 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExample-Guided Image Synthesis across Arbitrary Scenes using Masked Spatial-Channel Attention and Self-Supervision
Apr 18, 2020
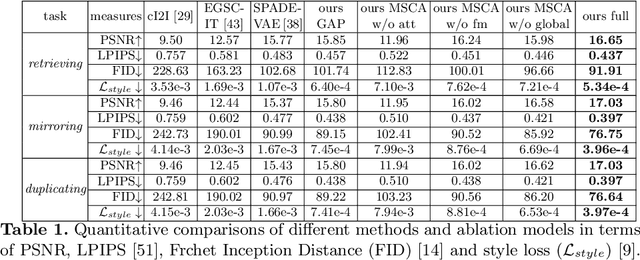

Example-guided image synthesis has recently been attempted to synthesize an image from a semantic label map and an exemplary image. In the task, the additional exemplar image provides the style guidance that controls the appearance of the synthesized output. Despite the controllability advantage, the existing models are designed on datasets with specific and roughly aligned objects. In this paper, we tackle a more challenging and general task, where the exemplar is an arbitrary scene image that is semantically different from the given label map. To this end, we first propose a Masked Spatial-Channel Attention (MSCA) module which models the correspondence between two arbitrary scenes via efficient decoupled attention. Next, we propose an end-to-end network for joint global and local feature alignment and synthesis. Finally, we propose a novel self-supervision task to enable training. Experiments on the large-scale and more diverse COCO-stuff dataset show significant improvements over the existing methods. Moreover, our approach provides interpretability and can be readily extended to other content manipulation tasks including style and spatial interpolation or extrapolation.
Example-Guided Scene Image Synthesis using Masked Spatial-Channel Attention and Patch-Based Self-Supervision
Nov 27, 2019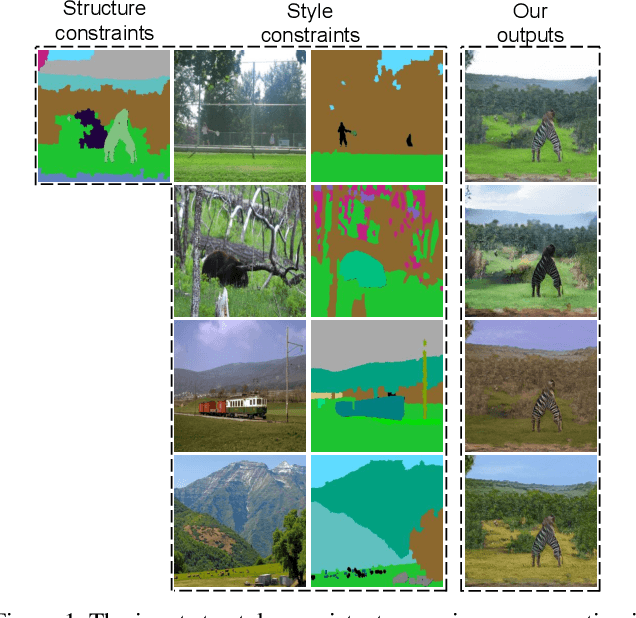
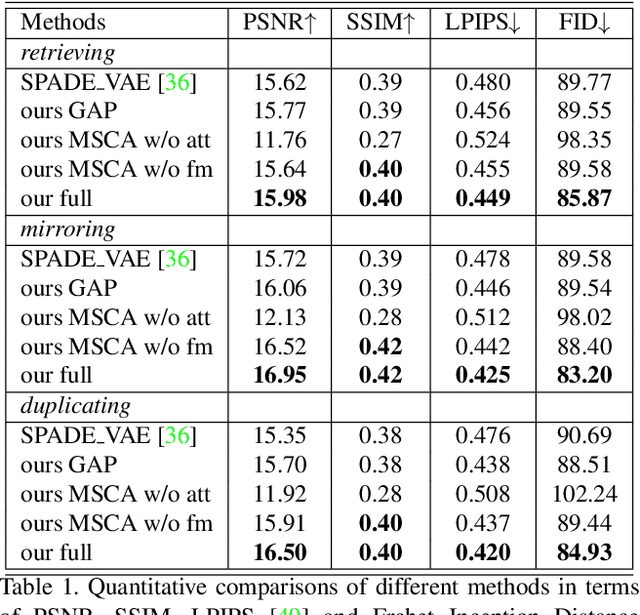
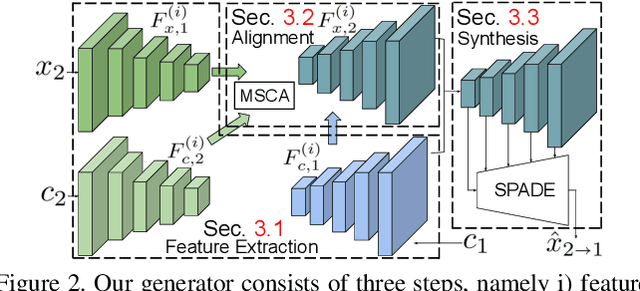
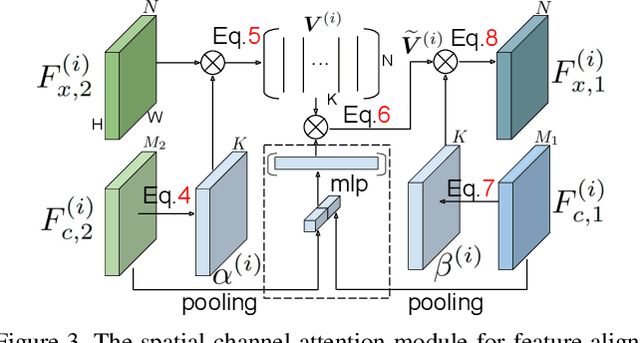
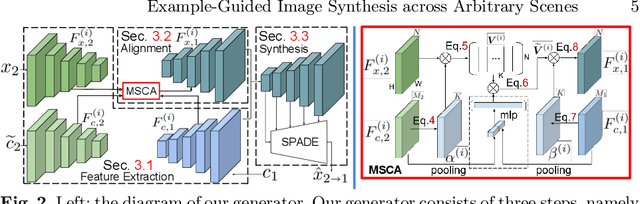
