 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Analysis of Score-based Generative Modeling: User-Friendly Bounds under Minimal Smoothness Assumptions
Nov 03, 2022In this paper, we focus on the theoretical analysis of diffusion-based generative modeling. Under an $L^2$-accurate score estimator, we provide convergence guarantees with polynomial complexity for any data distribution with second-order moment, by either employing an early stopping technique or assuming smoothness condition on the score function of the data distribution. Our result does not rely on any log-concavity or functional inequality assumption and has a logarithmic dependence on the smoothness. In particular, we show that under only a finite second moment condition, approximating the following in KL divergence in $\epsilon$-accuracy can be done in $\tilde O\left(\frac{d^2 \log^2 (1/\delta)}{\epsilon^2}\right)$ steps: 1) the variance-$\delta$ Gaussian perturbation of any data distribution; 2) data distributions with $1/\delta$-smooth score functions. Our theoretical analysis also provides quantitative comparison between different discrete approximations and may guide the choice of discretization points in practice.
Fisher information lower bounds for sampling
Oct 05, 2022We prove two lower bounds for the complexity of non-log-concave sampling within the framework of Balasubramanian et al. (2022), who introduced the use of Fisher information (FI) bounds as a notion of approximate first-order stationarity in sampling. Our first lower bound shows that averaged LMC is optimal for the regime of large FI by reducing the problem of finding stationary points in non-convex optimization to sampling. Our second lower bound shows that in the regime of small FI, obtaining a FI of at most $\varepsilon^2$ from the target distribution requires $\text{poly}(1/\varepsilon)$ queries, which is surprising as it rules out the existence of high-accuracy algorithms (e.g., algorithms using Metropolis-Hastings filters) in this context.
Convergence of score-based generative modeling for general data distributions
Oct 03, 2022Score-based generative modeling (SGM) has grown to be a hugely successful method for learning to generate samples from complex data distributions such as that of images and audio. It is based on evolving an SDE that transforms white noise into a sample from the learned distribution, using estimates of the score function, or gradient log-pdf. Previous convergence analyses for these methods have suffered either from strong assumptions on the data distribution or exponential dependencies, and hence fail to give efficient guarantees for the multimodal and non-smooth distributions that arise in practice and for which good empirical performance is observed. We consider a popular kind of SGM -- denoising diffusion models -- and give polynomial convergence guarantees for general data distributions, with no assumptions related to functional inequalities or smoothness. Assuming $L^2$-accurate score estimates, we obtain Wasserstein distance guarantees for any distribution of bounded support or sufficiently decaying tails, as well as TV guarantees for distributions with further smoothness assumptions.
Pitfalls of Gaussians as a noise distribution in NCE
Oct 01, 2022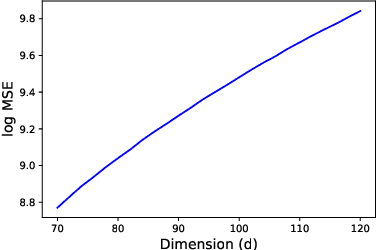
Noise Contrastive Estimation (NCE) is a popular approach for learning probability density functions parameterized up to a constant of proportionality. The main idea is to design a classification problem for distinguishing training data from samples from an easy-to-sample noise distribution $q$, in a manner that avoids having to calculate a partition function. It is well-known that the choice of $q$ can severely impact the computational and statistical efficiency of NCE. In practice, a common choice for $q$ is a Gaussian which matches the mean and covariance of the data. In this paper, we show that such a choice can result in an exponentially bad (in the ambient dimension) conditioning of the Hessian of the loss, even for very simple data distributions. As a consequence, both the statistical and algorithmic complexity for such a choice of $q$ will be problematic in practice, suggesting that more complex noise distributions are essential to the success of NCE.
Convergence for score-based generative modeling with polynomial complexity
Jun 13, 2022Score-based generative modeling (SGM) is a highly successful approach for learning a probability distribution from data and generating further samples. We prove the first polynomial convergence guarantees for the core mechanic behind SGM: drawing samples from a probability density $p$ given a score estimate (an estimate of $\nabla \ln p$) that is accurate in $L^2(p)$. Compared to previous works, we do not incur error that grows exponentially in time or that suffers from a curse of dimensionality. Our guarantee works for any smooth distribution and depends polynomially on its log-Sobolev constant. Using our guarantee, we give a theoretical analysis of score-based generative modeling, which transforms white-noise input into samples from a learned data distribution given score estimates at different noise scales. Our analysis gives theoretical grounding to the observation that an annealed procedure is required in practice to generate good samples, as our proof depends essentially on using annealing to obtain a warm start at each step. Moreover, we show that a predictor-corrector algorithm gives better convergence than using either portion alone.
