 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Multi-Robot Motion Planning with Precomputed Translation-Invariant Edge Bundles
May 10, 2026Solving multi-robot motion planning (MRMP) requires generating collision-free kinodynamically feasible trajectories for multiple interacting robots. We introduce Kinodynamic Translation-Invariant Edge Bundles or KiTE-Extend, a planner-agnostic action selection mechanism for sampling-based kinodynamic motion planning. KiTE-Extend uses a library of trajectory segments computed offline to guide action selection during online planning, improving the ability of existing planners to identify feasible motion segments without altering state propagation, collision checking, or cost evaluation, and without changing their theoretical guarantees. While KiTE-Extend can modestly improve single-agent planners, its benefits are most clear in the multi-agent setting, where it is able to explore more effectively and significantly improve planning through the dense spatiotemporal constraints introduced by robot-robot interaction. Through experiments on multiple kinodynamic systems and environments, we show that KiTE-Extend reduces planning time and improves scalability across the three most common MRMP paradigms: centralized, prioritized, and conflict-based.
Robustness Analysis of POMDP Policies to Observation Perturbations
Apr 23, 2026Policies for Partially Observable Markov Decision Processes (POMDPs) are often designed using a nominal system model. In practice, this model can deviate from the true system during deployment due to factors such as calibration drift or sensor degradation, leading to unexpected performance degradation. This work studies policy robustness against deviations in the POMDP observation model. We introduce the Policy Observation Robustness Problem: to determine the maximum tolerable deviation in a POMDP's observation model that guarantees the policy's value remains above a specified threshold. We analyze two variants: the sticky variant, where deviations are dependent on state and actions, and the non-sticky variant, where they can be history-dependent. We show that the Policy Observation Robustness Problem can be formulated as a bi-level optimization problem in which the inner optimization is monotonic in the size of the observation deviation. This enables efficient solutions using root-finding algorithms in the outer optimization. For the non-sticky variant, we show that when policies are represented with finite-state controllers (FSCs) it is sufficient to consider observations which depend on nodes in the FSC rather than full histories. We present Robust Interval Search, an algorithm with soundness and convergence guarantees, for both the sticky and non-sticky variants. We show this algorithm has polynomial time complexity in the non-sticky variant and at most exponential time complexity in the sticky variant. We provide experimental results validating and demonstrating the scalability of implementations of Robust Interval Search to POMDP problems with tens of thousands of states. We also provide case studies from robotics and operations research which demonstrate the practical utility of the problem and algorithms.
Leveraging the Value of Information in POMDP Planning
Apr 01, 2026Partially observable Markov decision processes (POMDPs) offer a principled formalism for planning under state and transition uncertainty. Despite advances made towards solving large POMDPs, obtaining performant policies under limited planning time remains a major challenge due to the curse of dimensionality and the curse of history. For many POMDP problems, the value of information (VOI) - the expected performance gain from reasoning about observations - varies over the belief space. We introduce a dynamic programming framework that exploits this structure by conditionally processing observations based on the value of information at each belief. Building on this framework, we propose Value of Information Monte Carlo planning (VOIMCP), a Monte Carlo Tree Search algorithm that allocates computational effort more efficiently by selectively disregarding observation information when the VOI is low, avoiding unnecessary branching of observations. We provide theoretical guarantees on the near-optimality of our VOI reasoning framework and derive non-asymptotic convergence bounds for VOIMCP. Simulation evaluations demonstrate that VOIMCP outperforms baselines on several POMDP benchmarks.
Leveraging Counterfactual Paths for Contrastive Explanations of POMDP Policies
Mar 28, 2024


As humans come to rely on autonomous systems more, ensuring the transparency of such systems is important to their continued adoption. Explainable Artificial Intelligence (XAI) aims to reduce confusion and foster trust in systems by providing explanations of agent behavior. Partially observable Markov decision processes (POMDPs) provide a flexible framework capable of reasoning over transition and state uncertainty, while also being amenable to explanation. This work investigates the use of user-provided counterfactuals to generate contrastive explanations of POMDP policies. Feature expectations are used as a means of contrasting the performance of these policies. We demonstrate our approach in a Search and Rescue (SAR) setting. We analyze and discuss the associated challenges through two case studies.
