 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrigger-free Event Detection via Derangement Reading Comprehension
Aug 20, 2022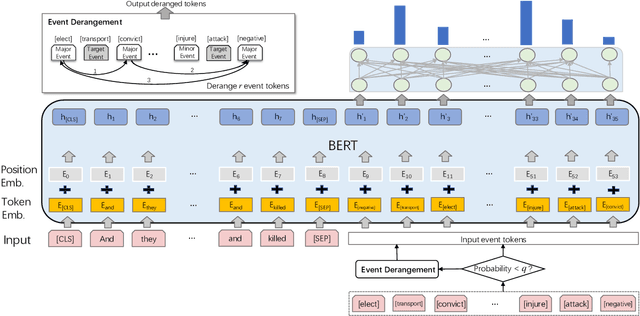
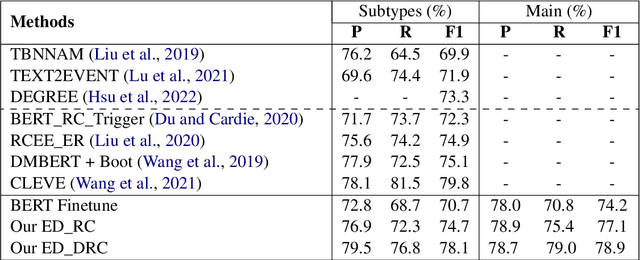
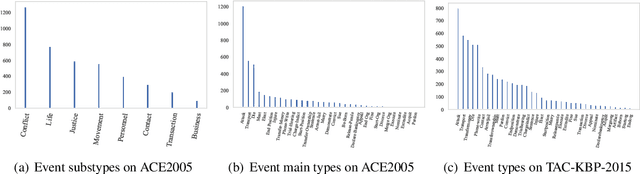
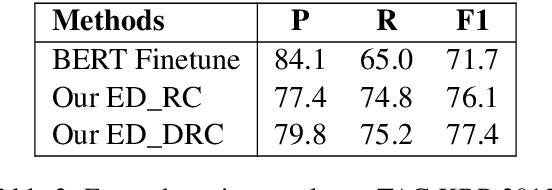
Event detection (ED), aiming to detect events from texts and categorize them, is vital to understanding actual happenings in real life. However, mainstream event detection models require high-quality expert human annotations of triggers, which are often costly and thus deter the application of ED to new domains. Therefore, in this paper, we focus on low-resource ED without triggers and aim to tackle the following formidable challenges: multi-label classification, insufficient clues, and imbalanced events distribution. We propose a novel trigger-free ED method via Derangement mechanism on a machine Reading Comprehension (DRC) framework. More specifically, we treat the input text as Context and concatenate it with all event type tokens that are deemed as Answers with an omitted default question. So we can leverage the self-attention in pre-trained language models to absorb semantic relations between input text and the event types. Moreover, we design a simple yet effective event derangement module (EDM) to prevent major events from being excessively learned so as to yield a more balanced training process. The experiment results show that our proposed trigger-free ED model is remarkably competitive to mainstream trigger-based models, showing its strong performance on low-source event detection.
Vision-and-Language Pretrained Models: A Survey
Apr 28, 2022
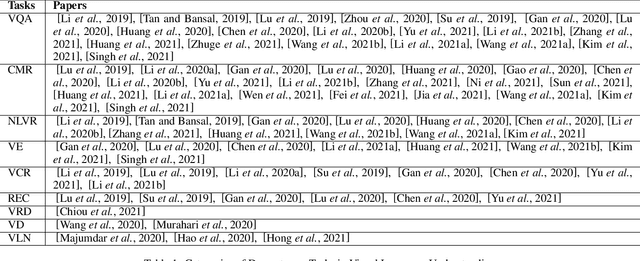
Pretrained models have produced great success in both Computer Vision (CV) and Natural Language Processing (NLP). This progress leads to learning joint representations of vision and language pretraining by feeding visual and linguistic contents into a multi-layer transformer, Visual-Language Pretrained Models (VLPMs). In this paper, we present an overview of the major advances achieved in VLPMs for producing joint representations of vision and language. As the preliminaries, we briefly describe the general task definition and genetic architecture of VLPMs. We first discuss the language and vision data encoding methods and then present the mainstream VLPM structure as the core content. We further summarise several essential pretraining and fine-tuning strategies. Finally, we highlight three future directions for both CV and NLP researchers to provide insightful guidance.
