 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLAPSep: Leveraging Contrastive Pre-trained Models for Multi-Modal Query-Conditioned Target Sound Extraction
Feb 27, 2024



Universal sound separation (USS) aims to extract arbitrary types of sounds from real-world sound recordings. Language-queried target sound extraction (TSE) is an effective approach to achieving USS. Such systems consist of two components: a query network that converts user queries into conditional embeddings, and a separation network that extracts the target sound based on conditional embeddings. Existing methods mainly suffer from two issues: firstly, they require training a randomly initialized model from scratch, lacking the utilization of pre-trained models, and substantial data and computational resources are needed to ensure model convergence; secondly, existing methods need to jointly train a query network and a separation network, which tends to lead to overfitting. To address these issues, we build the CLAPSep model based on contrastive language-audio pre-trained model (CLAP). We achieve this by using a pre-trained text encoder of CLAP as the query network and introducing pre-trained audio encoder weights of CLAP into the separation network to fully utilize the prior knowledge embedded in the pre-trained model to assist in target sound extraction tasks. Extensive experimental results demonstrate that the proposed method saves training resources while ensuring the model's performance and generalizability. Additionally, we explore the model's ability to comprehensively utilize language/audio multi-modal and positive/negative multi-valent user queries, enhancing system performance while providing diversified application modes.
Poisoning Attacks against Recommender Systems: A Survey
Jan 14, 2024Modern recommender systems (RS) have seen substantial success, yet they remain vulnerable to malicious activities, notably poisoning attacks. These attacks involve injecting malicious data into the training datasets of RS, thereby compromising their integrity and manipulating recommendation outcomes for gaining illicit profits. This survey paper provides a systematic and up-to-date review of the research landscape on Poisoning Attacks against Recommendation (PAR). A novel and comprehensive taxonomy is proposed, categorizing existing PAR methodologies into three distinct categories: Component-Specific, Goal-Driven, and Capability Probing. For each category, we discuss its mechanism in detail, along with associated methods. Furthermore, this paper highlights potential future research avenues in this domain. Additionally, to facilitate and benchmark the empirical comparison of PAR, we introduce an open-source library, ARLib, which encompasses a comprehensive collection of PAR models and common datasets. The library is released at https://github.com/CoderWZW/ARLib.
Extending Whisper with prompt tuning to target-speaker ASR
Dec 13, 2023



Target-speaker automatic speech recognition (ASR) aims to transcribe the desired speech of a target speaker from multi-talker overlapped utterances. Most of the existing target-speaker ASR (TS-ASR) methods involve either training from scratch or fully fine-tuning a pre-trained model, leading to significant training costs and becoming inapplicable to large foundation models. This work leverages prompt tuning, a parameter-efficient fine-tuning approach, to extend Whisper, a large-scale single-talker ASR model, to TS-ASR. Experimental results show that prompt tuning can achieve performance comparable to state-of-the-art full fine-tuning approaches while only requiring about 1% of task-specific model parameters. Notably, the original Whisper's features, such as inverse text normalization and timestamp prediction, are retained in target-speaker ASR, keeping the generated transcriptions natural and informative.
Adversarial Driving Behavior Generation Incorporating Human Risk Cognition for Autonomous Vehicle Evaluation
Oct 14, 2023



Autonomous vehicle (AV) evaluation has been the subject of increased interest in recent years both in industry and in academia. This paper focuses on the development of a novel framework for generating adversarial driving behavior of background vehicle interfering against the AV to expose effective and rational risky events. Specifically, the adversarial behavior is learned by a reinforcement learning (RL) approach incorporated with the cumulative prospect theory (CPT) which allows representation of human risk cognition. Then, the extended version of deep deterministic policy gradient (DDPG) technique is proposed for training the adversarial policy while ensuring training stability as the CPT action-value function is leveraged. A comparative case study regarding the cut-in scenario is conducted on a high fidelity Hardware-in-the-Loop (HiL) platform and the results demonstrate the adversarial effectiveness to infer the weakness of the tested AV.
Effective Long-Context Scaling of Foundation Models
Sep 27, 2023



