 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJEDI: Joint Embedding Diffusion World Model for Online Model-Based Reinforcement Learning
May 13, 2026Diffusion world models have recently become competitive for online model-based reinforcement learning, but current approaches expose a tension: pixel diffusion is effective but computationally expensive while the latest latent diffusion approach improves efficiency yet performs subpar. The latter also relies on separately trained latents rather than the end-to-end world-model objectives that have driven much of modern MBRL progress. In particular, JEPA-style predictive representation learning has emerged as an especially promising direction for world modeling and MBRL. Concurrently, diffusion-style objectives have gained traction across multiple domains, with iterative refinement as a promising approach for multimodal and stochastic targets. Taken together, these trends motivate Joint Embedding DIffusion (JEDI), the first online end-to-end latent diffusion world model. JEDI learns its latent space directly from the diffusion denoising loss with a JEPA framework, using denoising to learn and predict future latents rather than relying on reconstruction and pretrained models. We provide a theoretical motivation showing that conventional JEPA objectives induce a predictive information bottleneck, and that conditional diffusion denoising admits a closely related predictive-compression decomposition. Empirically, JEDI is competitive on Atari100k and outperforms the baseline with seperately trained latents where directly comparable. Relative to the pixel diffusion baseline, JEDI uses 43% less VRAM, over 3$\times$ faster world-model sampling, and 2.5$\times$ faster training. JEDI also exhibits a markedly different task-level performance profile from the pixel baseline, suggesting that end-to-end predictive latents change more than compute alone.
Hierarchical Molecular Representation Learning via Fragment-Based Self-Supervised Embedding Prediction
Feb 23, 2026Graph self-supervised learning (GSSL) has demonstrated strong potential for generating expressive graph embeddings without the need for human annotations, making it particularly valuable in domains with high labeling costs such as molecular graph analysis. However, existing GSSL methods mostly focus on node- or edge-level information, often ignoring chemically relevant substructures which strongly influence molecular properties. In this work, we propose Graph Semantic Predictive Network (GraSPNet), a hierarchical self-supervised framework that explicitly models both atomic-level and fragment-level semantics. GraSPNet decomposes molecular graphs into chemically meaningful fragments without predefined vocabularies and learns node- and fragment-level representations through multi-level message passing with masked semantic prediction at both levels. This hierarchical semantic supervision enables GraSPNet to learn multi-resolution structural information that is both expressive and transferable. Extensive experiments on multiple molecular property prediction benchmarks demonstrate that GraSPNet learns chemically meaningful representations and consistently outperforms state-of-the-art GSSL methods in transfer learning settings.
A Stabilized Hybrid Active Noise Control Algorithm of GFANC and FxNLMS with Online Clustering
Jan 22, 2026The Filtered-x Normalized Least Mean Square (FxNLMS) algorithm suffers from slow convergence and a risk of divergence, although it can achieve low steady-state errors after sufficient adaptation. In contrast, the Generative Fixed-Filter Active Noise Control (GFANC) method offers fast response speed, but its lack of adaptability may lead to large steady-state errors. This paper proposes a hybrid GFANC-FxNLMS algorithm to leverage the complementary advantages of both approaches. In the hybrid GFANC-FxNLMS algorithm, GFANC provides a frame-level control filter as an initialization for FxNLMS, while FxNLMS performs continuous adaptation at the sampling rate. Small variations in the GFANC-generated filter may repeatedly reinitialize FxNLMS, interrupting its adaptation process and destabilizing the system. An online clustering module is introduced to avoid unnecessary re-initializations and improve system stability. Simulation results show that the proposed algorithm achieves fast response, very low steady-state error, and high stability, requiring only one pre-trained broadband filter.
Human Motion Estimation with Everyday Wearables
Dec 24, 2025While on-body device-based human motion estimation is crucial for applications such as XR interaction, existing methods often suffer from poor wearability, expensive hardware, and cumbersome calibration, which hinder their adoption in daily life. To address these challenges, we present EveryWear, a lightweight and practical human motion capture approach based entirely on everyday wearables: a smartphone, smartwatch, earbuds, and smart glasses equipped with one forward-facing and two downward-facing cameras, requiring no explicit calibration before use. We introduce Ego-Elec, a 9-hour real-world dataset covering 56 daily activities across 17 diverse indoor and outdoor environments, with ground-truth 3D annotations provided by the motion capture (MoCap), to facilitate robust research and benchmarking in this direction. Our approach employs a multimodal teacher-student framework that integrates visual cues from egocentric cameras with inertial signals from consumer devices. By training directly on real-world data rather than synthetic data, our model effectively eliminates the sim-to-real gap that constrains prior work. Experiments demonstrate that our method outperforms baseline models, validating its effectiveness for practical full-body motion estimation.
