 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Molecular Representation Learning via Fragment-Based Self-Supervised Embedding Prediction
Feb 23, 2026Graph self-supervised learning (GSSL) has demonstrated strong potential for generating expressive graph embeddings without the need for human annotations, making it particularly valuable in domains with high labeling costs such as molecular graph analysis. However, existing GSSL methods mostly focus on node- or edge-level information, often ignoring chemically relevant substructures which strongly influence molecular properties. In this work, we propose Graph Semantic Predictive Network (GraSPNet), a hierarchical self-supervised framework that explicitly models both atomic-level and fragment-level semantics. GraSPNet decomposes molecular graphs into chemically meaningful fragments without predefined vocabularies and learns node- and fragment-level representations through multi-level message passing with masked semantic prediction at both levels. This hierarchical semantic supervision enables GraSPNet to learn multi-resolution structural information that is both expressive and transferable. Extensive experiments on multiple molecular property prediction benchmarks demonstrate that GraSPNet learns chemically meaningful representations and consistently outperforms state-of-the-art GSSL methods in transfer learning settings.
Exploration by Random Reward Perturbation
Jun 10, 2025We introduce Random Reward Perturbation (RRP), a novel exploration strategy for reinforcement learning (RL). Our theoretical analyses demonstrate that adding zero-mean noise to environmental rewards effectively enhances policy diversity during training, thereby expanding the range of exploration. RRP is fully compatible with the action-perturbation-based exploration strategies, such as $\epsilon$-greedy, stochastic policies, and entropy regularization, providing additive improvements to exploration effects. It is general, lightweight, and can be integrated into existing RL algorithms with minimal implementation effort and negligible computational overhead. RRP establishes a theoretical connection between reward shaping and noise-driven exploration, highlighting their complementary potential. Experiments show that RRP significantly boosts the performance of Proximal Policy Optimization and Soft Actor-Critic, achieving higher sample efficiency and escaping local optima across various tasks, under both sparse and dense reward scenarios.
Learning Modality-Specific Representations with Self-Supervised Multi-Task Learning for Multimodal Sentiment Analysis
Feb 09, 2021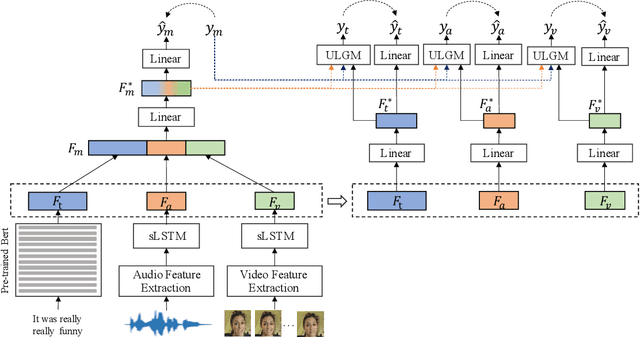
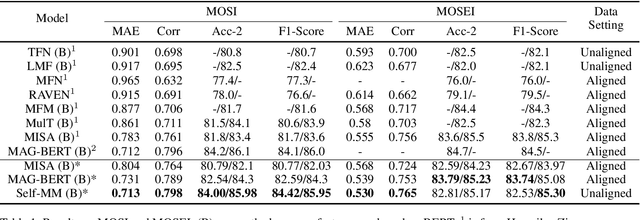
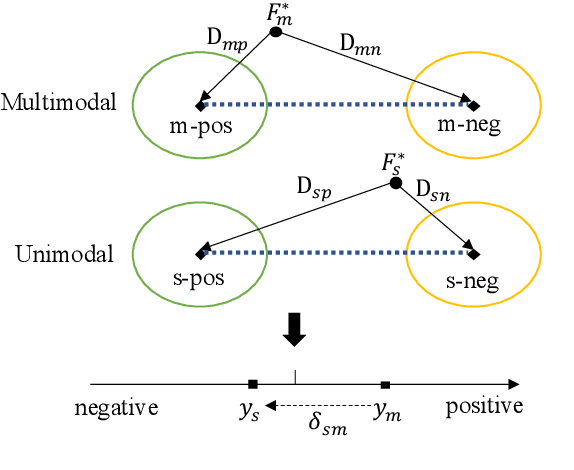
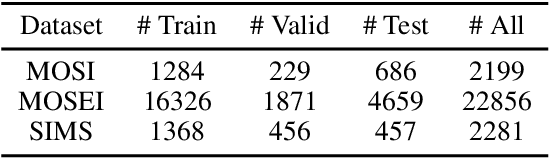
Representation Learning is a significant and challenging task in multimodal learning. Effective modality representations should contain two parts of characteristics: the consistency and the difference. Due to the unified multimodal annotation, existing methods are restricted in capturing differentiated information. However, additional uni-modal annotations are high time- and labor-cost. In this paper, we design a label generation module based on the self-supervised learning strategy to acquire independent unimodal supervisions. Then, joint training the multi-modal and uni-modal tasks to learn the consistency and difference, respectively. Moreover, during the training stage, we design a weight-adjustment strategy to balance the learning progress among different subtasks. That is to guide the subtasks to focus on samples with a larger difference between modality supervisions. Last, we conduct extensive experiments on three public multimodal baseline datasets. The experimental results validate the reliability and stability of auto-generated unimodal supervisions. On MOSI and MOSEI datasets, our method surpasses the current state-of-the-art methods. On the SIMS dataset, our method achieves comparable performance than human-annotated unimodal labels. The full codes are available at https://github.com/thuiar/Self-MM.
