 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategic Prompting for Conversational Tasks: A Comparative Analysis of Large Language Models Across Diverse Conversational Tasks
Nov 26, 2024



Given the advancements in conversational artificial intelligence, the evaluation and assessment of Large Language Models (LLMs) play a crucial role in ensuring optimal performance across various conversational tasks. In this paper, we present a comprehensive study that thoroughly evaluates the capabilities and limitations of five prevalent LLMs: Llama, OPT, Falcon, Alpaca, and MPT. The study encompasses various conversational tasks, including reservation, empathetic response generation, mental health and legal counseling, persuasion, and negotiation. To conduct the evaluation, an extensive test setup is employed, utilizing multiple evaluation criteria that span from automatic to human evaluation. This includes using generic and task-specific metrics to gauge the LMs' performance accurately. From our evaluation, no single model emerges as universally optimal for all tasks. Instead, their performance varies significantly depending on the specific requirements of each task. While some models excel in certain tasks, they may demonstrate comparatively poorer performance in others. These findings emphasize the importance of considering task-specific requirements and characteristics when selecting the most suitable LM for conversational applications.
INA: An Integrative Approach for Enhancing Negotiation Strategies with Reward-Based Dialogue System
Oct 27, 2023



In this paper, we propose a novel negotiation dialogue agent designed for the online marketplace. Our agent is integrative in nature i.e, it possesses the capability to negotiate on price as well as other factors, such as the addition or removal of items from a deal bundle, thereby offering a more flexible and comprehensive negotiation experience. We create a new dataset called Integrative Negotiation Dataset (IND) to enable this functionality. For this dataset creation, we introduce a new semi-automated data creation method, which combines defining negotiation intents, actions, and intent-action simulation between users and the agent to generate potential dialogue flows. Finally, the prompting of GPT-J, a state-of-the-art language model, is done to generate dialogues for a given intent, with a human-in-the-loop process for post-editing and refining minor errors to ensure high data quality. We employ a set of novel rewards, specifically tailored for the negotiation task to train our Negotiation Agent, termed as the Integrative Negotiation Agent (INA). These rewards incentivize the chatbot to learn effective negotiation strategies that can adapt to various contextual requirements and price proposals. By leveraging the IND, we train our model and conduct experiments to evaluate the effectiveness of our reward-based dialogue system for negotiation. Our results demonstrate that the proposed approach and reward system significantly enhance the agent's negotiation capabilities. The INA successfully engages in integrative negotiations, displaying the ability to dynamically adjust prices and negotiate the inclusion or exclusion of items in a bundle deal
Hollywood Identity Bias Dataset: A Context Oriented Bias Analysis of Movie Dialogues
Jun 01, 2022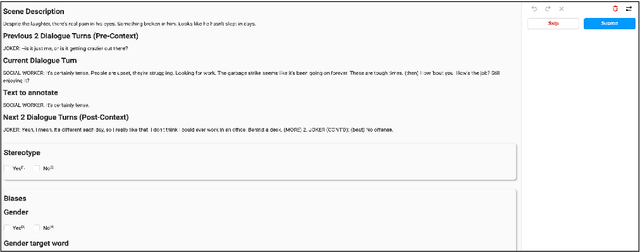
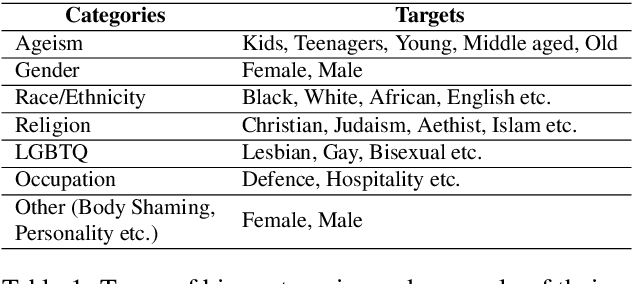

