 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Safe Skills Collide: Measuring Compositional Risk in Agent Skill Ecosystems
May 30, 2026LLM agents increasingly rely on community-contributed skills that expand an agent's operational capability set. We study a core safety problem in agentic AI systems: whether individually safe skills can compose into unsafe installed skill sets. We present SkillReact, a compositional security measurement framework with three components: a deterministic static-composition benchmark, a two-rater LLM-assisted human-adjudication pipeline, and an action-based exploitability harness. On 1,520 ClawHub skills, 651 pass individual inspection and form 211,575 pairs; the benchmark flags 22.25% of these as structural candidates. We treat this raw rate as a recall-oriented scanner ceiling and calibrate it against human judgment: in a pattern-stratified audit, roughly one in five flagged pair-pattern hits survives as a real compositional risk (population-weighted validity 18.2%, our headline result), implying about 14K genuine risk memberships in a single registry that per-skill scanning misses by construction, since every pair is individually safe. An action-based harness then probes when these candidates become model-issued tool calls, and finds realization gated by host-model disposition: on an anchor-conditioned dropper subset, Haiku-4-5 issues the dropper-stage tool call on all 39 direct-prompt trials (36 of them the full download-then-execute chain, 3 download-only), Opus-4-7 stops at the download, and Sonnet-4-6 refuses outright. A control that holds the request fixed and varies only the installed skills finds compliance highest with no skills installed: a composition fixes which capabilities are reachable, while the host model decides whether to use them. Together these motivate install-time compositional checks and capability isolation as complements to per-skill scanning.
ChainCaps: Composition-Safe Tool-Using Agents via Monotonic Capability Attenuation
May 26, 2026Tool-using agents increasingly operate in open-ended deployment environments, where they compose file systems, web APIs, code interpreters, and enterprise services at runtime. This creates a safety gap in tool composition: an agent can satisfy every per-tool permission check and still produce an unsafe end-to-end effect, such as reading a confidential document, summarizing it, and sending the summary to an external endpoint. We call this failure mode permission laundering. ChainCaps addresses it with a runtime rule: every value carries a sink-specific capability budget, and tool composition propagates budgets by intersection. A value can preserve or lose authority as it moves through a tool chain, but it cannot gain new authority through composition. We implement ChainCaps as a transparent MCP proxy that requires no changes to the agent or tool servers. On 82 tasks across five frontier models from three providers, ChainCaps reduces attack success rate from 25-68% to 0-4.8% while preserving 96-100% benign completion. In replay experiments, it also outperforms scalar-IFC and per-function-isolation baselines. Manifest quality is the dominant deployment bottleneck: expert manifests reach 100% attack blocking, while naive manifests fall to 27.3%. Our claims are limited to explicit-flow composition safety under trusted manifests and proxy-visible data movement, a practical gap in deployed tool-using agents today.
Enhancing Healthcare through Large Language Models: A Study on Medical Question Answering
Aug 08, 2024

In recent years, the application of Large Language Models (LLMs) in healthcare has shown significant promise in improving the accessibility and dissemination of medical knowledge. This paper presents a detailed study of various LLMs trained on the MedQuAD medical question-answering dataset, with a focus on identifying the most effective model for providing accurate medical information. Among the models tested, the Sentence-t5 combined with Mistral 7B demonstrated superior performance, achieving a precision score of 0.762. This model's enhanced capabilities are attributed to its advanced pretraining techniques, robust architecture, and effective prompt construction methodologies. By leveraging these strengths, the Sentence-t5 + Mistral 7B model excels in understanding and generating precise medical answers. Our findings highlight the potential of integrating sophisticated LLMs in medical contexts to facilitate efficient and accurate medical knowledge retrieval, thus significantly enhancing patient education and support.
Prompt-Guided Injection of Conformation to Pre-trained Protein Model
Feb 07, 2022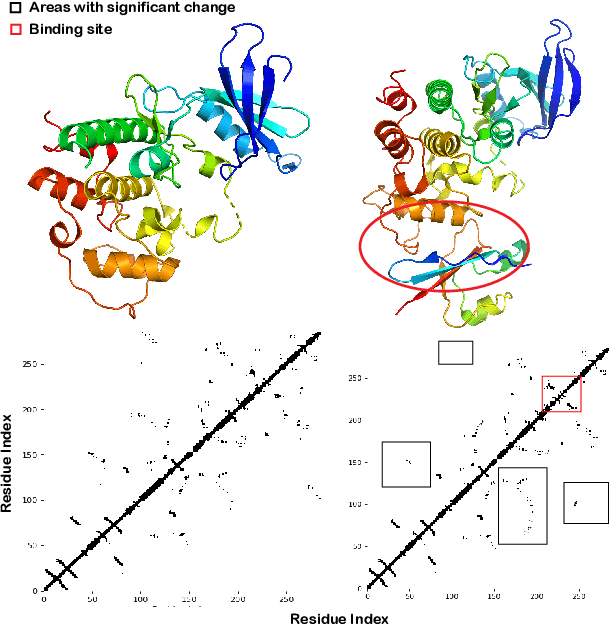
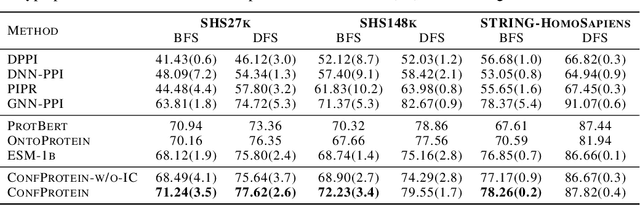
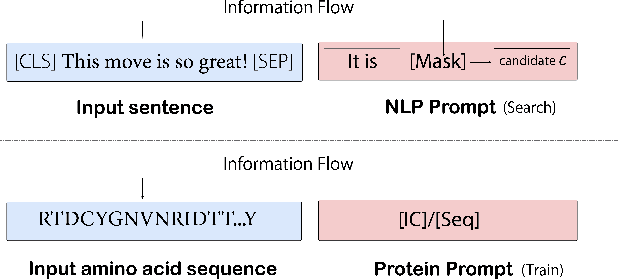

Pre-trained protein models (PTPMs) represent a protein with one fixed embedding and thus are not capable for diverse tasks. For example, protein structures can shift, namely protein folding, between several conformations in various biological processes. To enable PTPMs to produce task-aware representations, we propose to learn interpretable, pluggable and extensible protein prompts as a way of injecting task-related knowledge into PTPMs. In this regard, prior PTPM optimization with the masked language modeling task can be interpreted as learning a sequence prompt (Seq prompt) that enables PTPMs to capture the sequential dependency between amino acids. To incorporate conformational knowledge to PTPMs, we propose an interaction-conformation prompt (IC prompt) that is learned through back-propagation with the protein-protein interaction task. As an instantiation, we present a conformation-aware pre-trained protein model that learns both sequence and interaction-conformation prompts in a multi-task setting. We conduct comprehensive experiments on nine protein datasets. Results confirm our expectation that using the sequence prompt does not hurt PTPMs' performance on sequence-related tasks while incorporating the interaction-conformation prompt significantly improves PTPMs' performance on tasks where conformational knowledge counts. We also show the learned prompts can be combined and extended to deal with new complex tasks.