 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntention-Aware Navigation in Crowds with Extended-Space POMDP Planning
Jun 20, 2022
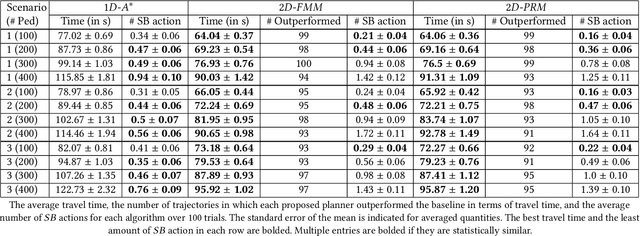
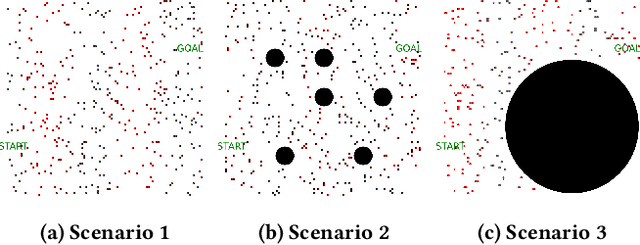
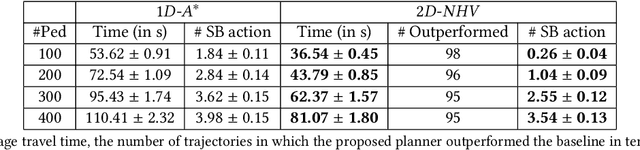
This paper presents a hybrid online Partially Observable Markov Decision Process (POMDP) planning system that addresses the problem of autonomous navigation in the presence of multi-modal uncertainty introduced by other agents in the environment. As a particular example, we consider the problem of autonomous navigation in dense crowds of pedestrians and among obstacles. Popular approaches to this problem first generate a path using a complete planner (e.g., Hybrid A*) with ad-hoc assumptions about uncertainty, then use online tree-based POMDP solvers to reason about uncertainty with control over a limited aspect of the problem (i.e. speed along the path). We present a more capable and responsive real-time approach enabling the POMDP planner to control more degrees of freedom (e.g., both speed AND heading) to achieve more flexible and efficient solutions. This modification greatly extends the region of the state space that the POMDP planner must reason over, significantly increasing the importance of finding effective roll-out policies within the limited computational budget that real time control affords. Our key insight is to use multi-query motion planning techniques (e.g., Probabilistic Roadmaps or Fast Marching Method) as priors for rapidly generating efficient roll-out policies for every state that the POMDP planning tree might reach during its limited horizon search. Our proposed approach generates trajectories that are safe and significantly more efficient than the previous approach, even in densely crowded dynamic environments with long planning horizons.
Surgical Phase Recognition in Laparoscopic Cholecystectomy
Jun 14, 2022
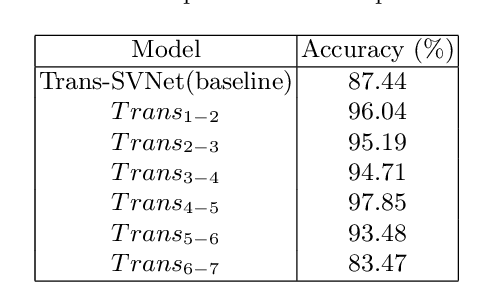
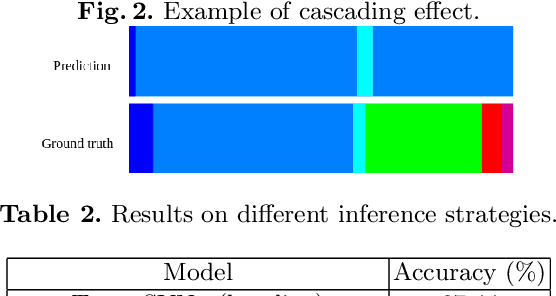

Automatic recognition of surgical phases in surgical videos is a fundamental task in surgical workflow analysis. In this report, we propose a Transformer-based method that utilizes calibrated confidence scores for a 2-stage inference pipeline, which dynamically switches between a baseline model and a separately trained transition model depending on the calibrated confidence level. Our method outperforms the baseline model on the Cholec80 dataset, and can be applied to a variety of action segmentation methods.
