 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuthenticity Debt and the Synthetic Content Threat Landscape: A Layered Framework for Trust, Provenance, and IP Governance in the Generative AI Era
May 30, 2026Generative artificial intelligence has fundamentally changed how content is now produced. It has enabled how high-fidelity text, images, audio, and videos are created, modified, and redistributed at near-zero marginal cost. This shift exposes enterprises and ecosystems to a number of risks across four reinforcing authenticity layers -- authenticity, provenance, integrity, and accountability -- that traditional controls are inadequate to address in isolation. We introduce the concept of authenticity debt: the cumulative institutional liability that accumulates when organizations deploy AI-generated content without preserving verifiable origin, integrity, and accountability, deferring exposure that surfaces under regulatory, legal, or market scrutiny. This paper presents a comprehensive, multi-dimensional taxonomy of generative AI harms and attack vectors, surveys the capabilities and failure modes of technical controls including digital watermarking, provenance frameworks (C2PA, Adobe CAI), and detection technologies, and argues that no single mechanism is sufficient in open, adversarial, and evolving environments. Drawing on Zero Trust Architecture principles and enterprise governance frameworks, we propose a layered reference architecture that integrates cryptographic provenance, human-in-the-loop verification, and continuous governance to sustain defensible authenticity at scale. We further examine the regulatory landscape (EU AI Act, U.S.\ FTC, NIST AI RMF) and identify practical guiding principles for organizations seeking to build authenticity as institutional infrastructure rather than an afterthought.
Hollywood Identity Bias Dataset: A Context Oriented Bias Analysis of Movie Dialogues
Jun 01, 2022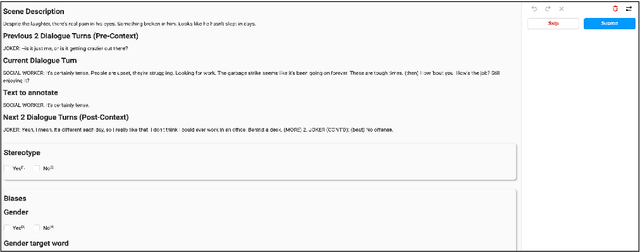
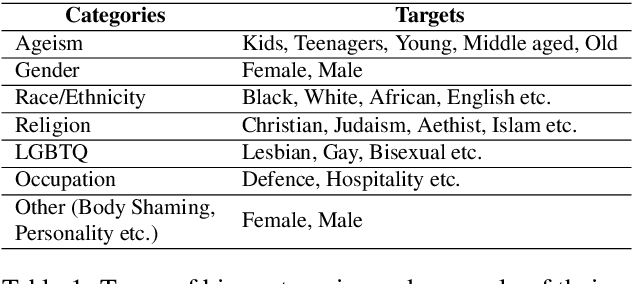

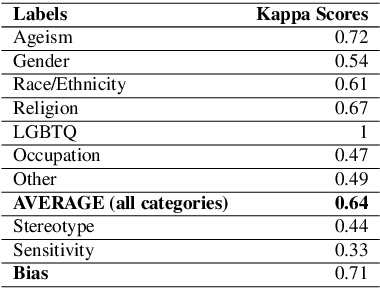
Movies reflect society and also hold power to transform opinions. Social biases and stereotypes present in movies can cause extensive damage due to their reach. These biases are not always found to be the need of storyline but can creep in as the author's bias. Movie production houses would prefer to ascertain that the bias present in a script is the story's demand. Today, when deep learning models can give human-level accuracy in multiple tasks, having an AI solution to identify the biases present in the script at the writing stage can help them avoid the inconvenience of stalled release, lawsuits, etc. Since AI solutions are data intensive and there exists no domain specific data to address the problem of biases in scripts, we introduce a new dataset of movie scripts that are annotated for identity bias. The dataset contains dialogue turns annotated for (i) bias labels for seven categories, viz., gender, race/ethnicity, religion, age, occupation, LGBTQ, and other, which contains biases like body shaming, personality bias, etc. (ii) labels for sensitivity, stereotype, sentiment, emotion, emotion intensity, (iii) all labels annotated with context awareness, (iv) target groups and reason for bias labels and (v) expert-driven group-validation process for high quality annotations. We also report various baseline performances for bias identification and category detection on our dataset.