 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsySQN: Faster Vertical Federated Learning Algorithms with Better Computation Resource Utilization
Sep 26, 2021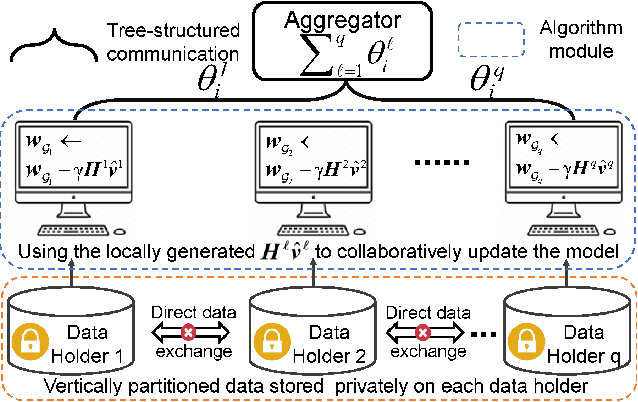


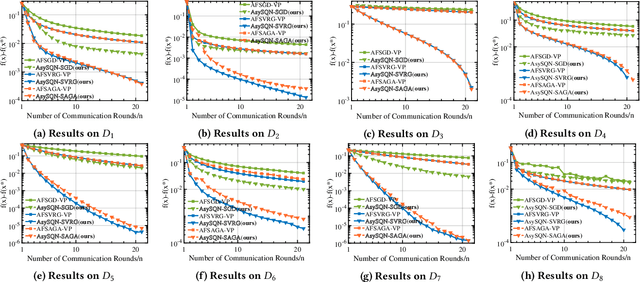
Vertical federated learning (VFL) is an effective paradigm of training the emerging cross-organizational (e.g., different corporations, companies and organizations) collaborative learning with privacy preserving. Stochastic gradient descent (SGD) methods are the popular choices for training VFL models because of the low per-iteration computation. However, existing SGD-based VFL algorithms are communication-expensive due to a large number of communication rounds. Meanwhile, most existing VFL algorithms use synchronous computation which seriously hamper the computation resource utilization in real-world applications. To address the challenges of communication and computation resource utilization, we propose an asynchronous stochastic quasi-Newton (AsySQN) framework for VFL, under which three algorithms, i.e. AsySQN-SGD, -SVRG and -SAGA, are proposed. The proposed AsySQN-type algorithms making descent steps scaled by approximate (without calculating the inverse Hessian matrix explicitly) Hessian information convergence much faster than SGD-based methods in practice and thus can dramatically reduce the number of communication rounds. Moreover, the adopted asynchronous computation can make better use of the computation resource. We theoretically prove the convergence rates of our proposed algorithms for strongly convex problems. Extensive numerical experiments on real-word datasets demonstrate the lower communication costs and better computation resource utilization of our algorithms compared with state-of-the-art VFL algorithms.
An Accelerated Variance-Reduced Conditional Gradient Sliding Algorithm for First-order and Zeroth-order Optimization
Sep 18, 2021

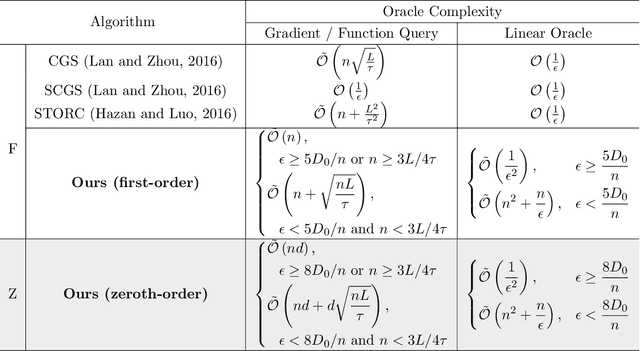
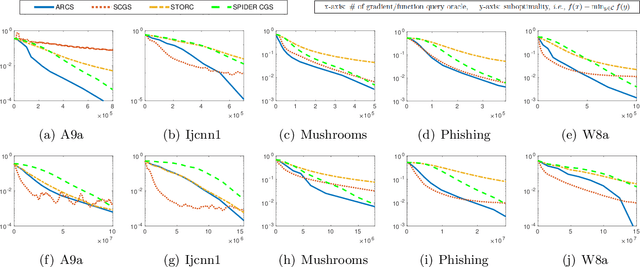
The conditional gradient algorithm (also known as the Frank-Wolfe algorithm) has recently regained popularity in the machine learning community due to its projection-free property to solve constrained problems. Although many variants of the conditional gradient algorithm have been proposed to improve performance, they depend on first-order information (gradient) to optimize. Naturally, these algorithms are unable to function properly in the field of increasingly popular zeroth-order optimization, where only zeroth-order information (function value) is available. To fill in this gap, we propose a novel Accelerated variance-Reduced Conditional gradient Sliding (ARCS) algorithm for finite-sum problems, which can use either first-order or zeroth-order information to optimize. To the best of our knowledge, ARCS is the first zeroth-order conditional gradient sliding type algorithms solving convex problems in zeroth-order optimization. In first-order optimization, the convergence results of ARCS substantially outperform previous algorithms in terms of the number of gradient query oracle. Finally we validated the superiority of ARCS by experiments on real-world datasets.