Human-Centered Autonomy for UAS Target Search
Sep 18, 2023



Current methods of deploying robots that operate in dynamic, uncertain environments, such as Uncrewed Aerial Systems in search \& rescue missions, require nearly continuous human supervision for vehicle guidance and operation. These methods do not consider high-level mission context resulting in cumbersome manual operation or inefficient exhaustive search patterns. We present a human-centered autonomous framework that infers geospatial mission context through dynamic feature sets, which then guides a probabilistic target search planner. Operators provide a set of diverse inputs, including priority definition, spatial semantic information about ad-hoc geographical areas, and reference waypoints, which are probabilistically fused with geographical database information and condensed into a geospatial distribution representing an operator's preferences over an area. An online, POMDP-based planner, optimized for target searching, is augmented with this reward map to generate an operator-constrained policy. Our results, simulated based on input from five professional rescuers, display effective task mental model alignment, 18\% more victim finds, and 15 times more efficient guidance plans then current operational methods.
Investigation of risk-aware MDP and POMDP contingency management autonomy for UAS
Apr 03, 2023



Unmanned aircraft systems (UAS) are being increasingly adopted for various applications. The risk UAS poses to people and property must be kept to acceptable levels. This paper proposes risk-aware contingency management autonomy to prevent an accident in the event of component malfunction, specifically propulsion unit failure and/or battery degradation. The proposed autonomy is modeled as a Markov Decision Process (MDP) whose solution is a contingency management policy that appropriately executes emergency landing, flight termination or continuation of planned flight actions. Motivated by the potential for errors in fault/failure indicators, partial observability of the MDP state space is investigated. The performance of optimal policies is analyzed over varying observability conditions in a high-fidelity simulator. Results indicate that both partially observable MDP (POMDP) and maximum a posteriori MDP policies performed similarly over different state observability criteria, given the nearly deterministic state transition model.
Intention-Aware Navigation in Crowds with Extended-Space POMDP Planning
Jun 20, 2022
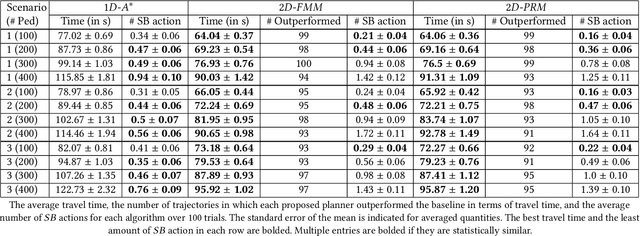
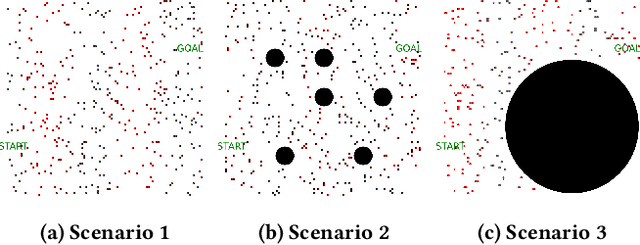
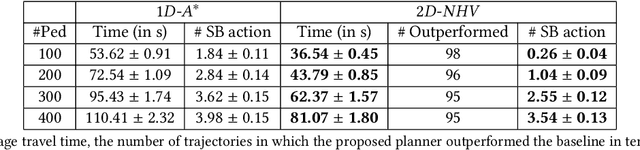
This paper presents a hybrid online Partially Observable Markov Decision Process (POMDP) planning system that addresses the problem of autonomous navigation in the presence of multi-modal uncertainty introduced by other agents in the environment. As a particular example, we consider the problem of autonomous navigation in dense crowds of pedestrians and among obstacles. Popular approaches to this problem first generate a path using a complete planner (e.g., Hybrid A*) with ad-hoc assumptions about uncertainty, then use online tree-based POMDP solvers to reason about uncertainty with control over a limited aspect of the problem (i.e. speed along the path). We present a more capable and responsive real-time approach enabling the POMDP planner to control more degrees of freedom (e.g., both speed AND heading) to achieve more flexible and efficient solutions. This modification greatly extends the region of the state space that the POMDP planner must reason over, significantly increasing the importance of finding effective roll-out policies within the limited computational budget that real time control affords. Our key insight is to use multi-query motion planning techniques (e.g., Probabilistic Roadmaps or Fast Marching Method) as priors for rapidly generating efficient roll-out policies for every state that the POMDP planning tree might reach during its limited horizon search. Our proposed approach generates trajectories that are safe and significantly more efficient than the previous approach, even in densely crowded dynamic environments with long planning horizons.