We present a series of long-context LLMs that support effective context windows of up to 32,768 tokens. Our model series are built through continual pretraining from Llama 2 with longer training sequences and on a dataset where long texts are upsampled. We perform extensive evaluation on language modeling, synthetic context probing tasks, and a wide range of research benchmarks. On research benchmarks, our models achieve consistent improvements on most regular tasks and significant improvements on long-context tasks over Llama 2. Notably, with a cost-effective instruction tuning procedure that does not require human-annotated long instruction data, the 70B variant can already surpass gpt-3.5-turbo-16k's overall performance on a suite of long-context tasks. Alongside these results, we provide an in-depth analysis on the individual components of our method. We delve into Llama's position encodings and discuss its limitation in modeling long dependencies. We also examine the impact of various design choices in the pretraining process, including the data mix and the training curriculum of sequence lengths -- our ablation experiments suggest that having abundant long texts in the pretrain dataset is not the key to achieving strong performance, and we empirically verify that long context continual pretraining is more efficient and similarly effective compared to pretraining from scratch with long sequences.
Data-Efficient Online Learning of Ball Placement in Robot Table Tennis
Aug 28, 2023



We present an implementation of an online optimization algorithm for hitting a predefined target when returning ping-pong balls with a table tennis robot. The online algorithm optimizes over so-called interception policies, which define the manner in which the robot arm intercepts the ball. In our case, these are composed of the state of the robot arm (position and velocity) at interception time. Gradient information is provided to the optimization algorithm via the mapping from the interception policy to the landing point of the ball on the table, which is approximated with a black-box and a grey-box approach. Our algorithm is applied to a robotic arm with four degrees of freedom that is driven by pneumatic artificial muscles. As a result, the robot arm is able to return the ball onto any predefined target on the table after about 2-5 iterations. We highlight the robustness of our approach by showing rapid convergence with both the black-box and the grey-box gradients. In addition, the small number of iterations required to reach close proximity to the target also underlines the sample efficiency. A demonstration video can be found here: https://youtu.be/VC3KJoCss0k.
A Robust Open-source Tendon-driven Robot Arm for Learning Control of Dynamic Motions
Jul 10, 2023



A long-lasting goal of robotics research is to operate robots safely, while achieving high performance which often involves fast motions. Traditional motor-driven systems frequently struggle to balance these competing demands. Addressing this trade-off is crucial for advancing fields such as manufacturing and healthcare, where seamless collaboration between robots and humans is essential. We introduce a four degree-of-freedom (DoF) tendon-driven robot arm, powered by pneumatic artificial muscles (PAMs), to tackle this challenge. Our new design features low friction, passive compliance, and inherent impact resilience, enabling rapid, precise, high-force, and safe interactions during dynamic tasks. In addition to fostering safer human-robot collaboration, the inherent safety properties are particularly beneficial for reinforcement learning, where the robot's ability to explore dynamic motions without causing self-damage is crucial. We validate our robotic arm through various experiments, including long-term dynamic motions, impact resilience tests, and assessments of its ease of control. On a challenging dynamic table tennis task, we further demonstrate our robot's capabilities in rapid and precise movements. By showcasing our new design's potential, we aim to inspire further research on robotic systems that balance high performance and safety in diverse tasks. Our open-source hardware design, software, and a large dataset of diverse robot motions can be found at https://webdav.tuebingen.mpg.de/pamy2/.
Black-Box vs. Gray-Box: A Case Study on Learning Table Tennis Ball Trajectory Prediction with Spin and Impacts
May 24, 2023In this paper, we present a method for table tennis ball trajectory filtering and prediction. Our gray-box approach builds on a physical model. At the same time, we use data to learn parameters of the dynamics model, of an extended Kalman filter, and of a neural model that infers the ball's initial condition. We demonstrate superior prediction performance of our approach over two black-box approaches, which are not supplied with physical prior knowledge. We demonstrate that initializing the spin from parameters of the ball launcher using a neural network drastically improves long-time prediction performance over estimating the spin purely from measured ball positions. An accurate prediction of the ball trajectory is crucial for successful returns. We therefore evaluate the return performance with a pneumatic artificial muscular robot and achieve a return rate of 29/30 (97.7%).
A Tightly Coupled LiDAR-IMU Odometry through Iterated Point-Level Undistortion
Sep 28, 2022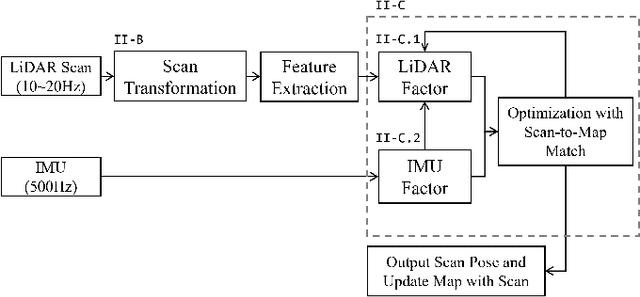