DSNet: A Dual-Stream Framework for Weakly-Supervised Gigapixel Pathology Image Analysis
Sep 13, 2021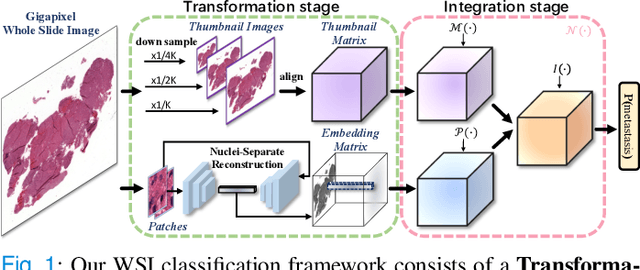
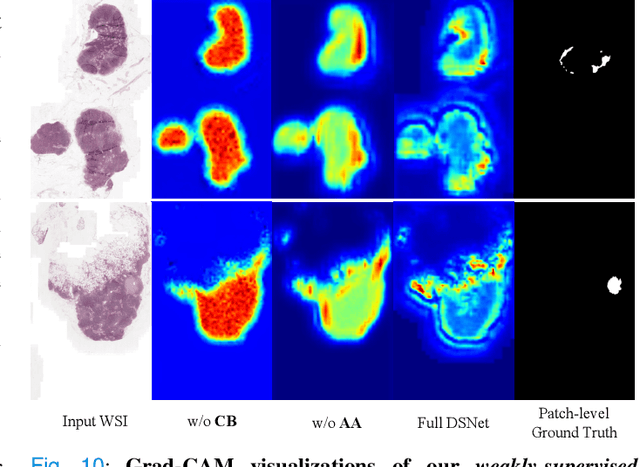
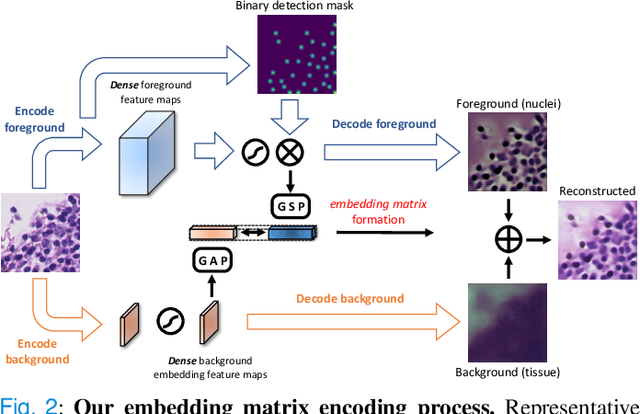
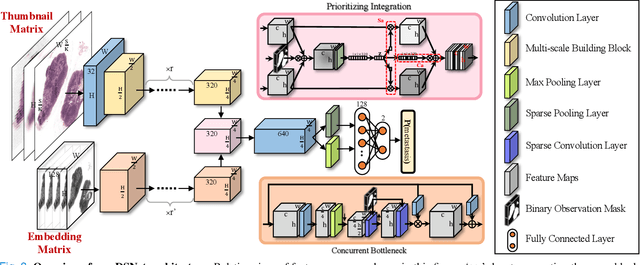
We present a novel weakly-supervised framework for classifying whole slide images (WSIs). WSIs, due to their gigapixel resolution, are commonly processed by patch-wise classification with patch-level labels. However, patch-level labels require precise annotations, which is expensive and usually unavailable on clinical data. With image-level labels only, patch-wise classification would be sub-optimal due to inconsistency between the patch appearance and image-level label. To address this issue, we posit that WSI analysis can be effectively conducted by integrating information at both high magnification (local) and low magnification (regional) levels. We auto-encode the visual signals in each patch into a latent embedding vector representing local information, and down-sample the raw WSI to hardware-acceptable thumbnails representing regional information. The WSI label is then predicted with a Dual-Stream Network (DSNet), which takes the transformed local patch embeddings and multi-scale thumbnail images as inputs and can be trained by the image-level label only. Experiments conducted on two large-scale public datasets demonstrate that our method outperforms all recent state-of-the-art weakly-supervised WSI classification methods.