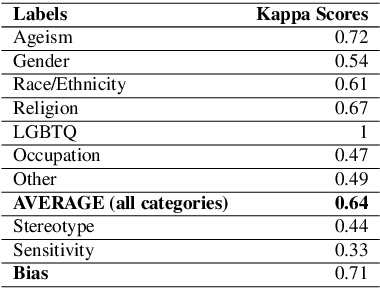
Movies reflect society and also hold power to transform opinions. Social biases and stereotypes present in movies can cause extensive damage due to their reach. These biases are not always found to be the need of storyline but can creep in as the author's bias. Movie production houses would prefer to ascertain that the bias present in a script is the story's demand. Today, when deep learning models can give human-level accuracy in multiple tasks, having an AI solution to identify the biases present in the script at the writing stage can help them avoid the inconvenience of stalled release, lawsuits, etc. Since AI solutions are data intensive and there exists no domain specific data to address the problem of biases in scripts, we introduce a new dataset of movie scripts that are annotated for identity bias. The dataset contains dialogue turns annotated for (i) bias labels for seven categories, viz., gender, race/ethnicity, religion, age, occupation, LGBTQ, and other, which contains biases like body shaming, personality bias, etc. (ii) labels for sensitivity, stereotype, sentiment, emotion, emotion intensity, (iii) all labels annotated with context awareness, (iv) target groups and reason for bias labels and (v) expert-driven group-validation process for high quality annotations. We also report various baseline performances for bias identification and category detection on our dataset.
Can Taxonomy Help? Improving Semantic Question Matching using Question Taxonomy
Jan 20, 2021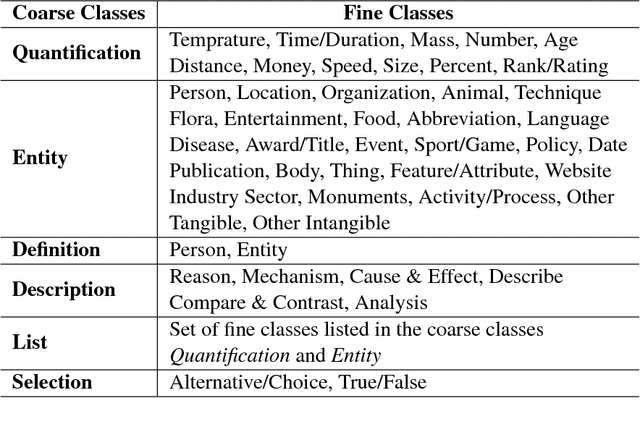
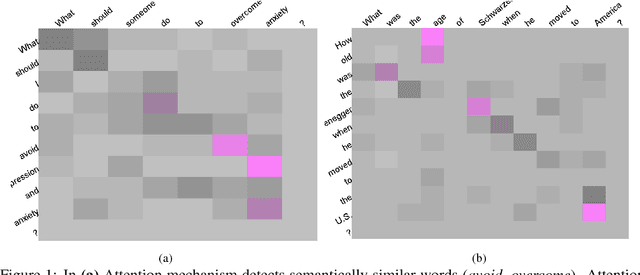
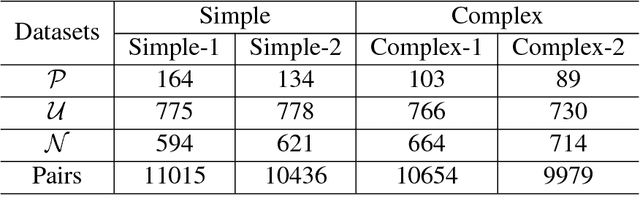
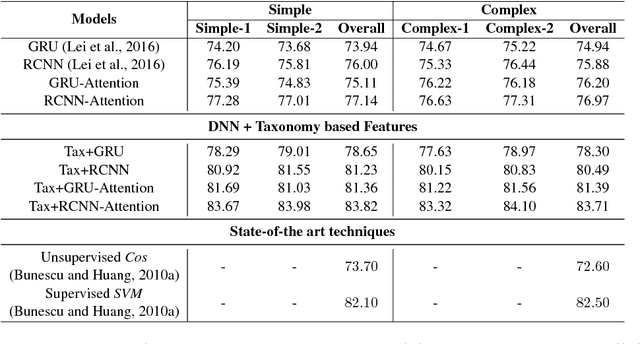
In this paper, we propose a hybrid technique for semantic question matching. It uses our proposed two-layered taxonomy for English questions by augmenting state-of-the-art deep learning models with question classes obtained from a deep learning based question classifier. Experiments performed on three open-domain datasets demonstrate the effectiveness of our proposed approach. We achieve state-of-the-art results on partial ordering question ranking (POQR) benchmark dataset. Our empirical analysis shows that coupling standard distributional features (provided by the question encoder) with knowledge from taxonomy is more effective than either deep learning (DL) or taxonomy-based knowledge alone.