Sampling Approximately Low-Rank Ising Models: MCMC meets Variational Methods
Feb 17, 2022We consider Ising models on the hypercube with a general interaction matrix $J$, and give a polynomial time sampling algorithm when all but $O(1)$ eigenvalues of $J$ lie in an interval of length one, a situation which occurs in many models of interest. This was previously known for the Glauber dynamics when *all* eigenvalues fit in an interval of length one; however, a single outlier can force the Glauber dynamics to mix torpidly. Our general result implies the first polynomial time sampling algorithms for low-rank Ising models such as Hopfield networks with a fixed number of patterns and Bayesian clustering models with low-dimensional contexts, and greatly improves the polynomial time sampling regime for the antiferromagnetic/ferromagnetic Ising model with inconsistent field on expander graphs. It also improves on previous approximation algorithm results based on the naive mean-field approximation in variational methods and statistical physics. Our approach is based on a new fusion of ideas from the MCMC and variational inference worlds. As part of our algorithm, we define a new nonconvex variational problem which allows us to sample from an exponential reweighting of a distribution by a negative definite quadratic form, and show how to make this procedure provably efficient using stochastic gradient descent. On top of this, we construct a new simulated tempering chain (on an extended state space arising from the Hubbard-Stratonovich transform) which overcomes the obstacle posed by large positive eigenvalues, and combine it with the SGD-based sampler to solve the full problem.
Universal Approximation for Log-concave Distributions using Well-conditioned Normalizing Flows
Jul 07, 2021Normalizing flows are a widely used class of latent-variable generative models with a tractable likelihood. Affine-coupling (Dinh et al, 2014-16) models are a particularly common type of normalizing flows, for which the Jacobian of the latent-to-observable-variable transformation is triangular, allowing the likelihood to be computed in linear time. Despite the widespread usage of affine couplings, the special structure of the architecture makes understanding their representational power challenging. The question of universal approximation was only recently resolved by three parallel papers (Huang et al.,2020;Zhang et al.,2020;Koehler et al.,2020) -- who showed reasonably regular distributions can be approximated arbitrarily well using affine couplings -- albeit with networks with a nearly-singular Jacobian. As ill-conditioned Jacobians are an obstacle for likelihood-based training, the fundamental question remains: which distributions can be approximated using well-conditioned affine coupling flows? In this paper, we show that any log-concave distribution can be approximated using well-conditioned affine-coupling flows. In terms of proof techniques, we uncover and leverage deep connections between affine coupling architectures, underdamped Langevin dynamics (a stochastic differential equation often used to sample from Gibbs measures) and H\'enon maps (a structured dynamical system that appears in the study of symplectic diffeomorphisms). Our results also inform the practice of training affine couplings: we approximate a padded version of the input distribution with iid Gaussians -- a strategy which Koehler et al.(2020) empirically observed to result in better-conditioned flows, but had hitherto no theoretical grounding. Our proof can thus be seen as providing theoretical evidence for the benefits of Gaussian padding when training normalizing flows.
Improved rates for identification of partially observed linear dynamical systems
Nov 19, 2020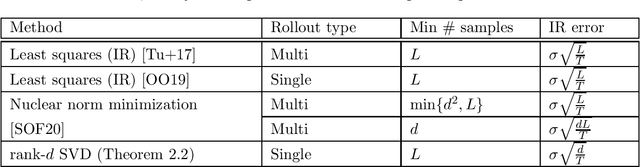
Identification of a linear time-invariant dynamical system from partial observations is a fundamental problem in control theory. A natural question is how to do so with non-asymptotic statistical rates depending on the inherent dimensionality (order) $d$ of the system, rather than on the sufficient rollout length or on $\frac1{1-\rho(A)}$, where $\rho(A)$ is the spectral radius of the dynamics matrix. We develop the first algorithm that given a single trajectory of length $T$ with gaussian observation noise, achieves a near-optimal rate of $\widetilde O\left(\sqrt\frac{d}{T}\right)$ in $\mathcal{H}_2$ error for the learned system. We also give bounds under process noise and improved bounds for learning a realization of the system. Our algorithm is based on low-rank approximation of Hankel matrices of geometrically increasing sizes.
Efficient sampling from the Bingham distribution
Sep 30, 2020We give a algorithm for exact sampling from the Bingham distribution $p(x)\propto \exp(x^\top A x)$ on the sphere $\mathcal S^{d-1}$ with expected runtime of $\operatorname{poly}(d, \lambda_{\max}(A)-\lambda_{\min}(A))$. The algorithm is based on rejection sampling, where the proposal distribution is a polynomial approximation of the pdf, and can be sampled from by explicitly evaluating integrals of polynomials over the sphere. Our algorithm gives exact samples, assuming exact computation of an inverse function of a polynomial. This is in contrast with Markov Chain Monte Carlo algorithms, which are not known to enjoy rapid mixing on this problem, and only give approximate samples. As a direct application, we use this to sample from the posterior distribution of a rank-1 matrix inference problem in polynomial time.
No-Regret Prediction in Marginally Stable Systems
Feb 20, 2020We consider the problem of online prediction in a marginally stable linear dynamical system subject to bounded adversarial or (non-isotropic) stochastic perturbations. This poses two challenges. Firstly, the system is in general unidentifiable, so recent and classical results on parameter recovery do not apply. Secondly, because we allow the system to be marginally stable, the state can grow polynomially with time; this causes standard regret bounds in online convex optimization to be vacuous. In spite of these challenges, we show that the online least-squares algorithm achieves sublinear regret (improvable to polylogarithmic in the stochastic setting), with polynomial dependence on the system's parameters. This requires a refined regret analysis, including a structural lemma showing the current state of the system to be a small linear combination of past states, even if the state grows polynomially. By applying our techniques to learning an autoregressive filter, we also achieve logarithmic regret in the partially observed setting under Gaussian noise, with polynomial dependence on the memory of the associated Kalman filter.