PSGR: Pixel-wise Sparse Graph Reasoning for COVID-19 Pneumonia Segmentation in CT Images
Aug 09, 2021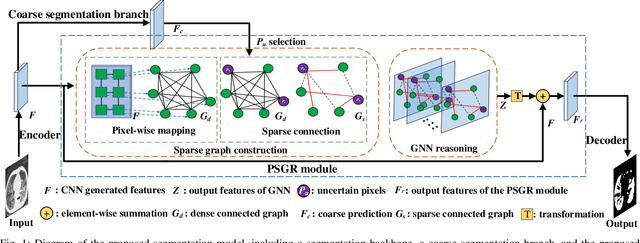
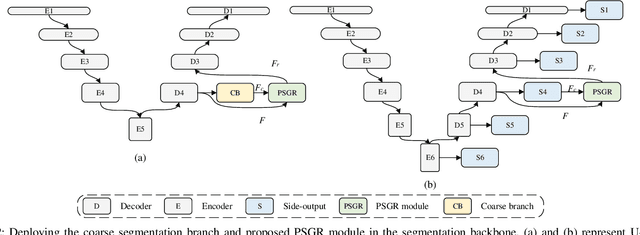

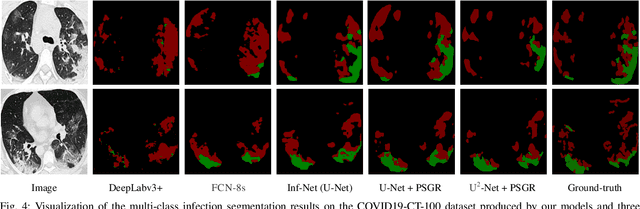
Automated and accurate segmentation of the infected regions in computed tomography (CT) images is critical for the prediction of the pathological stage and treatment response of COVID-19. Several deep convolutional neural networks (DCNNs) have been designed for this task, whose performance, however, tends to be suppressed by their limited local receptive fields and insufficient global reasoning ability. In this paper, we propose a pixel-wise sparse graph reasoning (PSGR) module and insert it into a segmentation network to enhance the modeling of long-range dependencies for COVID-19 infected region segmentation in CT images. In the PSGR module, a graph is first constructed by projecting each pixel on a node based on the features produced by the segmentation backbone, and then converted into a sparsely-connected graph by keeping only K strongest connections to each uncertain pixel. The long-range information reasoning is performed on the sparsely-connected graph to generate enhanced features. The advantages of this module are two-fold: (1) the pixel-wise mapping strategy not only avoids imprecise pixel-to-node projections but also preserves the inherent information of each pixel for global reasoning; and (2) the sparsely-connected graph construction results in effective information retrieval and reduction of the noise propagation. The proposed solution has been evaluated against four widely-used segmentation models on three public datasets. The results show that the segmentation model equipped with our PSGR module can effectively segment COVID-19 infected regions in CT images, outperforming all other competing models.