Hollywood Identity Bias Dataset: A Context Oriented Bias Analysis of Movie Dialogues
Jun 01, 2022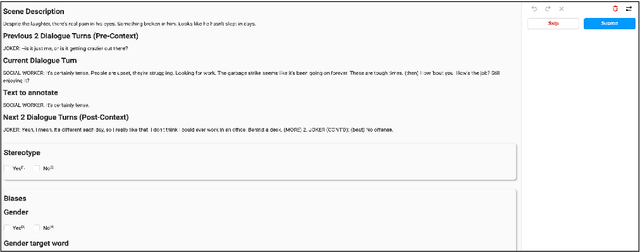
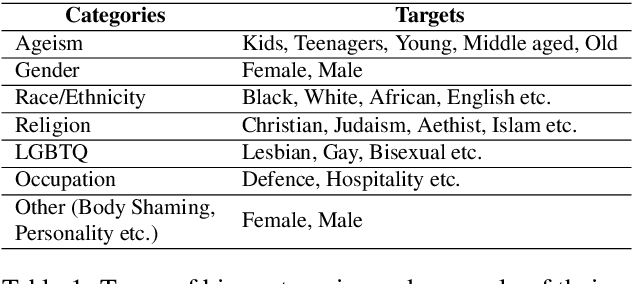

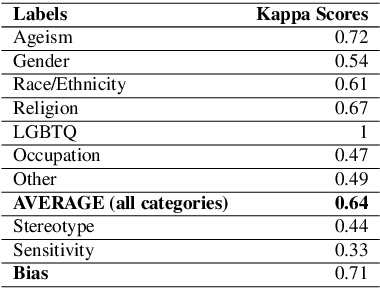
Movies reflect society and also hold power to transform opinions. Social biases and stereotypes present in movies can cause extensive damage due to their reach. These biases are not always found to be the need of storyline but can creep in as the author's bias. Movie production houses would prefer to ascertain that the bias present in a script is the story's demand. Today, when deep learning models can give human-level accuracy in multiple tasks, having an AI solution to identify the biases present in the script at the writing stage can help them avoid the inconvenience of stalled release, lawsuits, etc. Since AI solutions are data intensive and there exists no domain specific data to address the problem of biases in scripts, we introduce a new dataset of movie scripts that are annotated for identity bias. The dataset contains dialogue turns annotated for (i) bias labels for seven categories, viz., gender, race/ethnicity, religion, age, occupation, LGBTQ, and other, which contains biases like body shaming, personality bias, etc. (ii) labels for sensitivity, stereotype, sentiment, emotion, emotion intensity, (iii) all labels annotated with context awareness, (iv) target groups and reason for bias labels and (v) expert-driven group-validation process for high quality annotations. We also report various baseline performances for bias identification and category detection on our dataset.
DeepAlloc: CNN-Based Approach to Efficient Spectrum Allocation in Shared Spectrum Systems
Jan 19, 2022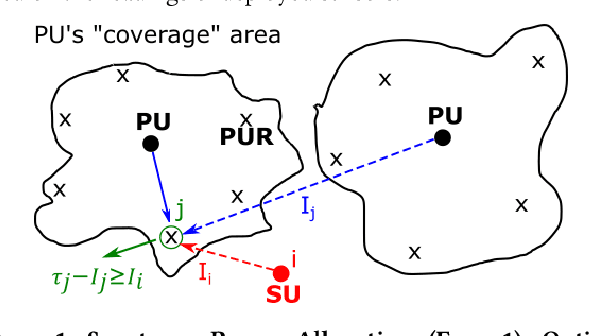
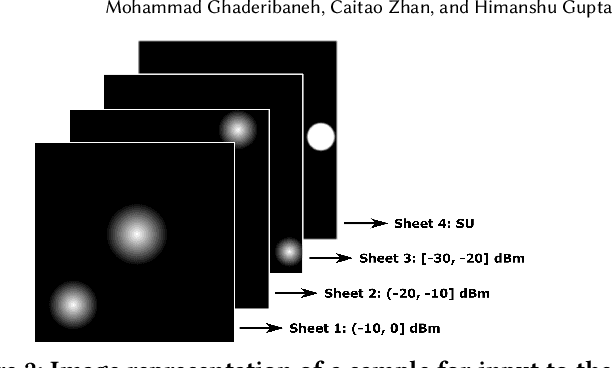
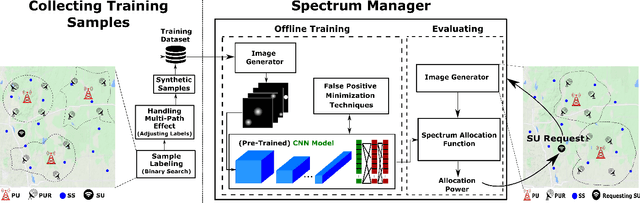
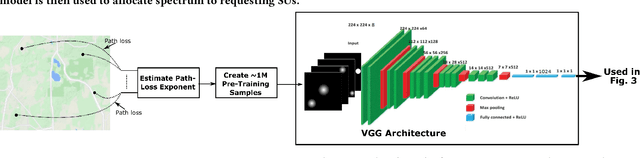
