 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
DSC-IITISM at FinCausal 2021: Combining POS tagging with Attention-based Contextual Representations for Identifying Causal Relationships in Financial Documents
Oct 31, 2021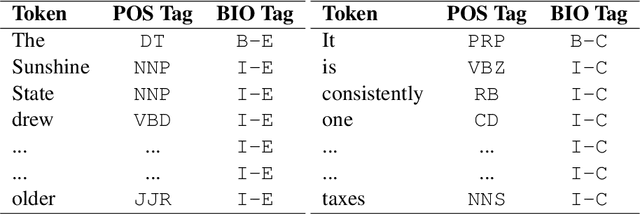


Causality detection draws plenty of attention in the field of Natural Language Processing and linguistics research. It has essential applications in information retrieval, event prediction, question answering, financial analysis, and market research. In this study, we explore several methods to identify and extract cause-effect pairs in financial documents using transformers. For this purpose, we propose an approach that combines POS tagging with the BIO scheme, which can be integrated with modern transformer models to address this challenge of identifying causality in a given text. Our best methodology achieves an F1-Score of 0.9551, and an Exact Match Score of 0.8777 on the blind test in the FinCausal-2021 Shared Task at the FinCausal 2021 Workshop.
Transformer Assisted Convolutional Network for Cell Instance Segmentation
Oct 05, 2021

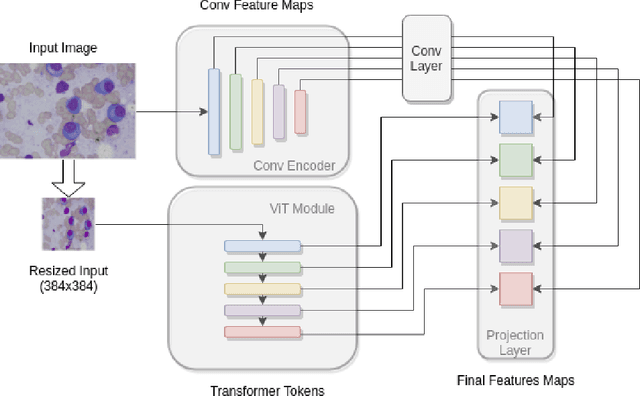
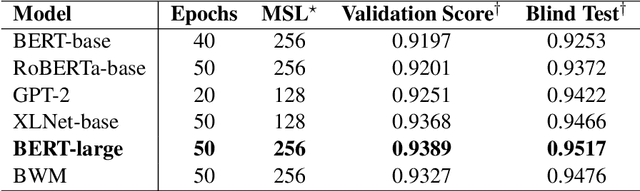
Region proposal based methods like R-CNN and Faster R-CNN models have proven to be extremely successful in object detection and segmentation tasks. Recently, Transformers have also gained popularity in the domain of Computer Vision, and are being utilised to improve the performance of conventional models. In this paper, we present a relatively new transformer based approach to enhance the performance of the conventional convolutional feature extractor in the existing region proposal based methods. Our approach merges the convolutional feature maps with transformer-based token embeddings by applying a projection operation similar to self-attention in transformers. The results of our experiments show that transformer assisted feature extractor achieves a significant improvement in mIoU (mean Intersection over Union) scores compared to vanilla convolutional backbone.
MIDAS at SemEval-2020 Task 10: Emphasis Selection using Label Distribution Learning and Contextual Embeddings
Sep 06, 2020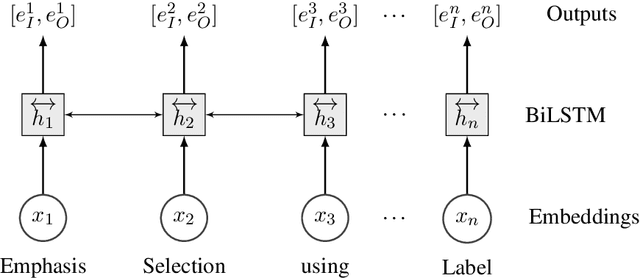
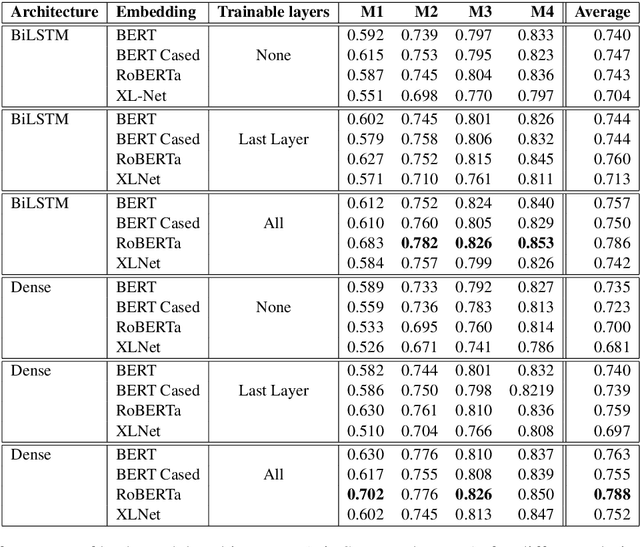


