 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Accelerator for Rule Induction in Fuzzy Rough Theory
Jan 07, 2022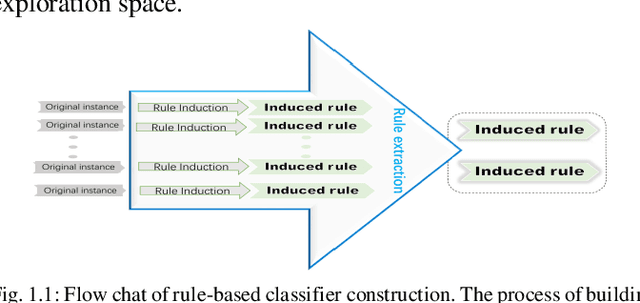
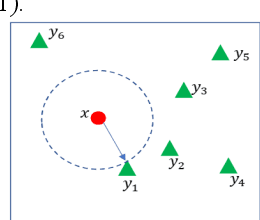
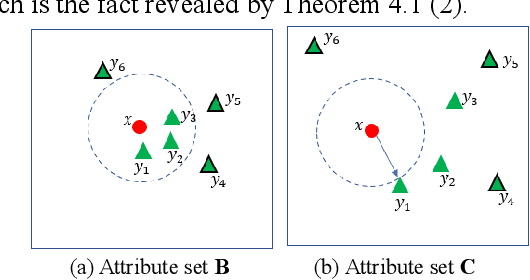
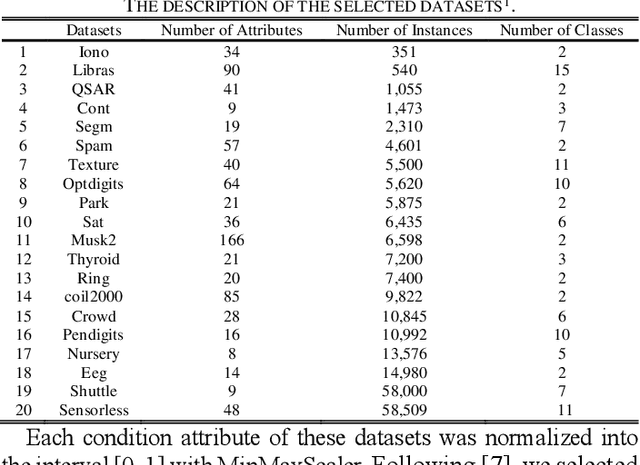
Rule-based classifier, that extract a subset of induced rules to efficiently learn/mine while preserving the discernibility information, plays a crucial role in human-explainable artificial intelligence. However, in this era of big data, rule induction on the whole datasets is computationally intensive. So far, to the best of our knowledge, no known method focusing on accelerating rule induction has been reported. This is first study to consider the acceleration technique to reduce the scale of computation in rule induction. We propose an accelerator for rule induction based on fuzzy rough theory; the accelerator can avoid redundant computation and accelerate the building of a rule classifier. First, a rule induction method based on consistence degree, called Consistence-based Value Reduction (CVR), is proposed and used as basis to accelerate. Second, we introduce a compacted search space termed Key Set, which only contains the key instances required to update the induced rule, to conduct value reduction. The monotonicity of Key Set ensures the feasibility of our accelerator. Third, a rule-induction accelerator is designed based on Key Set, and it is theoretically guaranteed to display the same results as the unaccelerated version. Specifically, the rank preservation property of Key Set ensures consistency between the rule induction achieved by the accelerator and the unaccelerated method. Finally, extensive experiments demonstrate that the proposed accelerator can perform remarkably faster than the unaccelerated rule-based classifier methods, especially on datasets with numerous instances.