Example-guided image synthesis has been recently attempted to synthesize an image from a semantic label map and an exemplary image. In the task, the additional exemplary image serves to provide style guidance that controls the appearance of the synthesized output. Despite the controllability advantage, the previous models are designed on datasets with specific and roughly aligned objects. In this paper, we tackle a more challenging and general task, where the exemplar is an arbitrary scene image that is semantically unaligned to the given label map. To this end, we first propose a new Masked Spatial-Channel Attention (MSCA) module which models the correspondence between two unstructured scenes via cross-attention. Next, we propose an end-to-end network for joint global and local feature alignment and synthesis. In addition, we propose a novel patch-based self-supervision scheme to enable training. Experiments on the large-scale CCOO-stuff dataset show significant improvements over existing methods. Moreover, our approach provides interpretability and can be readily extended to other tasks including style and spatial interpolation or extrapolation, as well as other content manipulation.
Unsupervised Pose Flow Learning for Pose Guided Synthesis
Sep 30, 2019


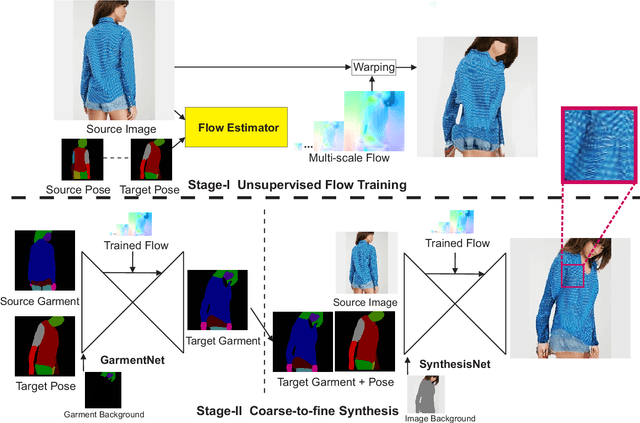
Pose guided synthesis aims to generate a new image in an arbitrary target pose while preserving the appearance details from the source image. Existing approaches rely on either hard-coded spatial transformations or 3D body modeling. They often overlook complex non-rigid pose deformation or unmatched occluded regions, thus fail to effectively preserve appearance information. In this paper, we propose an unsupervised pose flow learning scheme that learns to transfer the appearance details from the source image. Based on such learned pose flow, we proposed GarmentNet and SynthesisNet, both of which use multi-scale feature-domain alignment for coarse-to-fine synthesis. Experiments on the DeepFashion, MVC dataset and additional real-world datasets demonstrate that our approach compares favorably with the state-of-the-art methods and generalizes to unseen poses and clothing styles.