Toward Effective Automated Content Analysis via Crowdsourcing
Jan 12, 2021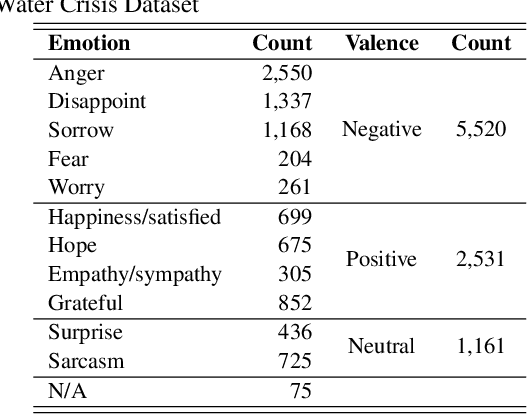
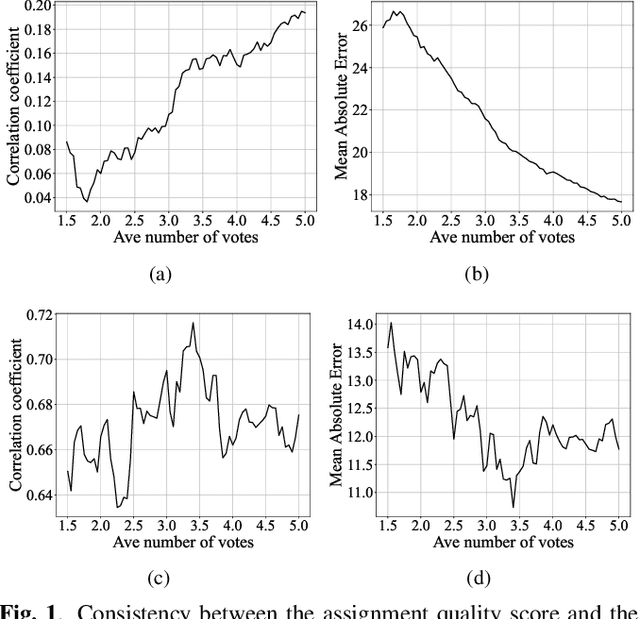
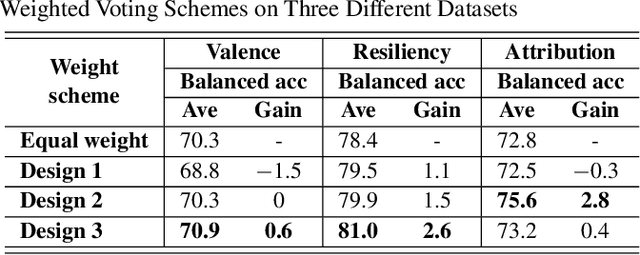
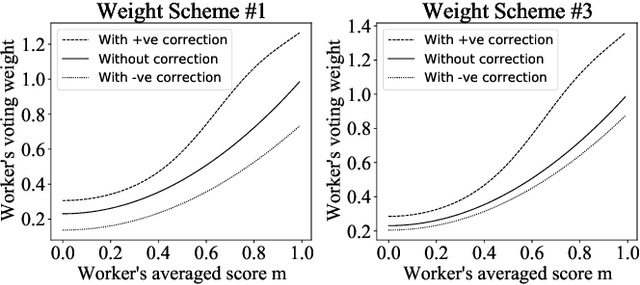
Many computer scientists use the aggregated answers of online workers to represent ground truth. Prior work has shown that aggregation methods such as majority voting are effective for measuring relatively objective features. For subjective features such as semantic connotation, online workers, known for optimizing their hourly earnings, tend to deteriorate in the quality of their responses as they work longer. In this paper, we aim to address this issue by proposing a quality-aware semantic data annotation system. We observe that with timely feedback on workers' performance quantified by quality scores, better informed online workers can maintain the quality of their labeling throughout an extended period of time. We validate the effectiveness of the proposed annotation system through i) evaluating performance based on an expert-labeled dataset, and ii) demonstrating machine learning tasks that can lead to consistent learning behavior with 70%-80% accuracy. Our results suggest that with our system, researchers can collect high-quality answers of subjective semantic features at a large scale.