Sequential Attention Module for Natural Language Processing
Sep 07, 2021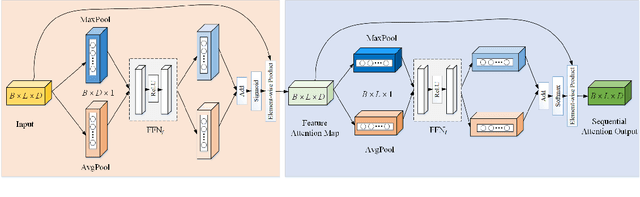
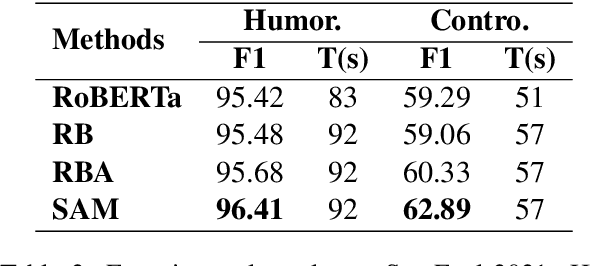

Recently, large pre-trained neural language models have attained remarkable performance on many downstream natural language processing (NLP) applications via fine-tuning. In this paper, we target at how to further improve the token representations on the language models. We, therefore, propose a simple yet effective plug-and-play module, Sequential Attention Module (SAM), on the token embeddings learned from a pre-trained language model. Our proposed SAM consists of two main attention modules deployed sequentially: Feature-wise Attention Module (FAM) and Token-wise Attention Module (TAM). More specifically, FAM can effectively identify the importance of features at each dimension and promote the effect via dot-product on the original token embeddings for downstream NLP applications. Meanwhile, TAM can further re-weight the features at the token-wise level. Moreover, we propose an adaptive filter on FAM to prevent noise impact and increase information absorption. Finally, we conduct extensive experiments to demonstrate the advantages and properties of our proposed SAM. We first show how SAM plays a primary role in the champion solution of two subtasks of SemEval'21 Task 7. After that, we apply SAM on sentiment analysis and three popular NLP tasks and demonstrate that SAM consistently outperforms the state-of-the-art baselines.
RefBERT: Compressing BERT by Referencing to Pre-computed Representations
Jun 11, 2021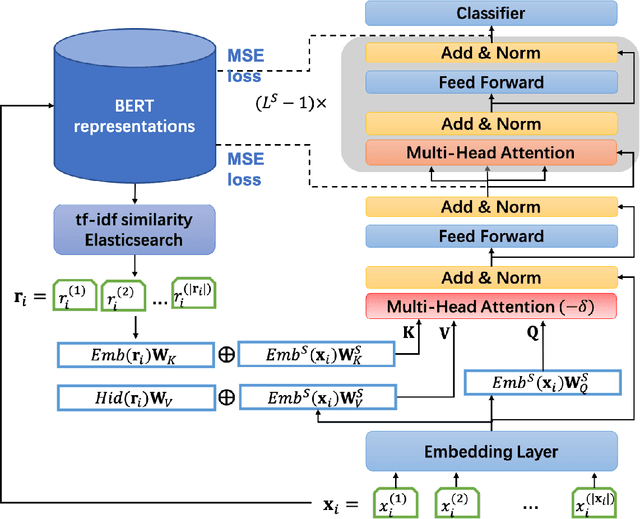

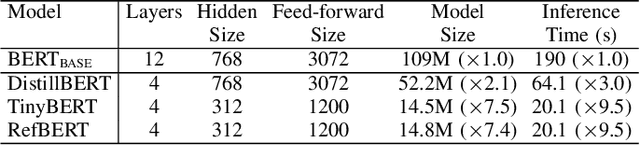
Recently developed large pre-trained language models, e.g., BERT, have achieved remarkable performance in many downstream natural language processing applications. These pre-trained language models often contain hundreds of millions of parameters and suffer from high computation and latency in real-world applications. It is desirable to reduce the computation overhead of the models for fast training and inference while keeping the model performance in downstream applications. Several lines of work utilize knowledge distillation to compress the teacher model to a smaller student model. However, they usually