MacroNav: Multi-Task Context Representation Learning Enables Efficient Navigation in Unknown Environments
Nov 06, 2025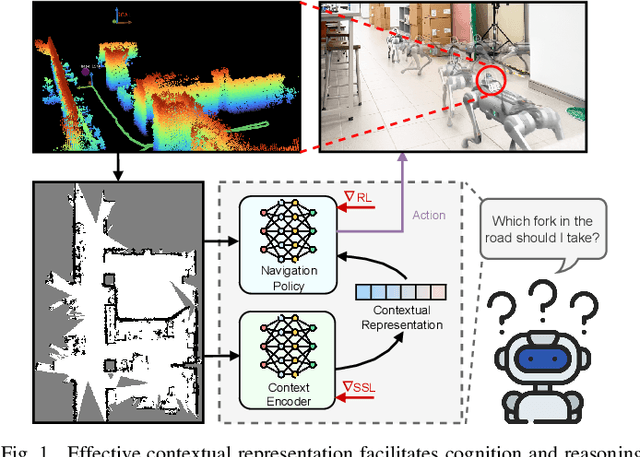
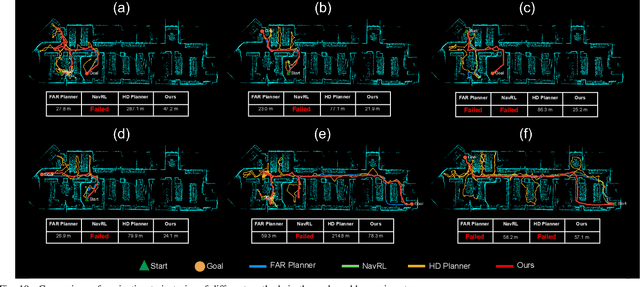
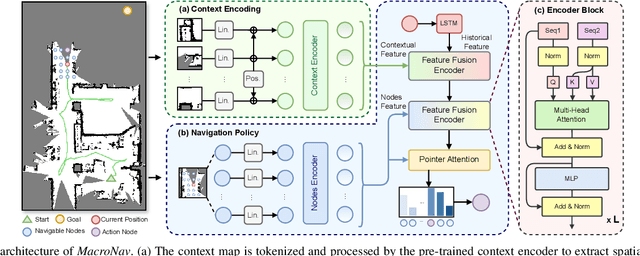
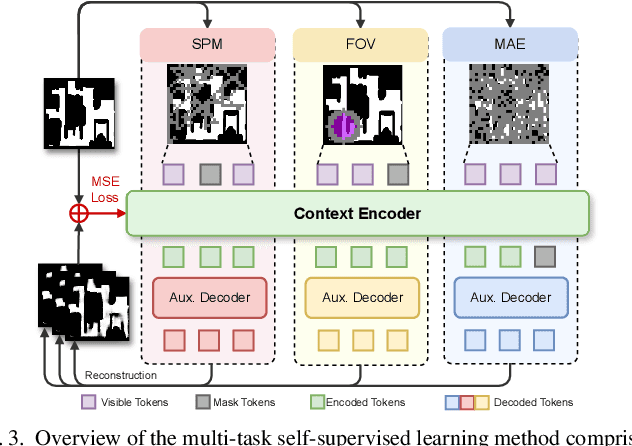
Autonomous navigation in unknown environments requires compact yet expressive spatial understanding under partial observability to support high-level decision making. Existing approaches struggle to balance rich contextual representation with navigation efficiency. We present MacroNav, a learning-based navigation framework featuring two key components: (1) a lightweight context encoder trained via multi-task self-supervised learning to capture multi-scale, navigation-centric spatial representations; and (2) a reinforcement learning policy that seamlessly integrates these representations with graph-based reasoning for efficient action selection. Extensive experiments demonstrate the context encoder's efficient and robust environmental understanding. Real-world deployments further validate MacroNav's effectiveness, yielding significant gains over state-of-the-art navigation methods in both Success Rate (SR) and Success weighted by Path Length (SPL), while maintaining low computational cost. Code will be released upon acceptance.
Exploration by Random Reward Perturbation
Jun 10, 2025We introduce Random Reward Perturbation (RRP), a novel exploration strategy for reinforcement learning (RL). Our theoretical analyses demonstrate that adding zero-mean noise to environmental rewards effectively enhances policy diversity during training, thereby expanding the range of exploration. RRP is fully compatible with the action-perturbation-based exploration strategies, such as $\epsilon$-greedy, stochastic policies, and entropy regularization, providing additive improvements to exploration effects. It is general, lightweight, and can be integrated into existing RL algorithms with minimal implementation effort and negligible computational overhead. RRP establishes a theoretical connection between reward shaping and noise-driven exploration, highlighting their complementary potential. Experiments show that RRP significantly boosts the performance of Proximal Policy Optimization and Soft Actor-Critic, achieving higher sample efficiency and escaping local optima across various tasks, under both sparse and dense reward scenarios.