UniMoCo: Unsupervised, Semi-Supervised and Full-Supervised Visual Representation Learning
Mar 19, 2021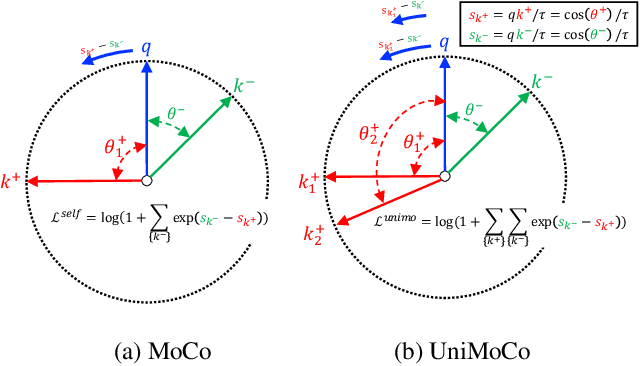
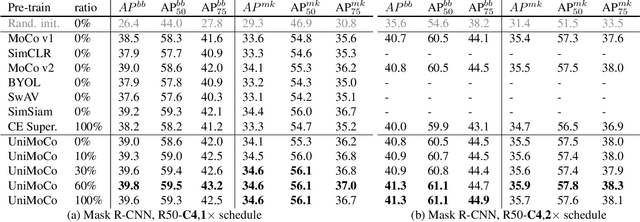
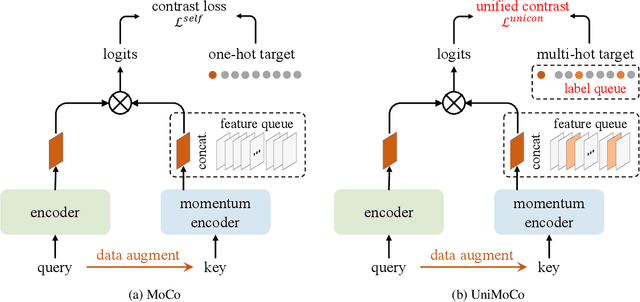
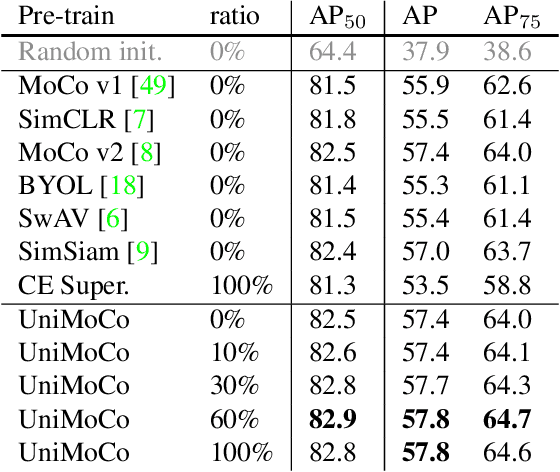
Momentum Contrast (MoCo) achieves great success for unsupervised visual representation. However, there are a lot of supervised and semi-supervised datasets, which are already labeled. To fully utilize the label annotations, we propose Unified Momentum Contrast (UniMoCo), which extends MoCo to support arbitrary ratios of labeled data and unlabeled data training. Compared with MoCo, UniMoCo has two modifications as follows: (1) Different from a single positive pair in MoCo, we maintain multiple positive pairs on-the-fly by comparing the query label to a label queue. (2) We propose a Unified Contrastive(UniCon) loss to support an arbitrary number of positives and negatives in a unified pair-wise optimization perspective. Our UniCon is more reasonable and powerful than the supervised contrastive loss in theory and practice. In our experiments, we pre-train multiple UniMoCo models with different ratios of ImageNet labels and evaluate the performance on various downstream tasks. Experiment results show that UniMoCo generalizes well for unsupervised, semi-supervised and supervised visual representation learning.
UP-DETR: Unsupervised Pre-training for Object Detection with Transformers
Nov 18, 2020
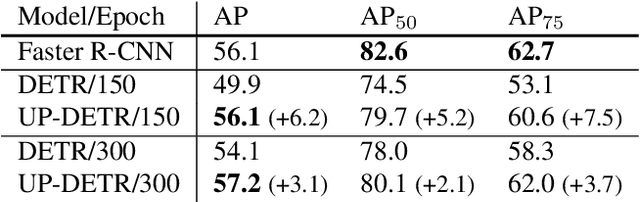
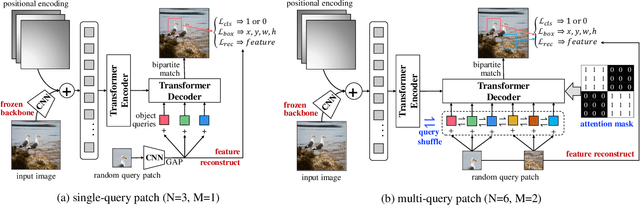
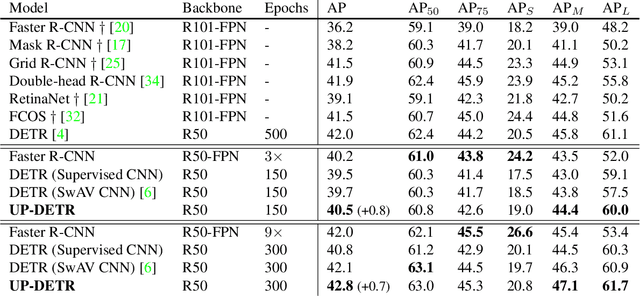
Object detection with transformers (DETR) reaches competitive performance with Faster R-CNN via a transformer encoder-decoder architecture. Inspired by the great success of pre-training transformers in natural language processing, we propose a pretext task named random query patch detection to unsupervisedly pre-train DETR (UP-DETR) for object detection. Specifically, we randomly crop patches from the given image and then feed them as queries to the decoder. The model is pre-trained to detect these query patches from the original image. During the pre-training, we address two critical issues: multi-task learning and multi-query localization. (1) To trade-off multi-task learning of classification and localization in the pretext task, we freeze the CNN backbone and propose a patch feature reconstruction branch which is jointly optimized with patch detection. (2) To perform multi-query localization, we introduce UP-DETR from single-query patch and extend it to multi-query patches with object query shuffle and attention mask. In our experiments, UP-DETR significantly boosts the performance of DETR with faster convergence and higher precision on PASCAL VOC and COCO datasets. The code will be available soon.
