give an example function that shows that composition of Barron functions is more expressive than Barron functions alone.