Scan undistortion is a key module for LiDAR odometry in high dynamic environment with high rotation and translation speed. The existing line of studies mostly focuses on one pass undistortion, which means undistortion for each point is conducted only once in the whole LiDAR-IMU odometry pipeline. In this paper, we propose an optimization based tightly coupled LiDAR-IMU odometry addressing iterated point-level undistortion. By jointly minimizing the cost derived from LiDAR and IMU measurements, our LiDAR-IMU odometry method performs more accurate and robust in high dynamic environment. Besides, the method characters good computation efficiency by limiting the quantity of parameters.
IDPG: An Instance-Dependent Prompt Generation Method
Apr 09, 2022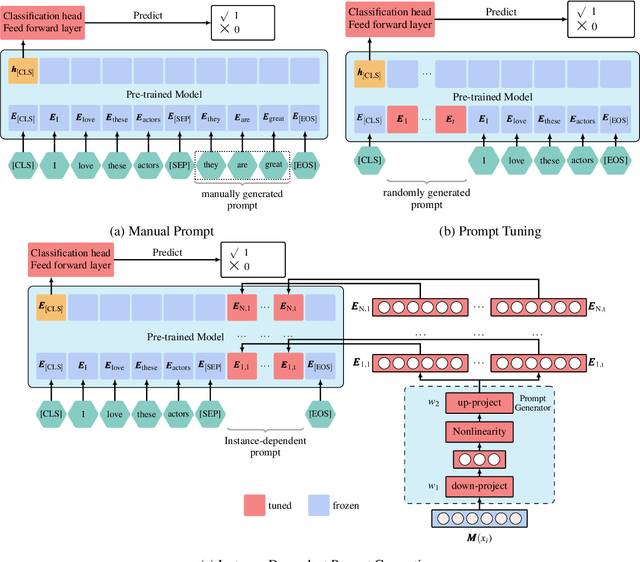
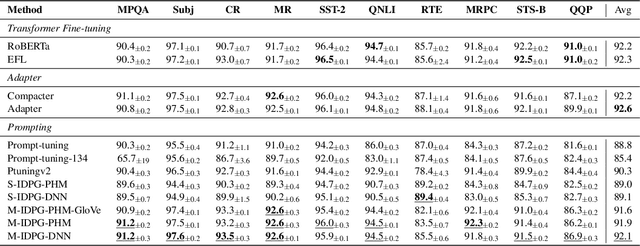

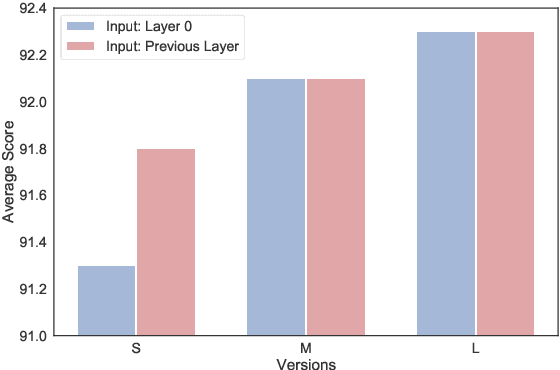
Prompt tuning is a new, efficient NLP transfer learning paradigm that adds a task-specific prompt in each input instance during the model training stage. It freezes the pre-trained language model and only optimizes a few task-specific prompts. In this paper, we propose a conditional prompt generation method to generate prompts for each input instance, referred to as the Instance-Dependent Prompt Generation (IDPG). Unlike traditional prompt tuning methods that use a fixed prompt, IDPG introduces a lightweight and trainable component to generate prompts based on each input sentence. Extensive experiments on ten natural language understanding (NLU) tasks show that the proposed strategy consistently outperforms various prompt tuning baselines and is on par with other efficient transfer learning methods such as Compacter while tuning far fewer model parameters.