Shared spectrum systems facilitate spectrum allocation to unlicensed users without harming the licensed users; they offer great promise in optimizing spectrum utility, but their management (in particular, efficient spectrum allocation to unlicensed users) is challenging. A significant shortcoming of current allocation methods is that they are either done very conservatively to ensure correctness, or are based on imperfect propagation models and/or spectrum sensing with poor spatial granularity. This leads to poor spectrum utilization, the fundamental objective of shared spectrum systems. To allocate spectrum near-optimally to secondary users in general scenarios, we fundamentally need to have knowledge of the signal path-loss function. In practice, however, even the best known path-loss models have unsatisfactory accuracy, and conducting extensive surveys to gather path-loss values is infeasible. To circumvent this challenge, we propose to learn the spectrum allocation function directly using supervised learning techniques. We particularly address the scenarios when the primary users' information may not be available; for such settings, we make use of a crowdsourced sensing architecture and use the spectrum sensor readings as features. We develop an efficient CNN-based approach (called DeepAlloc) and address various challenges that arise in its application to the learning the spectrum allocation function. Via extensive large-scale simulation and a small testbed, we demonstrate the effectiveness of our developed techniques; in particular, we observe that our approach improves the accuracy of standard learning techniques and prior work by up to 60%.
Zero-Shot Open Information Extraction using Question Generation and Reading Comprehension
Sep 16, 2021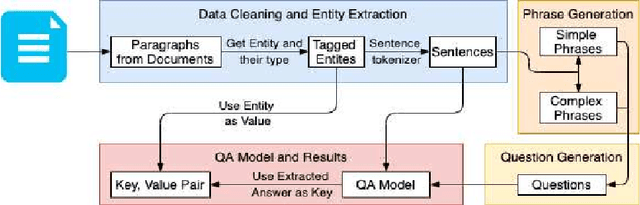
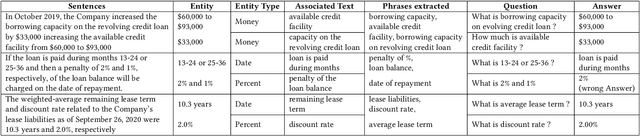
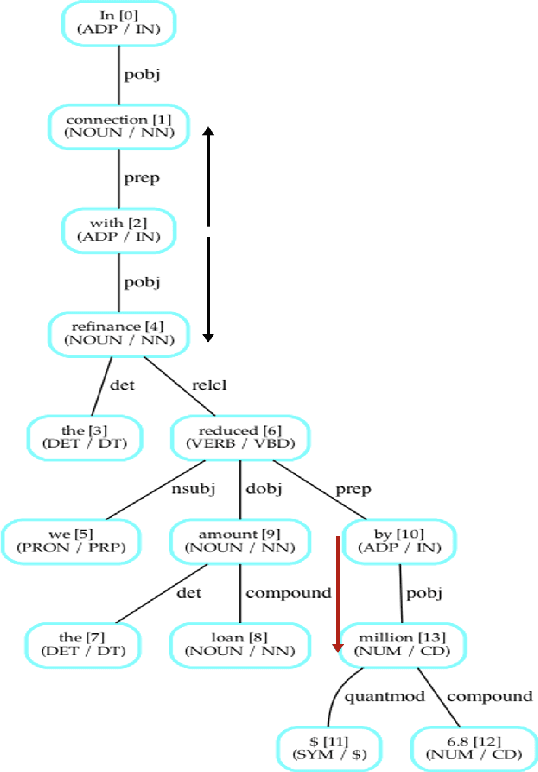
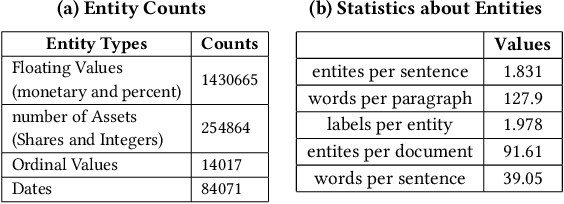