Boundary-aware Graph Reasoning for Semantic Segmentation
Aug 09, 2021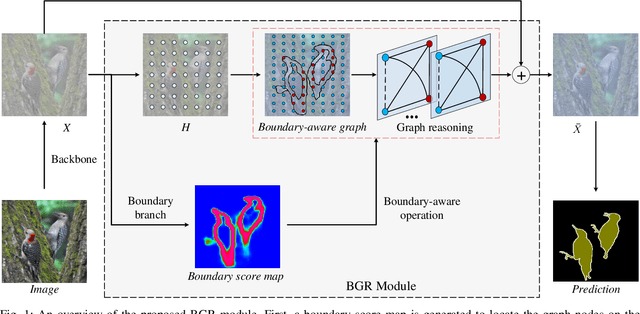
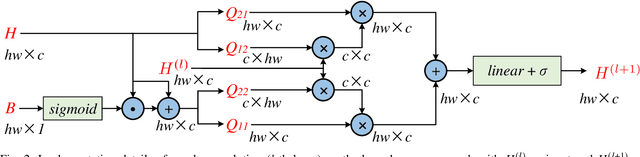
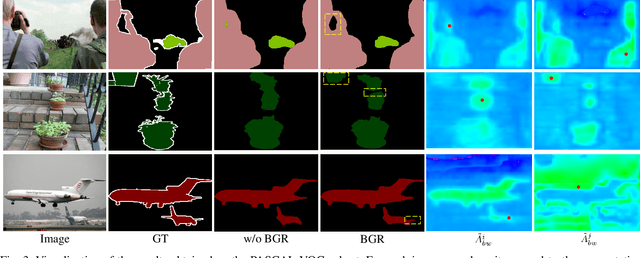

In this paper, we propose a Boundary-aware Graph Reasoning (BGR) module to learn long-range contextual features for semantic segmentation. Rather than directly construct the graph based on the backbone features, our BGR module explores a reasonable way to combine segmentation erroneous regions with the graph construction scenario. Motivated by the fact that most hard-to-segment pixels broadly distribute on boundary regions, our BGR module uses the boundary score map as prior knowledge to intensify the graph node connections and thereby guide the graph reasoning focus on boundary regions. In addition, we employ an efficient graph convolution implementation to reduce the computational cost, which benefits the integration of our BGR module into current segmentation backbones. Extensive experiments on three challenging segmentation benchmarks demonstrate the effectiveness of our proposed BGR module for semantic segmentation.
Fedlearn-Algo: A flexible open-source privacy-preserving machine learning platform
Jul 30, 2021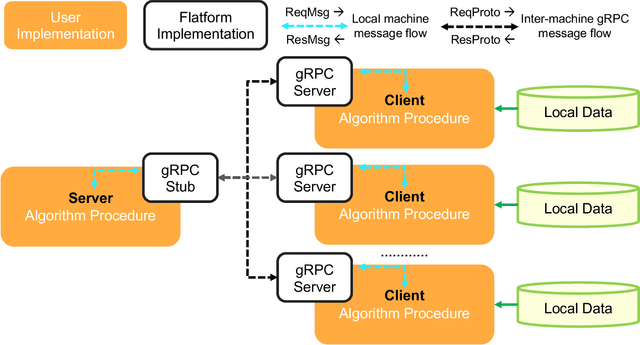
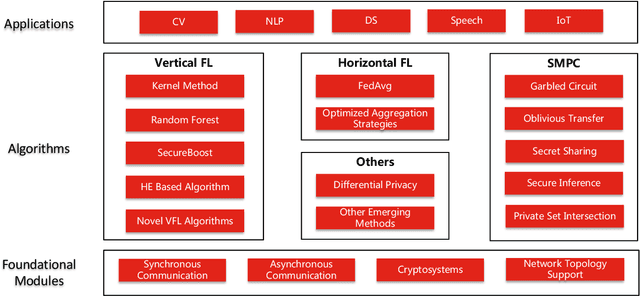
In this paper, we present Fedlearn-Algo, an open-source privacy preserving machine learning platform. We use this platform to demonstrate our research and development results on privacy preserving machine learning algorithms. As the first batch of novel FL algorithm examples, we release vertical federated kernel binary classification model and vertical federated random forest model. They have been tested to be more efficient than existing vertical federated learning models in our practice. Besides the novel FL algorithm examples, we also release a machine communication module. The uniform data transfer interface supports transferring widely used data formats between machines. We will maintain this platform by adding more functional modules and algorithm examples. The code is available at https://github.com/fedlearnAI/fedlearn-algo.
Enhanced Bilevel Optimization via Bregman Distance
Jul 26, 2021
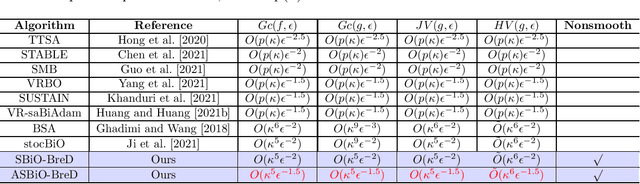
Bilevel optimization has been widely applied many machine learning problems such as hyperparameter optimization, policy optimization and meta learning. Although many bilevel optimization methods more recently have been proposed to solve the bilevel optimization problems, they still suffer from high computational complexities and do not consider the more general bilevel problems with nonsmooth regularization. In the paper, thus, we propose a class of efficient bilevel optimization methods based on Bregman distance. In our methods, we use the mirror decent iteration to solve the outer subproblem of the bilevel problem by using strongly-convex Bregman functions. Specifically, we propose a bilevel optimization method based on Bregman distance (BiO-BreD) for solving deterministic bilevel problems, which reaches the lower computational complexities than the best known results. We also propose a stochastic bilevel optimization method (SBiO-BreD) for solving stochastic bilevel problems based on the stochastic approximated gradients and Bregman distance. Further, we propose an accelerated version of SBiO-BreD method (ASBiO-BreD) by using the variance-reduced technique. Moreover, we prove that the ASBiO-BreD outperforms the best known computational complexities with respect to the condition number $\kappa$ and the target accuracy $\epsilon$ for finding an $\epsilon$-stationary point of nonconvex-strongly-convex bilevel problems. In particular, our methods can solve the bilevel optimization problems with nonsmooth regularization with a lower computational complexity.