discard the teacher's knowledge when in inference. Differently, in this paper, we propose RefBERT to leverage the knowledge learned from the teacher, i.e., facilitating the pre-computed BERT representation on the reference sample and compressing BERT into a smaller student model. To guarantee our proposal, we provide theoretical justification on the loss function and the usage of reference samples. Significantly, the theoretical result shows that including the pre-computed teacher's representations on the reference samples indeed increases the mutual information in learning the student model. Finally, we conduct the empirical evaluation and show that our RefBERT can beat the vanilla TinyBERT over 8.1\% and achieves more than 94\% of the performance of $\BERTBASE$ on the GLUE benchmark. Meanwhile, RefBERT is 7.4x smaller and 9.5x faster on inference than BERT$_{\rm BASE}$.
Progressive Open-Domain Response Generation with Multiple Controllable Attributes
Jun 07, 2021
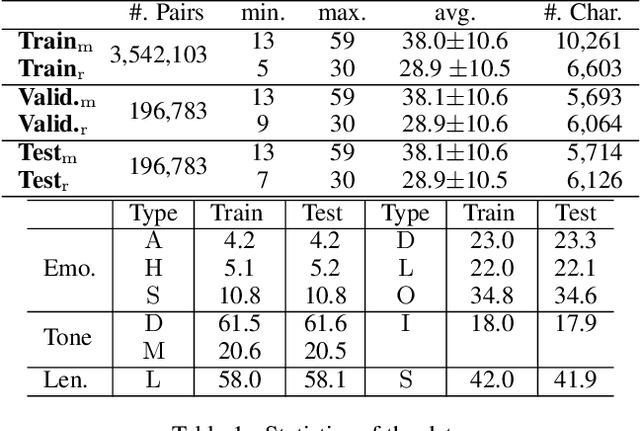
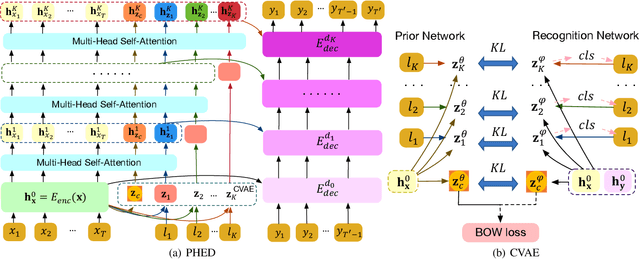
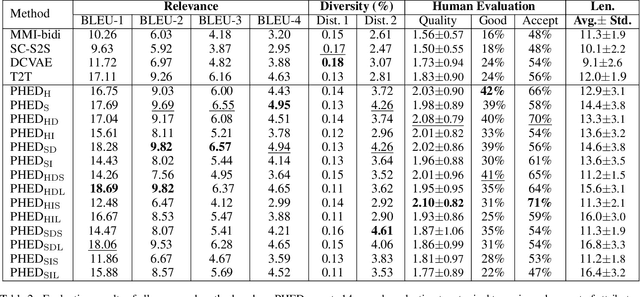
It is desirable to include more controllable attributes to enhance the diversity of generated responses in open-domain dialogue systems. However, existing methods can generate responses with only one controllable attribute or lack a flexible way to generate them with multiple controllable attributes. In this paper, we propose a Progressively trained Hierarchical Encoder-Decoder (PHED) to tackle this task. More specifically, PHED deploys Conditional Variational AutoEncoder (CVAE) on Transformer to include one aspect of attributes at one stage. A vital characteristic of the CVAE is to separate the latent variables at each stage into two types: a global variable capturing the common semantic features and a specific variable absorbing the attribute information at that stage. PHED then couples the CVAE latent variables with the Transformer encoder and is trained by minimizing a newly derived ELBO and controlled losses to produce the next stage's input and produce responses as required. Finally, we conduct extensive evaluations to show that PHED significantly outperforms the state-of-the-art neural generation models and produces more diverse responses as expected.