CrossNet: An End-to-end Reference-based Super Resolution Network using Cross-scale Warping
Jul 27, 2018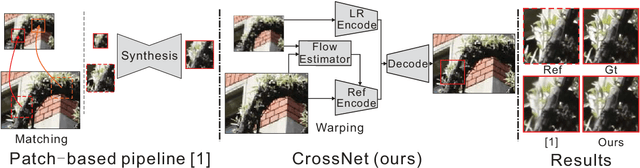
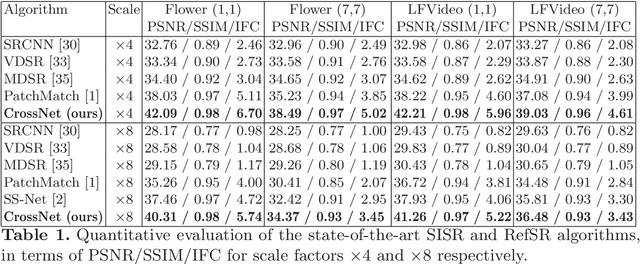
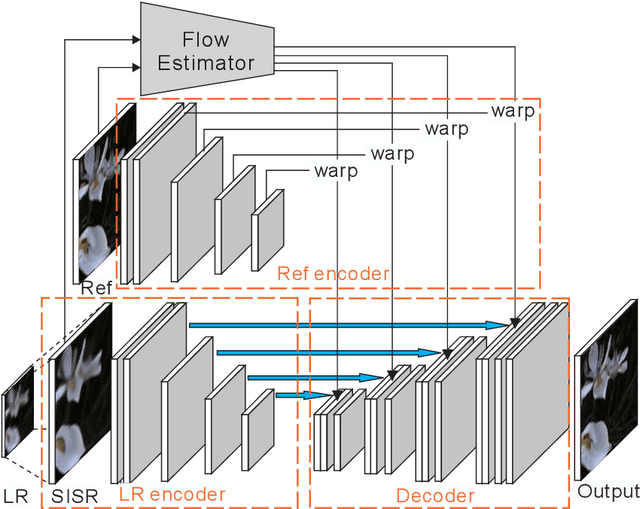
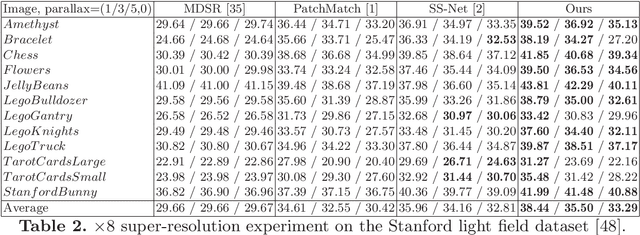
The Reference-based Super-resolution (RefSR) super-resolves a low-resolution (LR) image given an external high-resolution (HR) reference image, where the reference image and LR image share similar viewpoint but with significant resolution gap x8. Existing RefSR methods work in a cascaded way such as patch matching followed by synthesis pipeline with two independently defined objective functions, leading to the inter-patch misalignment, grid effect and inefficient optimization. To resolve these issues, we present CrossNet, an end-to-end and fully-convolutional deep neural network using cross-scale warping. Our network contains image encoders, cross-scale warping layers, and fusion decoder: the encoder serves to extract multi-scale features from both the LR and the reference images; the cross-scale warping layers spatially aligns the reference feature map with the LR feature map; the decoder finally aggregates feature maps from both domains to synthesize the HR output. Using cross-scale warping, our network is able to perform spatial alignment at pixel-level in an end-to-end fashion, which improves the existing schemes both in precision (around 2dB-4dB) and efficiency (more than 100 times faster).