Typically, Open Information Extraction (OpenIE) focuses on extracting triples, representing a subject, a relation, and the object of the relation. However, most of the existing techniques are based on a predefined set of relations in each domain which limits their applicability to newer domains where these relations may be unknown such as financial documents. This paper presents a zero-shot open information extraction technique that extracts the entities (value) and their descriptions (key) from a sentence, using off the shelf machine reading comprehension (MRC) Model. The input questions to this model are created using a novel noun phrase generation method. This method takes the context of the sentence into account and can create a wide variety of questions making our technique domain independent. Given the questions and the sentence, our technique uses the MRC model to extract entities (value). The noun phrase corresponding to the question, with the highest confidence, is taken as the description (key). This paper also introduces the EDGAR10-Q dataset which is based on publicly available financial documents from corporations listed in US securities and exchange commission (SEC). The dataset consists of paragraphs, tagged values (entities), and their keys (descriptions) and is one of the largest among entity extraction datasets. This dataset will be a valuable addition to the research community, especially in the financial domain. Finally, the paper demonstrates the efficacy of the proposed technique on the EDGAR10-Q and Ade corpus drug dosage datasets, where it obtained 86.84 % and 97% accuracy, respectively.
An Empirical Study on Predictability of Software Code Smell Using Deep Learning Models
Aug 08, 2021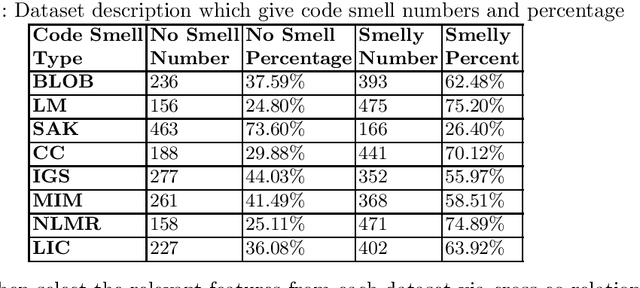
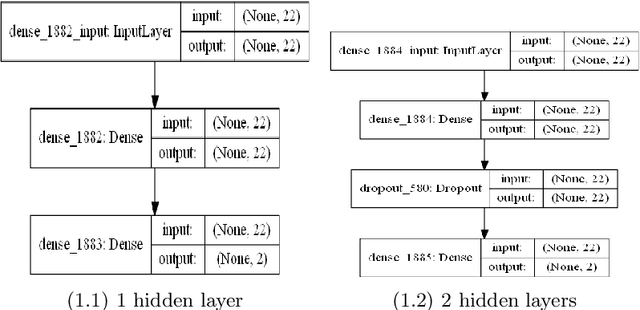
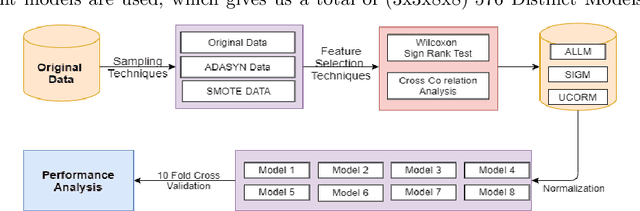
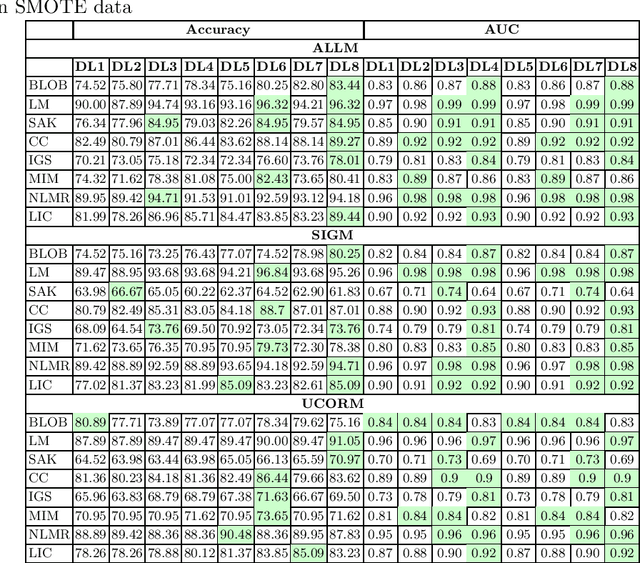
Code Smell, similar to a bad smell, is a surface indication of something tainted but in terms of software writing practices. This metric is an indication of a deeper problem lies within the code and is associated with an issue which is prominent to experienced software developers with acceptable coding practices. Recent studies have often observed that codes having code smells are often prone to a higher probability of change in the software development cycle. In this