Bayesian Optimized Monte Carlo Planning
Oct 07, 2020
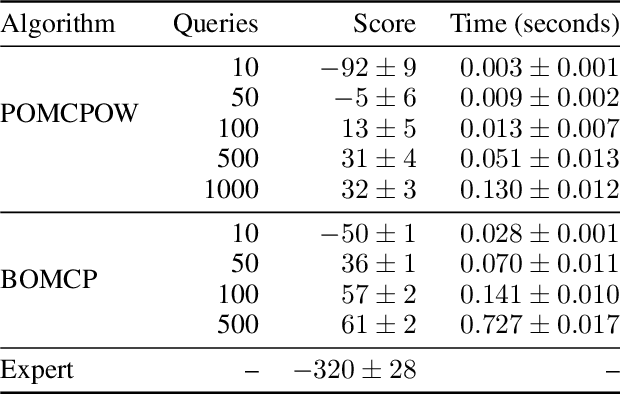
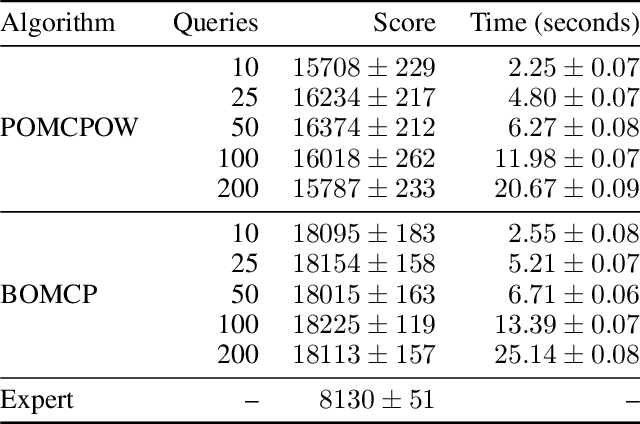
Online solvers for partially observable Markov decision processes have difficulty scaling to problems with large action spaces. Monte Carlo tree search with progressive widening attempts to improve scaling by sampling from the action space to construct a policy search tree. The performance of progressive widening search is dependent upon the action sampling policy, often requiring problem-specific samplers. In this work, we present a general method for efficient action sampling based on Bayesian optimization. The proposed method uses a Gaussian process to model a belief over the action-value function and selects the action that will maximize the expected improvement in the optimal action value. We implement the proposed approach in a new online tree search algorithm called Bayesian Optimized Monte Carlo Planning (BOMCP). Several experiments show that BOMCP is better able to scale to large action space POMDPs than existing state-of-the-art tree search solvers.