SurfaceNet: An End-to-end 3D Neural Network for Multiview Stereopsis
Aug 05, 2017
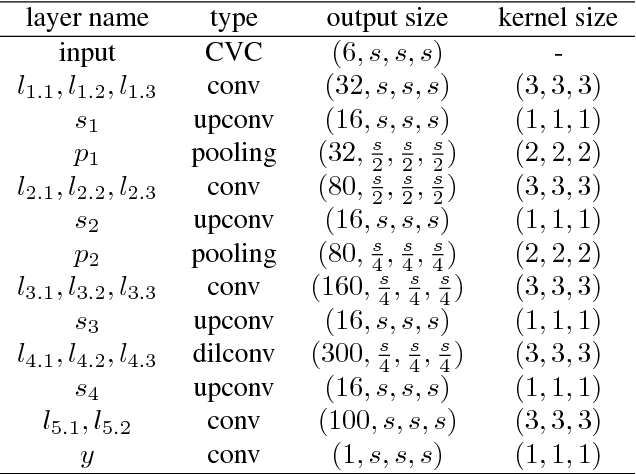
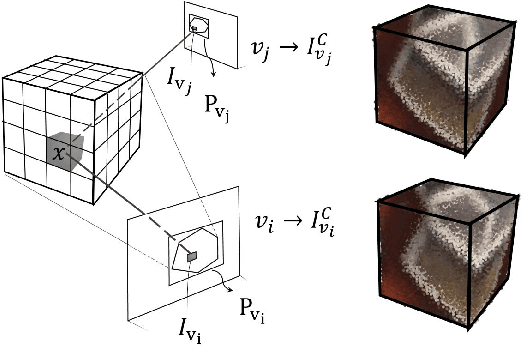
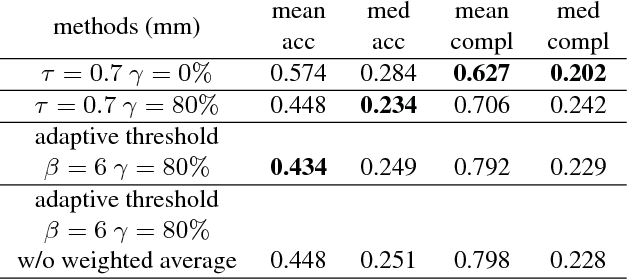
This paper proposes an end-to-end learning framework for multiview stereopsis. We term the network SurfaceNet. It takes a set of images and their corresponding camera parameters as input and directly infers the 3D model. The key advantage of the framework is that both photo-consistency as well geometric relations of the surface structure can be directly learned for the purpose of multiview stereopsis in an end-to-end fashion. SurfaceNet is a fully 3D convolutional network which is achieved by encoding the camera parameters together with the images in a 3D voxel representation. We evaluate SurfaceNet on the large-scale DTU benchmark.