AdaGDA: Faster Adaptive Gradient Descent Ascent Methods for Minimax Optimization
Jul 01, 2021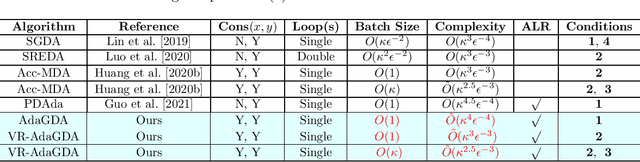
In the paper, we propose a class of faster adaptive gradient descent ascent methods for solving the nonconvex-strongly-concave minimax problems by using unified adaptive matrices used in the SUPER-ADAM \citep{huang2021super}. Specifically, we propose a fast adaptive gradient decent ascent (AdaGDA) method based on the basic momentum technique, which reaches a low sample complexity of $O(\kappa^4\epsilon^{-4})$ for finding an $\epsilon$-stationary point without large batches, which improves the existing result of adaptive minimax optimization method by a factor of $O(\sqrt{\kappa})$. Moreover, we present an accelerated version of AdaGDA (VR-AdaGDA) method based on the momentum-based variance reduced technique, which achieves the best known sample complexity of $O(\kappa^3\epsilon^{-3})$ for finding an $\epsilon$-stationary point without large batches. Further assume the bounded Lipschitz parameter of objective function, we prove that our VR-AdaGDA method reaches a lower sample complexity of $O(\kappa^{2.5}\epsilon^{-3})$ with the mini-batch size $O(\kappa)$. In particular, we provide an effective convergence analysis framework for our adaptive methods based on unified adaptive matrices, which include almost existing adaptive learning rates.
BiX-NAS: Searching Efficient Bi-directional Architecture for Medical Image Segmentation
Jul 01, 2021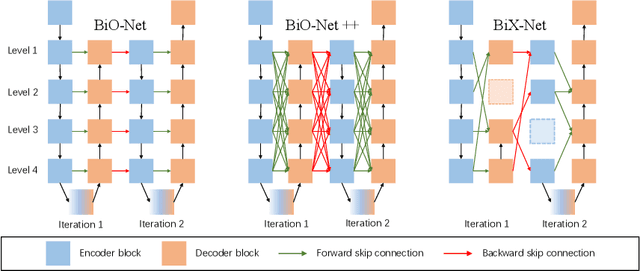
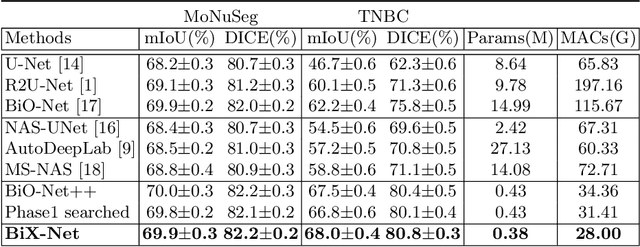
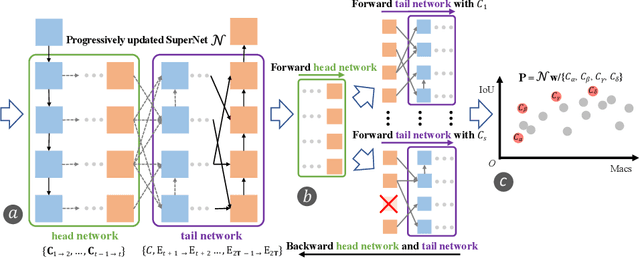
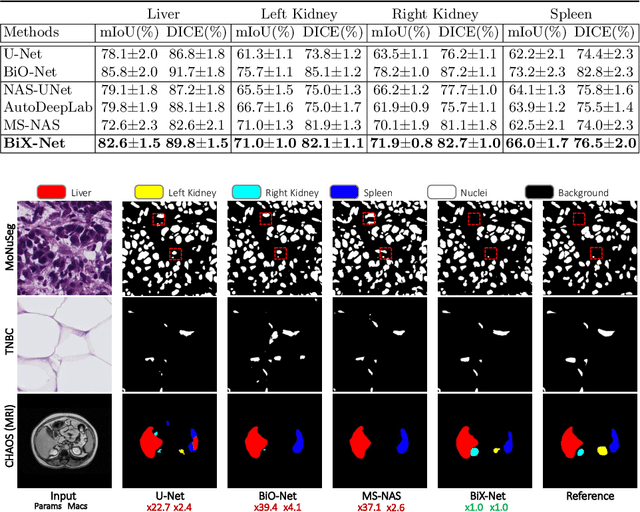
The recurrent mechanism has recently been introduced into U-Net in various medical image segmentation tasks. Existing studies have focused on promoting network recursion via reusing building blocks. Although network parameters could be greatly saved, computational costs still increase inevitably in accordance with the pre-set iteration time. In this work, we study a multi-scale upgrade of a bi-directional skip connected network and then automatically discover an efficient architecture by a novel two-phase Neural Architecture Search (NAS) algorithm, namely BiX-NAS. Our proposed method reduces the network computational cost by sifting out ineffective multi-scale features at different levels and iterations. We evaluate BiX-NAS on two segmentation tasks using three different medical image datasets, and the experimental results show that our BiX-NAS searched architecture achieves the state-of-the-art performance with significantly lower computational cost.