This paper presents our submission to the SemEval 2020 - Task 10 on emphasis selection in written text. We approach this emphasis selection problem as a sequence labeling task where we represent the underlying text with various contextual embedding models. We also employ label distribution learning to account for annotator disagreements. We experiment with the choice of model architectures, trainability of layers, and different contextual embeddings. Our best performing architecture is an ensemble of different models, which achieved an overall matching score of 0.783, placing us 15th out of 31 participating teams. Lastly, we analyze the results in terms of parts of speech tags, sentence lengths, and word ordering.
DSC IIT-ISM at SemEval-2020 Task 8: Bi-Fusion Techniques for Deep Meme Emotion Analysis
Jul 28, 2020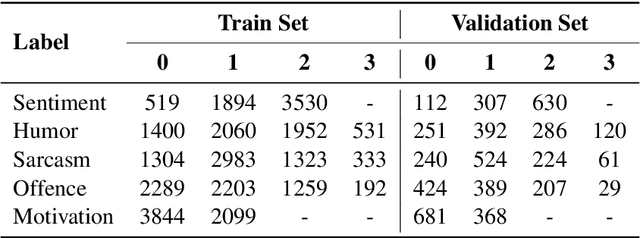
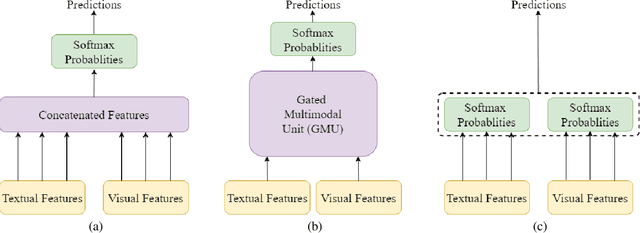
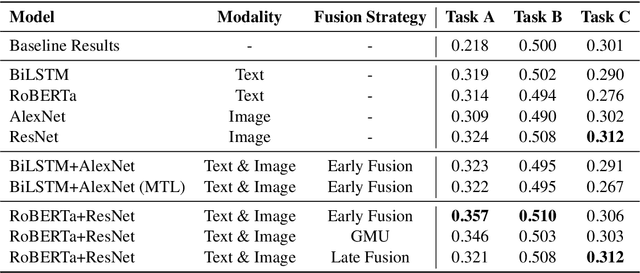

Memes have become an ubiquitous social media entity and the processing and analysis of suchmultimodal data is currently an active area of research. This paper presents our work on theMemotion Analysis shared task of SemEval 2020, which involves the sentiment and humoranalysis of memes. We propose a system which uses different bimodal fusion techniques toleverage the inter-modal dependency for sentiment and humor classification tasks. Out of all ourexperiments, the best system improved the baseline with macro F1 scores of 0.357 on SentimentClassification (Task A), 0.510 on Humor Classification (Task B) and 0.312 on Scales of SemanticClasses (Task C).