PALI at SemEval-2021 Task 2: Fine-Tune XLM-RoBERTa for Word in Context Disambiguation
Apr 21, 2021
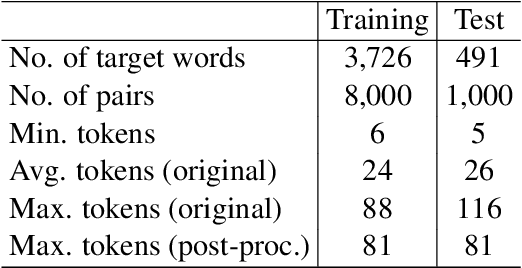

This paper presents the PALI team's winning system for SemEval-2021 Task 2: Multilingual and Cross-lingual Word-in-Context Disambiguation. We fine-tune XLM-RoBERTa model to solve the task of word in context disambiguation, i.e., to determine whether the target word in the two contexts contains the same meaning or not. In the implementation, we first specifically design an input tag to emphasize the target word in the contexts. Second, we construct a new vector on the fine-tuned embeddings from XLM-RoBERTa and feed it to a fully-connected network to output the probability of whether the target word in the context has the same meaning or not. The new vector is attained by concatenating the embedding of the [CLS] token and the embeddings of the target word in the contexts. In training, we explore several tricks, such as the Ranger optimizer, data augmentation, and adversarial training, to improve the model prediction. Consequently, we attain first place in all four cross-lingual tasks.
Sattiy at SemEval-2021 Task 9: An Ensemble Solution for Statement Verification and Evidence Finding with Tables
Apr 21, 2021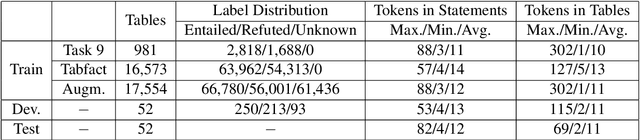
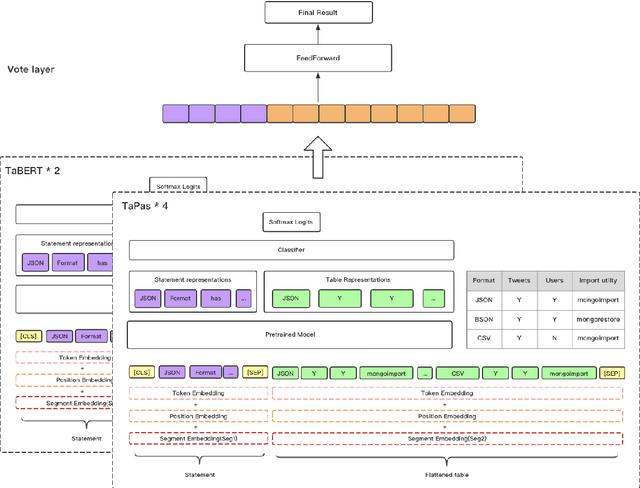
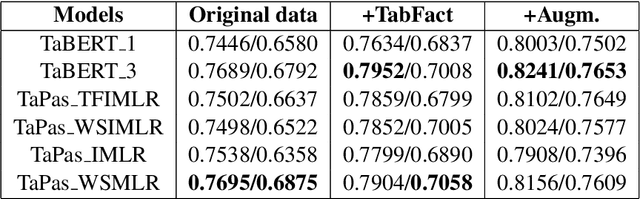
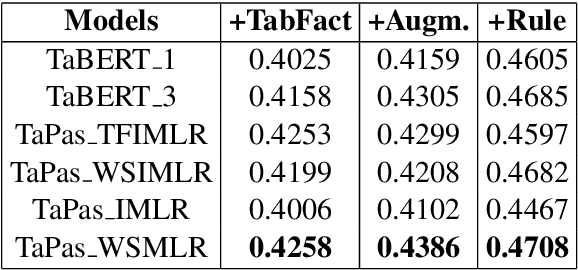
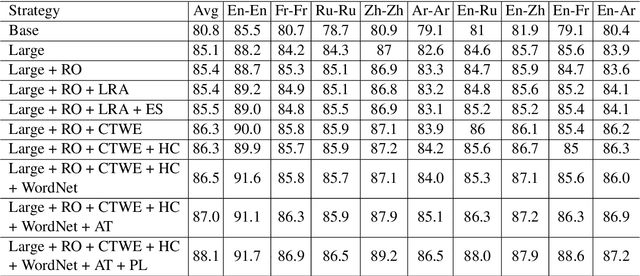
Question answering from semi-structured tables can be seen as a semantic parsing task and is significant and practical for pushing the boundary of natural language understanding. Existing research mainly focuses on understanding contents from unstructured evidence, e.g., news, natural