paper, we developed code smell prediction models with the help of features extracted from source code to predict eight types of code smell. Our work also presents the application of data sampling techniques to handle class imbalance problem and feature selection techniques to find relevant feature sets. Previous studies had made use of techniques such as Naive - Bayes and Random forest but had not explored deep learning methods to predict code smell. A total of 576 distinct Deep Learning models were trained using the features and datasets mentioned above. The study concluded that the deep learning models which used data from Synthetic Minority Oversampling Technique gave better results in terms of accuracy, AUC with the accuracy of some models improving from 88.47 to 96.84.
* 12 pages, 6 Figures, 3 Tables, Accepted in the 35th International Conference on Advanced Information Networking and Applications (AINA-2021)
Empirical Analysis on Effectiveness of NLP Methods for Predicting Code Smell
Aug 08, 2021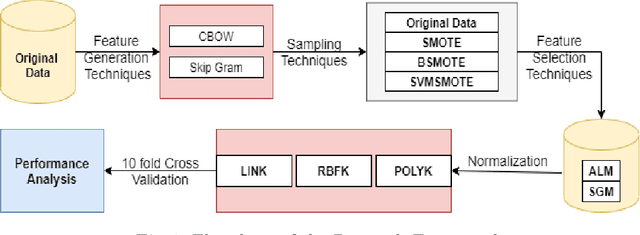

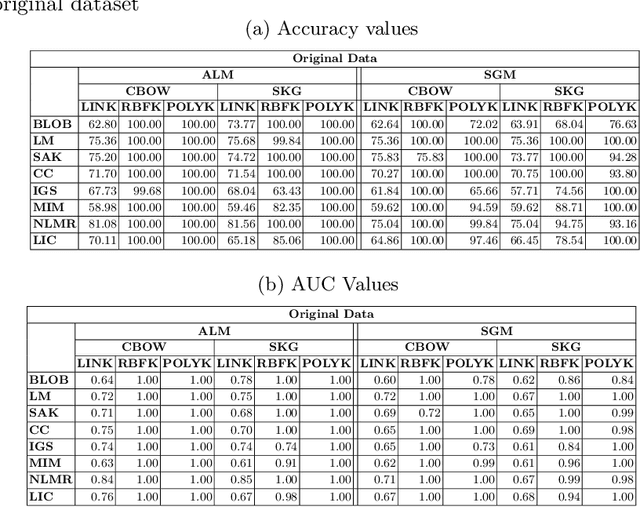
A code smell is a surface indicator of an inherent problem in the system, most often due to deviation from standard coding practices on the developers part during the development phase. Studies observe that code smells made the code more susceptible to call for modifications and corrections than code that did not contain code smells. Restructuring the code at the early stage of development saves the exponentially increasing amount of effort it would require to address the issues stemming from the presence of these code smells. Instead of using traditional features to detect code smells, we use user comments to manually construct features to predict code smells. We use three Extreme learning machine kernels over 629 packages to identify eight code smells by leveraging feature engineering aspects and using sampling techniques. Our findings indicate that the radial basis functional kernel performs best out of the three kernel methods with a mean accuracy of 98.52.
