 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyDesign: Versatile Area Fashion Editing via Mask-Free Diffusion
Aug 21, 2024



Fashion image editing aims to modify a person's appearance based on a given instruction. Existing methods require auxiliary tools like segmenters and keypoint extractors, lacking a flexible and unified framework. Moreover, these methods are limited in the variety of clothing types they can handle, as most datasets focus on people in clean backgrounds and only include generic garments such as tops, pants, and dresses. These limitations restrict their applicability in real-world scenarios. In this paper, we first extend an existing dataset for human generation to include a wider range of apparel and more complex backgrounds. This extended dataset features people wearing diverse items such as tops, pants, dresses, skirts, headwear, scarves, shoes, socks, and bags. Additionally, we propose AnyDesign, a diffusion-based method that enables mask-free editing on versatile areas. Users can simply input a human image along with a corresponding prompt in either text or image format. Our approach incorporates Fashion DiT, equipped with a Fashion-Guidance Attention (FGA) module designed to fuse explicit apparel types and CLIP-encoded apparel features. Both Qualitative and quantitative experiments demonstrate that our method delivers high-quality fashion editing and outperforms contemporary text-guided fashion editing methods.
Multi-objective Progressive Clustering for Semi-supervised Domain Adaptation in Speaker Verification
Oct 07, 2023



Utilizing the pseudo-labeling algorithm with large-scale unlabeled data becomes crucial for semi-supervised domain adaptation in speaker verification tasks. In this paper, we propose a novel pseudo-labeling method named Multi-objective Progressive Clustering (MoPC), specifically designed for semi-supervised domain adaptation. Firstly, we utilize limited labeled data from the target domain to derive domain-specific descriptors based on multiple distinct objectives, namely within-graph denoising, intra-class denoising and inter-class denoising. Then, the Infomap algorithm is adopted for embedding clustering, and the descriptors are leveraged to further refine the target domain's pseudo-labels. Moreover, to further improve the quality of pseudo labels, we introduce the subcenter-purification and progressive-merging strategy for label denoising. Our proposed MoPC method achieves 4.95% EER and ranked the 1$^{st}$ place on the evaluation set of VoxSRC 2023 track 3. We also conduct additional experiments on the FFSVC dataset and yield promising results.
Robust MelGAN: A robust universal neural vocoder for high-fidelity TTS
Nov 02, 2022



In current two-stage neural text-to-speech (TTS) paradigm, it is ideal to have a universal neural vocoder, once trained, which is robust to imperfect mel-spectrogram predicted from the acoustic model. To this end, we propose Robust MelGAN vocoder by solving the original multi-band MelGAN's metallic sound problem and increasing its generalization ability. Specifically, we introduce a fine-grained network dropout strategy to the generator. With a specifically designed over-smooth handler which separates speech signal intro periodic and aperiodic components, we only perform network dropout to the aperodic components, which alleviates metallic sounding and maintains good speaker similarity. To further improve generalization ability, we introduce several data augmentation methods to augment fake data in the discriminator, including harmonic shift, harmonic noise and phase noise. Experiments show that Robust MelGAN can be used as a universal vocoder, significantly improving sound quality in TTS systems built on various types of data.
Dense Semantic Contrast for Self-Supervised Visual Representation Learning
Sep 16, 2021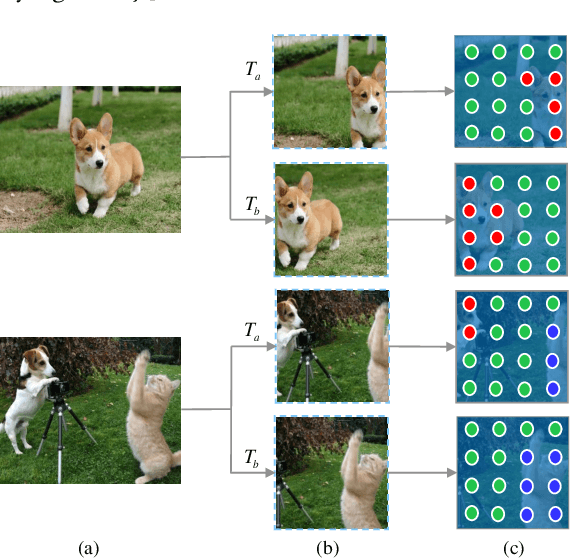
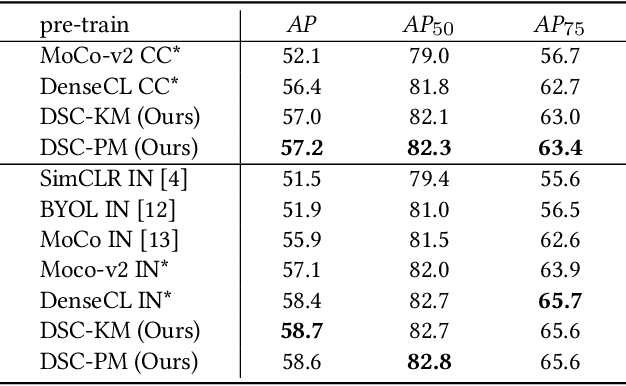
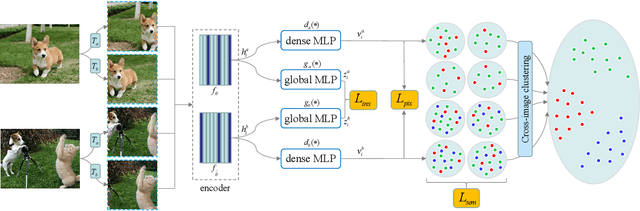
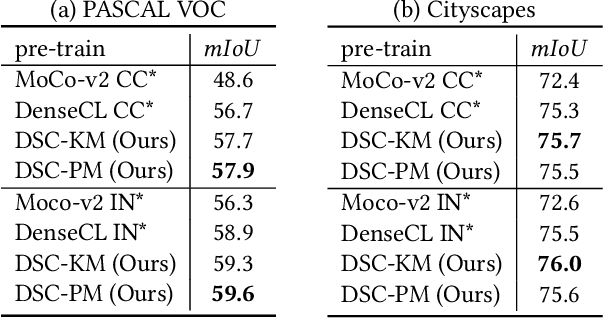
Self-supervised representation learning for visual pre-training has achieved remarkable success with sample (instance or pixel) discrimination and semantics discovery of instance, whereas there still exists a non-negligible gap between pre-trained model and downstream dense prediction tasks. Concretely, these downstream tasks require more accurate representation, in other words, the pixels from the same object must belong to a shared semantic category, which is lacking in the previous methods. In this work, we present Dense Semantic Contrast (DSC) for modeling semantic category decision boundaries at a dense level to meet the requirement of these tasks. Furthermore, we propose a dense cross-image semantic contrastive learning framework for multi-granularity representation learning. Specially, we explicitly explore the semantic structure of the dataset by mining relations among pixels from different perspectives. For intra-image relation modeling, we discover pixel neighbors from multiple views. And for inter-image relations, we enforce pixel representation from the same semantic class to be more similar than the representation from different classes in one mini-batch. Experimental results show that our DSC model outperforms state-of-the-art methods when transferring to downstream dense prediction tasks, including object detection, semantic segmentation, and instance segmentation. Code will be made available.