Local Contextual Attention with Hierarchical Structure for Dialogue Act Recognition
Mar 12, 2020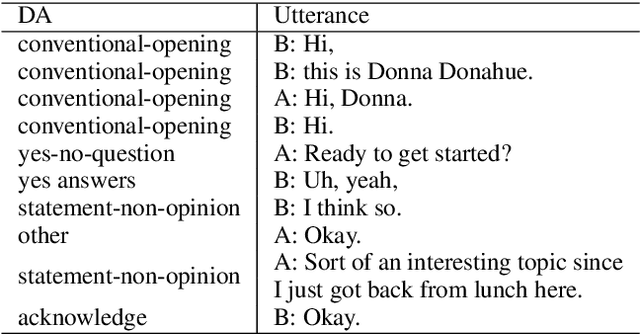
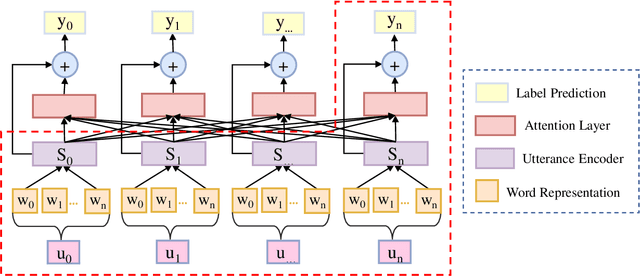
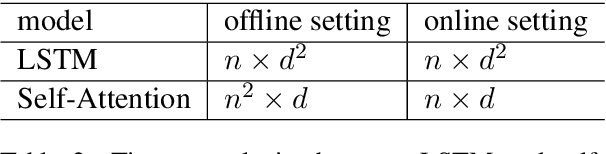
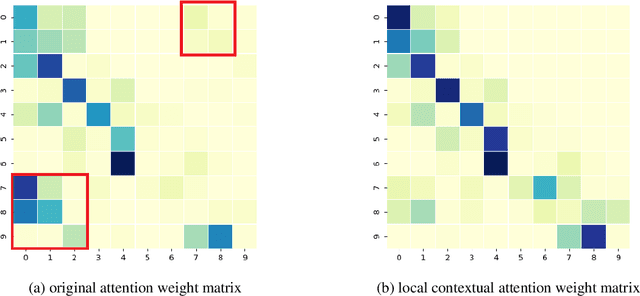
Dialogue act recognition is a fundamental task for an intelligent dialogue system. Previous work models the whole dialog to predict dialog acts, which may bring the noise from unrelated sentences. In this work, we design a hierarchical model based on self-attention to capture intra-sentence and inter-sentence information. We revise the attention distribution to focus on the local and contextual semantic information by incorporating the relative position information between utterances. Based on the found that the length of dialog affects the performance, we introduce a new dialog segmentation mechanism to analyze the effect of dialog length and context padding length under online and offline settings. The experiment shows that our method achieves promising performance on two datasets: Switchboard Dialogue Act and DailyDialog with the accuracy of 80.34\% and 85.81\% respectively. Visualization of the attention weights shows that our method can learn the context dependency between utterances explicitly.