Utilizing High-level Visual Feature for Indoor Shopping Mall Navigation
Feb 18, 2017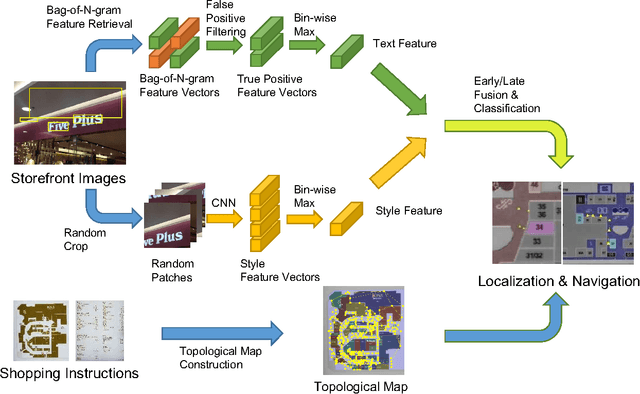
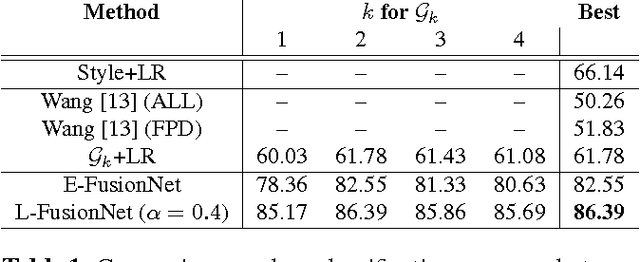

Towards robust and convenient indoor shopping mall navigation, we propose a novel learning-based scheme to utilize the high-level visual information from the storefront images captured by personal devices of users. Specifically, we decompose the visual navigation problem into localization and map generation respectively. Given a storefront input image, a novel feature fusion scheme (denoted as FusionNet) is proposed by fusing the distinguishing DNN-based appearance feature and text feature for robust recognition of store brands, which serves for accurate localization. Regarding the map generation, we convert the user-captured indicator map of the shopping mall into a topological map by parsing the stores and their connectivity. Experimental results conducted on the real shopping malls demonstrate that the proposed system achieves robust localization and precise map generation, enabling accurate navigation.
Deep Learning for Surface Material Classification Using Haptic And Visual Information
May 01, 2016
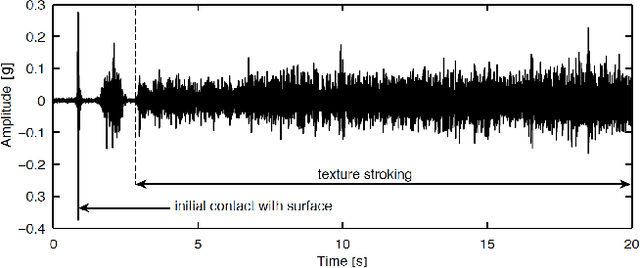

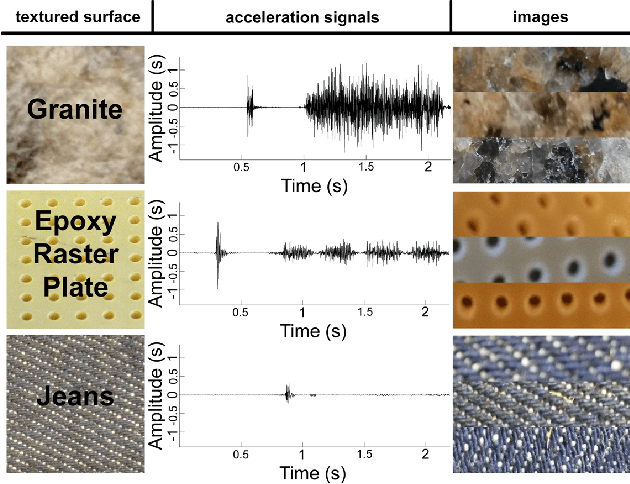
When a user scratches a hand-held rigid tool across an object surface, an acceleration signal can be captured, which carries relevant information about the surface. More importantly, such a haptic signal is complementary to the visual appearance of the surface, which suggests the combination of both modalities for the recognition of the surface material. In this paper, we present a novel deep learning method dealing with the surface material classification problem based on a Fully Convolutional Network (FCN), which takes as input the aforementioned acceleration signal and a corresponding image of the surface texture. Compared to previous surface material classification solutions, which rely on a careful design of hand-crafted domain-specific features, our method automatically extracts discriminative features utilizing the advanced deep learning methodologies. Experiments performed on the TUM surface material database demonstrate that our method achieves state-of-the-art classification accuracy robustly and efficiently.