language sentences, and documents. The task of verification from structured evidence, such as tables, charts, and databases, is still less explored. This paper describes sattiy team's system in SemEval-2021 task 9: Statement Verification and Evidence Finding with Tables (SEM-TAB-FACT). This competition aims to verify statements and to find evidence from tables for scientific articles and to promote the proper interpretation of the surrounding article. In this paper, we exploited ensemble models of pre-trained language models over tables, TaPas and TaBERT, for Task A and adjust the result based on some rules extracted for Task B. Finally, in the leaderboard, we attain the F1 scores of 0.8496 and 0.7732 in Task A for the 2-way and 3-way evaluation, respectively, and the F1 score of 0.4856 in Task B.
MagicPai at SemEval-2021 Task 7: Method for Detecting and Rating Humor Based on Multi-Task Adversarial Training
Apr 21, 2021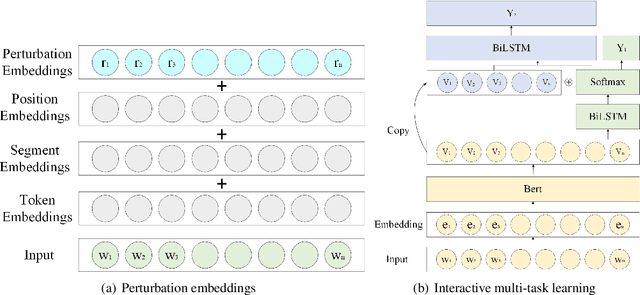
This paper describes MagicPai's system for SemEval 2021 Task 7, HaHackathon: Detecting and Rating Humor and Offense. This task aims to detect whether the text is humorous and how humorous it is. There are four subtasks in the competition. In this paper, we mainly present our solution, a multi-task learning model based on adversarial examples, for task 1a and 1b. More specifically, we first vectorize the cleaned dataset and add the perturbation to obtain more robust embedding representations. We then correct the loss via the confidence level. Finally, we perform interactive joint learning on multiple tasks to capture the relationship between whether the text is humorous and how humorous it is. The final result shows the effectiveness of our system.
