 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMacroNav: Multi-Task Context Representation Learning Enables Efficient Navigation in Unknown Environments
Nov 06, 2025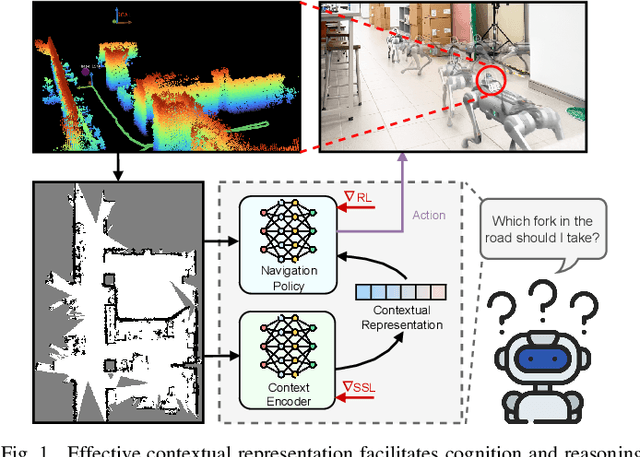
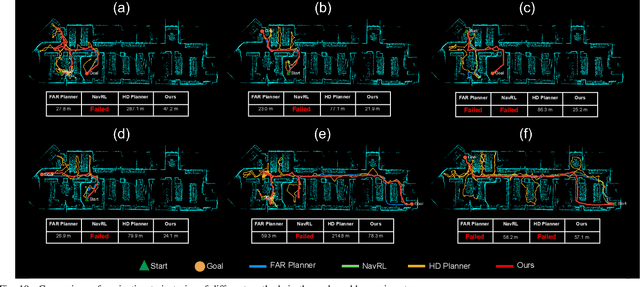
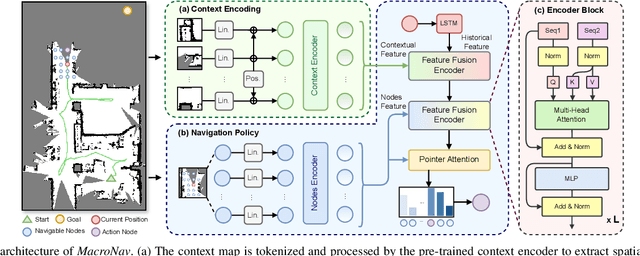
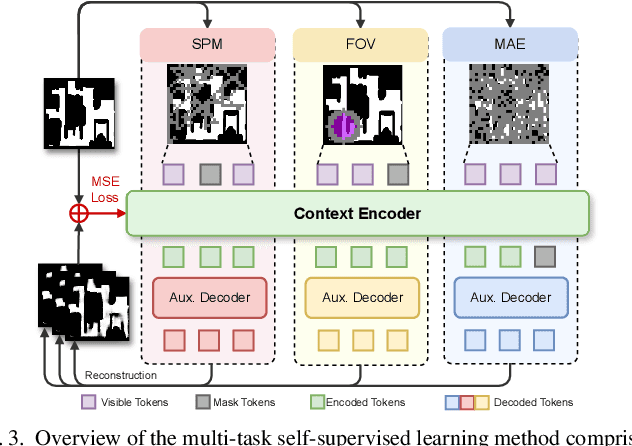
Autonomous navigation in unknown environments requires compact yet expressive spatial understanding under partial observability to support high-level decision making. Existing approaches struggle to balance rich contextual representation with navigation efficiency. We present MacroNav, a learning-based navigation framework featuring two key components: (1) a lightweight context encoder trained via multi-task self-supervised learning to capture multi-scale, navigation-centric spatial representations; and (2) a reinforcement learning policy that seamlessly integrates these representations with graph-based reasoning for efficient action selection. Extensive experiments demonstrate the context encoder's efficient and robust environmental understanding. Real-world deployments further validate MacroNav's effectiveness, yielding significant gains over state-of-the-art navigation methods in both Success Rate (SR) and Success weighted by Path Length (SPL), while maintaining low computational cost. Code will be released upon acceptance.
Learning Agile Gate Traversal via Analytical Optimal Policy Gradient
Aug 29, 2025Traversing narrow gates presents a significant challenge and has become a standard benchmark for evaluating agile and precise quadrotor flight. Traditional modularized autonomous flight stacks require extensive design and parameter tuning, while end-to-end reinforcement learning (RL) methods often suffer from low sample efficiency and limited interpretability. In this work, we present a novel hybrid framework that adaptively fine-tunes model predictive control (MPC) parameters online using outputs from a neural network (NN) trained offline. The NN jointly predicts a reference pose and cost-function weights, conditioned on the coordinates of the gate corners and the current drone state. To achieve efficient training, we derive analytical policy gradients not only for the MPC module but also for an optimization-based gate traversal detection module. Furthermore, we introduce a new formulation of the attitude tracking error that admits a simplified representation, facilitating effective learning with bounded gradients. Hardware experiments demonstrate that our method enables fast and accurate quadrotor traversal through narrow gates in confined environments. It achieves several orders of magnitude improvement in sample efficiency compared to naive end-to-end RL approaches.