Causal Policy Learning in Reinforcement Learning: Backdoor-Adjusted Soft Actor-Critic
Jun 05, 2025



Hidden confounders that influence both states and actions can bias policy learning in reinforcement learning (RL), leading to suboptimal or non-generalizable behavior. Most RL algorithms ignore this issue, learning policies from observational trajectories based solely on statistical associations rather than causal effects. We propose DoSAC (Do-Calculus Soft Actor-Critic with Backdoor Adjustment), a principled extension of the SAC algorithm that corrects for hidden confounding via causal intervention estimation. DoSAC estimates the interventional policy $\pi(a | \mathrm{do}(s))$ using the backdoor criterion, without requiring access to true confounders or causal labels. To achieve this, we introduce a learnable Backdoor Reconstructor that infers pseudo-past variables (previous state and action) from the current state to enable backdoor adjustment from observational data. This module is integrated into a soft actor-critic framework to compute both the interventional policy and its entropy. Empirical results on continuous control benchmarks show that DoSAC outperforms baselines under confounded settings, with improved robustness, generalization, and policy reliability.
JEDI: Latent End-to-end Diffusion Mitigates Agent-Human Performance Asymmetry in Model-Based Reinforcement Learning
May 26, 2025Recent advances in model-based reinforcement learning (MBRL) have achieved super-human level performance on the Atari100k benchmark, driven by reinforcement learning agents trained on powerful diffusion world models. However, we identify that the current aggregates mask a major performance asymmetry: MBRL agents dramatically outperform humans in some tasks despite drastically underperforming in others, with the former inflating the aggregate metrics. This is especially pronounced in pixel-based agents trained with diffusion world models. In this work, we address the pronounced asymmetry observed in pixel-based agents as an initial attempt to reverse the worrying upward trend observed in them. We address the problematic aggregates by delineating all tasks as Agent-Optimal or Human-Optimal and advocate for equal importance on metrics from both sets. Next, we hypothesize this pronounced asymmetry is due to the lack of temporally-structured latent space trained with the World Model objective in pixel-based methods. Lastly, to address this issue, we propose Joint Embedding DIffusion (JEDI), a novel latent diffusion world model trained end-to-end with the self-consistency objective. JEDI outperforms SOTA models in human-optimal tasks while staying competitive across the Atari100k benchmark, and runs 3 times faster with 43% lower memory than the latest pixel-based diffusion baseline. Overall, our work rethinks what it truly means to cross human-level performance in Atari100k.
Knowledge Sharing and Transfer via Centralized Reward Agent for Multi-Task Reinforcement Learning
Aug 20, 2024Reward shaping is effective in addressing the sparse-reward challenge in reinforcement learning by providing immediate feedback through auxiliary informative rewards. Based on the reward shaping strategy, we propose a novel multi-task reinforcement learning framework, that integrates a centralized reward agent (CRA) and multiple distributed policy agents. The CRA functions as a knowledge pool, which aims to distill knowledge from various tasks and distribute it to individual policy agents to improve learning efficiency. Specifically, the shaped rewards serve as a straightforward metric to encode knowledge. This framework not only enhances knowledge sharing across established tasks but also adapts to new tasks by transferring valuable reward signals. We validate the proposed method on both discrete and continuous domains, demonstrating its robustness in multi-task sparse-reward settings and its effective transferability to unseen tasks.
Highly Efficient Self-Adaptive Reward Shaping for Reinforcement Learning
Aug 07, 2024Reward shaping addresses the challenge of sparse rewards in reinforcement learning by constructing denser and more informative reward signals. To achieve self-adaptive and highly efficient reward shaping, we propose a novel method that incorporates success rates derived from historical experiences into shaped rewards. Our approach utilizes success rates sampled from Beta distributions, which dynamically evolve from uncertain to reliable values as more data is collected. Initially, the self-adaptive success rates exhibit more randomness to encourage exploration. Over time, they become more certain to enhance exploitation, thus achieving a better balance between exploration and exploitation. We employ Kernel Density Estimation (KDE) combined with Random Fourier Features (RFF) to derive the Beta distributions, resulting in a computationally efficient implementation in high-dimensional continuous state spaces. This method provides a non-parametric and learning-free approach. The proposed method is evaluated on a wide range of continuous control tasks with sparse and delayed rewards, demonstrating significant improvements in sample efficiency and convergence stability compared to relevant baselines.