Learning High-level Prior with Convolutional Neural Networks for Semantic Segmentation
Nov 22, 2015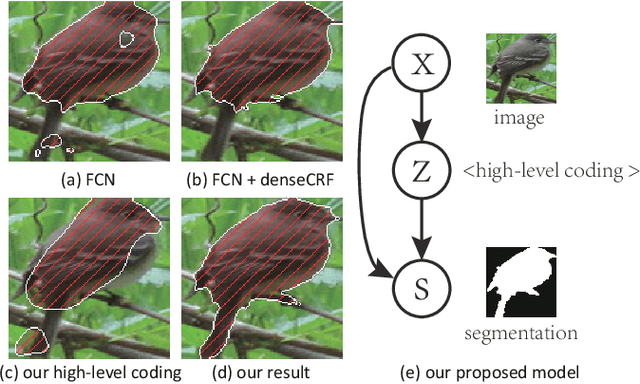
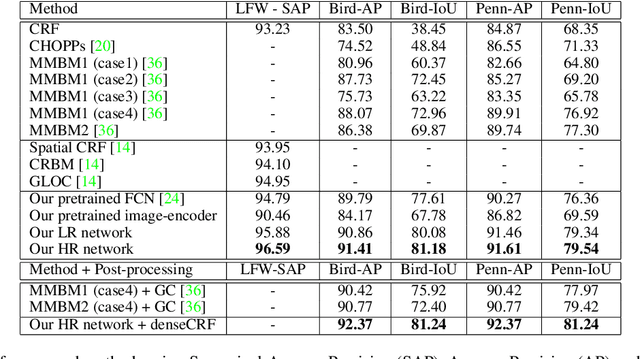
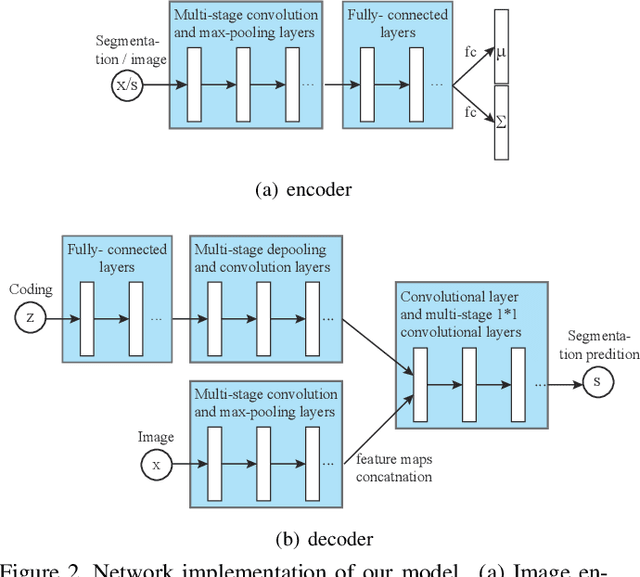
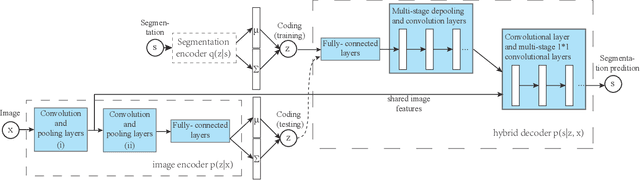
This paper proposes a convolutional neural network that can fuse high-level prior for semantic image segmentation. Motivated by humans' vision recognition system, our key design is a three-layer generative structure consisting of high-level coding, middle-level segmentation and low-level image to introduce global prior for semantic segmentation. Based on this structure, we proposed a generative model called conditional variational auto-encoder (CVAE) that can build up the links behind these three layers. These important links include an image encoder that extracts high level info from image, a segmentation encoder that extracts high level info from segmentation, and a hybrid decoder that outputs semantic segmentation from the high level prior and input image. We theoretically derive the semantic segmentation as an optimization problem parameterized by these links. Finally, the optimization problem enables us to take advantage of state-of-the-art fully convolutional network structure for the implementation of the above encoders and decoder. Experimental results on several representative datasets demonstrate our supreme performance for semantic segmentation.