* 7 pages, 1 figure, 4 tables
Emotion Dynamics Modeling via BERT
Apr 21, 2021
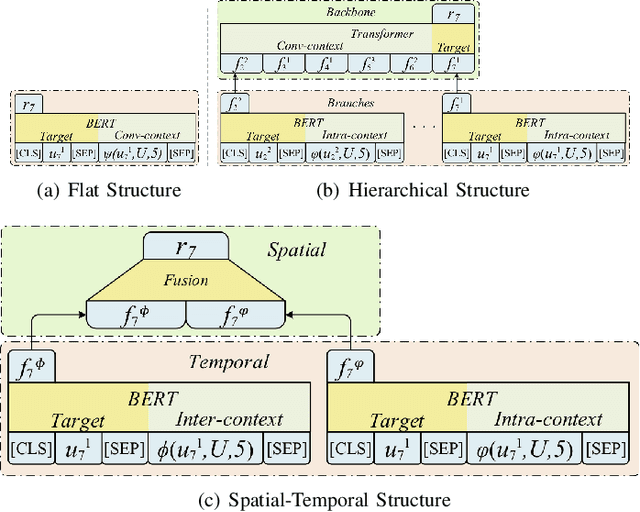
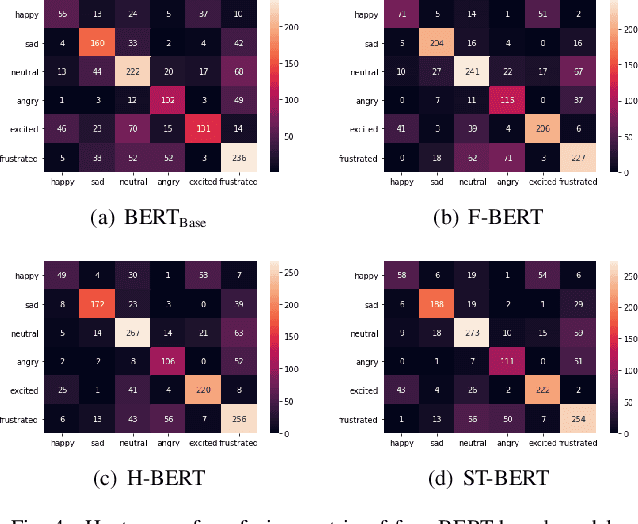
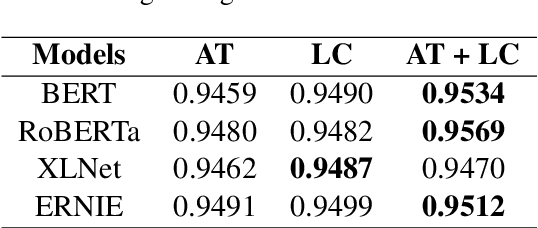
Emotion dynamics modeling is a significant task in emotion recognition in conversation. It aims to predict conversational emotions when building empathetic dialogue systems. Existing studies mainly develop models based on Recurrent Neural Networks (RNNs). They cannot benefit from the power of the recently-developed pre-training strategies for better token representation learning in conversations. More seriously, it is hard to distinguish the dependency of interlocutors and the emotional influence among interlocutors by simply assembling the features on top of RNNs. In this paper, we develop a series of BERT-based models to specifically capture the inter-interlocutor and intra-interlocutor dependencies of the conversational emotion dynamics. Concretely, we first substitute BERT for RNNs to enrich the token representations. Then, a Flat-structured BERT (F-BERT) is applied to link up utterances in a conversation directly, and a Hierarchically-structured BERT (H-BERT) is employed to distinguish the interlocutors when linking up utterances. More importantly, a Spatial-Temporal-structured BERT, namely ST-BERT, is proposed to further determine the emotional influence among interlocutors. Finally, we conduct extensive experiments on two popular emotion recognition in conversation benchmark datasets and demonstrate that our proposed models can attain around 5\% and 10\% improvement over the state-of-the-art baselines, respectively.