Prediction of Students performance with Artificial Neural Network using Demographic Traits
Aug 08, 2021
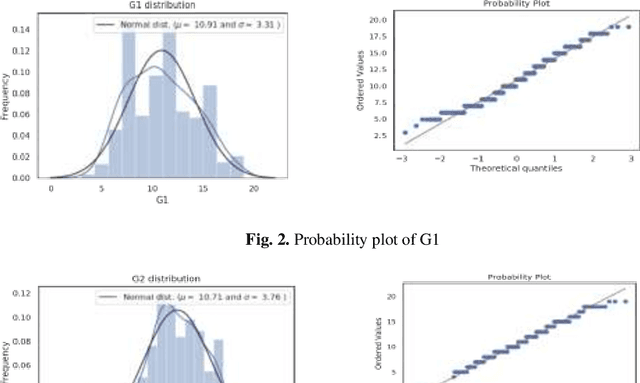


Many researchers have studied student academic performance in supervised and unsupervised learning using numerous data mining techniques. Neural networks often need a greater collection of observations to achieve enough predictive ability. Due to the increase in the rate of poor graduates, it is necessary to design a system that helps to reduce this menace as well as reduce the incidence of students having to repeat due to poor performance or having to drop out of school altogether in the middle of the pursuit of their career. It is therefore necessary to study each one as well as their advantages and disadvantages, so as to determine which is more efficient in and in what case one should be preferred over the other. The study aims to develop a system to predict student performance with Artificial Neutral Network using the student demographic traits so as to assist the university in selecting candidates (students) with a high prediction of success for admission using previous academic records of students granted admissions which will eventually lead to quality graduates of the institution. The model was developed based on certain selected variables as the input. It achieved an accuracy of over 92.3 percent, showing Artificial Neural Network potential effectiveness as a predictive tool and a selection criterion for candidates seeking admission to a university.
DSC IIT-ISM at SemEval-2020 Task 8: Bi-Fusion Techniques for Deep Meme Emotion Analysis
Jul 28, 2020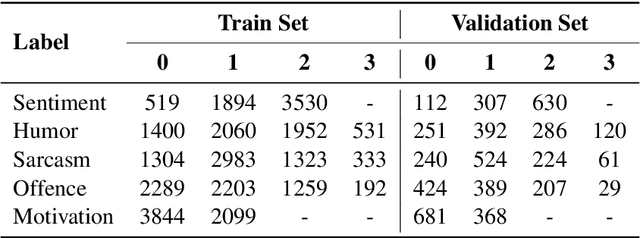
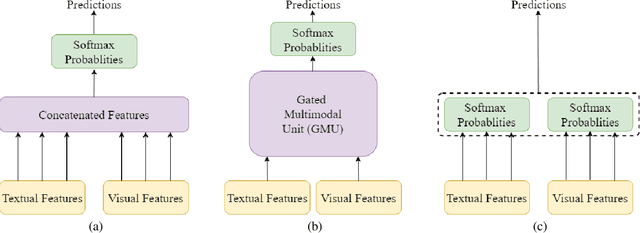
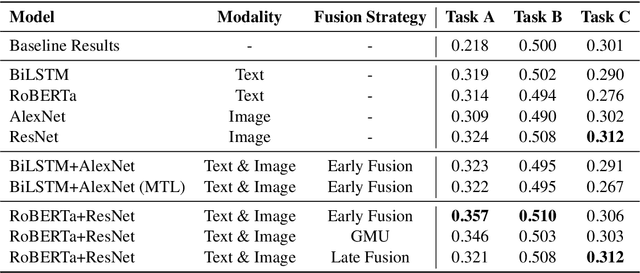

Memes have become an ubiquitous social media entity and the processing and analysis of suchmultimodal data is currently an active area of research. This paper presents our work on theMemotion Analysis shared task of SemEval 2020, which involves the sentiment and humoranalysis of memes. We propose a system which uses different bimodal fusion techniques toleverage the inter-modal dependency for sentiment and humor classification tasks. Out of all ourexperiments, the best system improved the baseline with macro F1 scores of 0.357 on SentimentClassification (Task A), 0.510 on Humor Classification (Task B) and 0.312 on Scales of SemanticClasses (Task C).