BiAdam: Fast Adaptive Bilevel Optimization Methods
Jun 30, 2021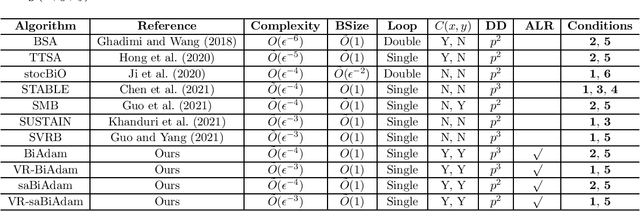
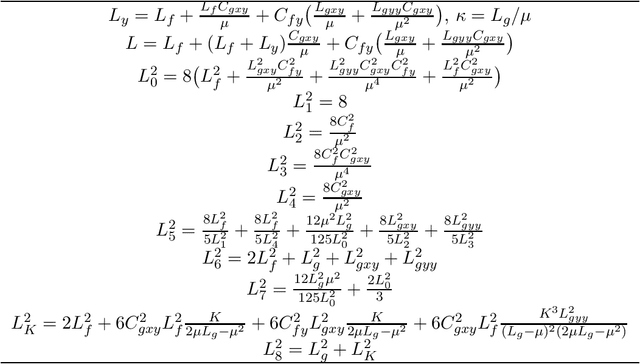
Bilevel optimization recently has attracted increased interest in machine learning due to its many applications such as hyper-parameter optimization and policy optimization. Although some methods recently have been proposed to solve the bilevel problems, these methods do not consider using adaptive learning rates. To fill this gap, in the paper, we propose a class of fast and effective adaptive methods for solving bilevel optimization problems that the outer problem is possibly nonconvex and the inner problem is strongly-convex. Specifically, we propose a fast single-loop BiAdam algorithm based on the basic momentum technique, which achieves a sample complexity of $\tilde{O}(\epsilon^{-4})$ for finding an $\epsilon$-stationary point. At the same time, we propose an accelerated version of BiAdam algorithm (VR-BiAdam) by using variance reduced technique, which reaches the best known sample complexity of $\tilde{O}(\epsilon^{-3})$. To further reduce computation in estimating derivatives, we propose a fast single-loop stochastic approximated BiAdam algorithm (saBiAdam) by avoiding the Hessian inverse, which still achieves a sample complexity of $\tilde{O}(\epsilon^{-4})$ without large batches. We further present an accelerated version of saBiAdam algorithm (VR-saBiAdam), which also reaches the best known sample complexity of $\tilde{O}(\epsilon^{-3})$. We apply the unified adaptive matrices to our methods as the SUPER-ADAM \citep{huang2021super}, which including many types of adaptive learning rates. Moreover, our framework can flexibly use the momentum and variance reduced techniques. In particular, we provide a useful convergence analysis framework for both the constrained and unconstrained bilevel optimization. To the best of our knowledge, we first study the adaptive bilevel optimization methods with adaptive learning rates.