KGSynNet: A Novel Entity Synonyms Discovery Framework with Knowledge Graph
Apr 01, 2021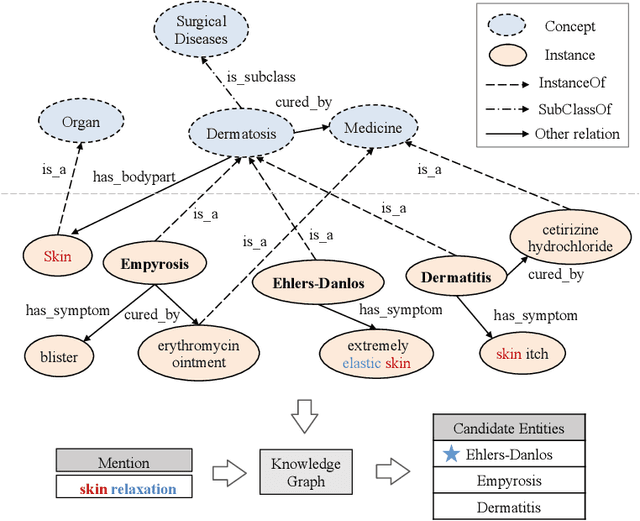
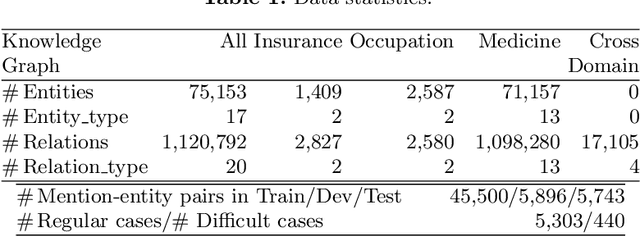
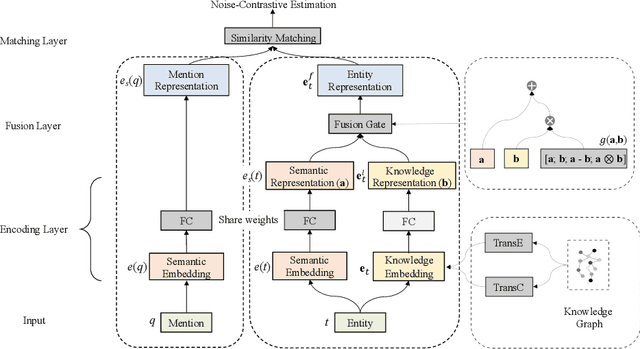
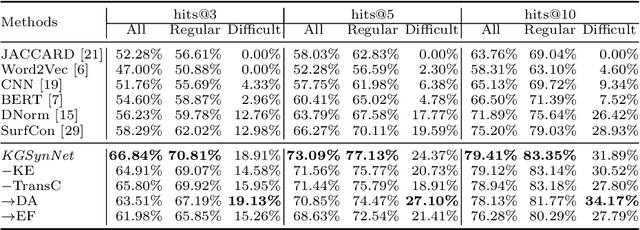
Entity synonyms discovery is crucial for entity-leveraging applications. However, existing studies suffer from several critical issues: (1) the input mentions may be out-of-vocabulary (OOV) and may come from a different semantic space of the entities; (2) the connection between mentions and entities may be hidden and cannot be established by surface matching; and (3) some entities rarely appear due to the long-tail effect. To tackle these challenges, we facilitate knowledge graphs and propose a novel entity synonyms discovery framework, named \emph{KGSynNet}. Specifically, we pre-train subword embeddings for mentions and entities using a large-scale domain-specific corpus while learning the knowledge embeddings of entities via a joint TransC-TransE model. More importantly, to obtain a comprehensive representation of entities, we employ a specifically designed \emph{fusion gate} to adaptively absorb the entities' knowledge information into their semantic features. We conduct extensive experiments to demonstrate the effectiveness of our \emph{KGSynNet} in leveraging the knowledge graph. The experimental results show that the \emph{KGSynNet} improves the state-of-the-art methods by 14.7\% in terms of hits@3 in the offline evaluation and outperforms the BERT model by 8.3\% in the positive feedback rate of an online A/B test on the entity linking module of a question answering system.