Improving Automated Driving through Planning with Human Internal States
May 28, 2020
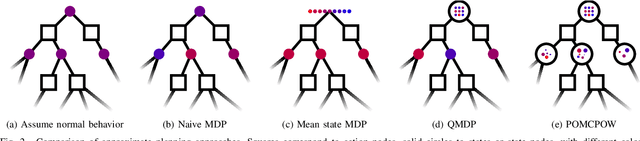
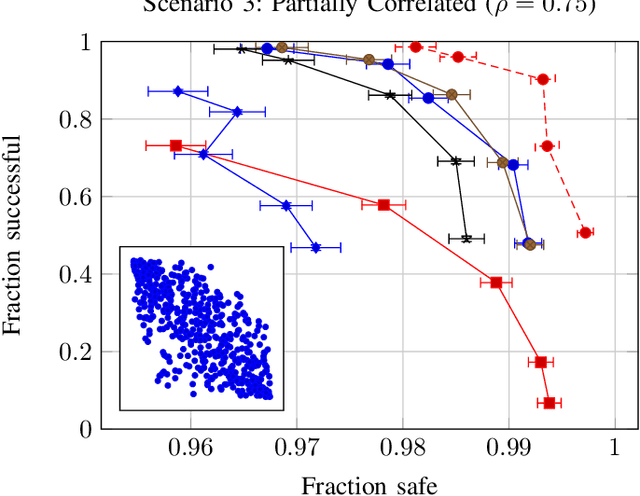
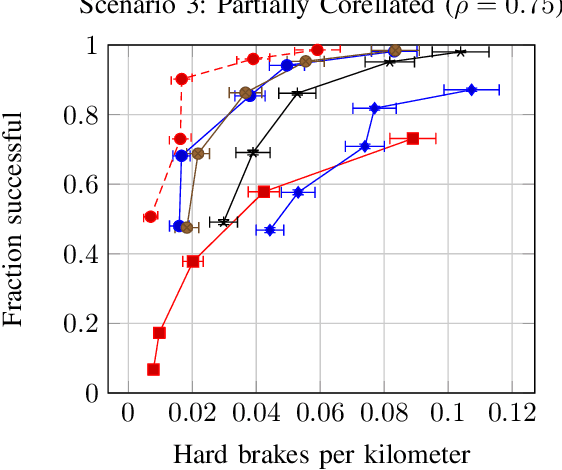
This work examines the hypothesis that partially observable Markov decision process (POMDP) planning with human driver internal states can significantly improve both safety and efficiency in autonomous freeway driving. We evaluate this hypothesis in a simulated scenario where an autonomous car must safely perform three lane changes in rapid succession. Approximate POMDP solutions are obtained through the partially observable Monte Carlo planning with observation widening (POMCPOW) algorithm. This approach outperforms over-confident and conservative MDP baselines and matches or outperforms QMDP. Relative to the MDP baselines, POMCPOW typically cuts the rate of unsafe situations in half or increases the success rate by 50%.
Online algorithms for POMDPs with continuous state, action, and observation spaces
Sep 06, 2018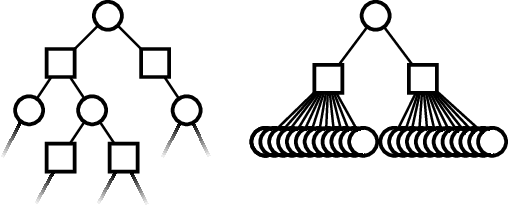
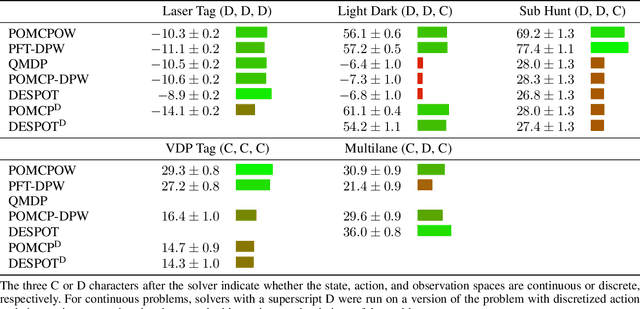
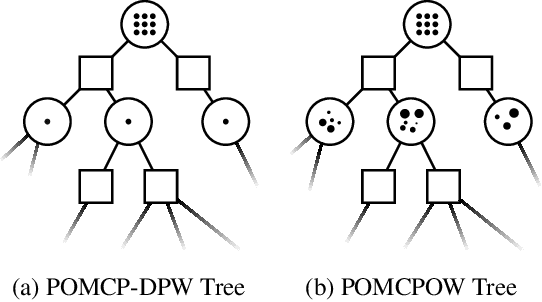
Online solvers for partially observable Markov decision processes have been applied to problems with large discrete state spaces, but continuous state, action, and observation spaces remain a challenge. This paper begins by investigating double progressive widening (DPW) as a solution to this challenge. However, we prove that this modification alone is not sufficient because the belief representations in the search tree collapse to a single particle causing the algorithm to converge to a policy that is suboptimal regardless of the computation time. This paper proposes and evaluates two new algorithms, POMCPOW and PFT-DPW, that overcome this deficiency by using weighted particle filtering. Simulation results show that these modifications allow the algorithms to be successful where previous approaches fail.
* Added Multilane section