 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Graph Neural Network with Cross-Attention for Cross-Device User Matching
Apr 06, 2023Cross-device user matching is a critical problem in numerous domains, including advertising, recommender systems, and cybersecurity. It involves identifying and linking different devices belonging to the same person, utilizing sequence logs. Previous data mining techniques have struggled to address the long-range dependencies and higher-order connections between the logs. Recently, researchers have modeled this problem as a graph problem and proposed a two-tier graph contextual embedding (TGCE) neural network architecture, which outperforms previous methods. In this paper, we propose a novel hierarchical graph neural network architecture (HGNN), which has a more computationally efficient second level design than TGCE. Furthermore, we introduce a cross-attention (Cross-Att) mechanism in our model, which improves performance by 5% compared to the state-of-the-art TGCE method.
Graph Positional Encoding via Random Feature Propagation
Mar 08, 2023Two main families of node feature augmentation schemes have been explored for enhancing GNNs: random features and spectral positional encoding. Surprisingly, however, there is still no clear understanding of the relation between these two augmentation schemes. Here we propose a novel family of positional encoding schemes which draws a link between the above two approaches and improves over both. The new approach, named Random Feature Propagation (RFP), is inspired by the power iteration method and its generalizations. It concatenates several intermediate steps of an iterative algorithm for computing the dominant eigenvectors of a propagation matrix, starting from random node features. Notably, these propagation steps are based on graph-dependent propagation operators that can be either predefined or learned. We explore the theoretical and empirical benefits of RFP. First, we provide theoretical justifications for using random features, for incorporating early propagation steps, and for using multiple random initializations. Then, we empirically demonstrate that RFP significantly outperforms both spectral PE and random features in multiple node classification and graph classification benchmarks.
Equivariant Polynomials for Graph Neural Networks
Feb 22, 2023Graph Neural Networks (GNN) are inherently limited in their expressive power. Recent seminal works (Xu et al., 2019; Morris et al., 2019b) introduced the Weisfeiler-Lehman (WL) hierarchy as a measure of expressive power. Although this hierarchy has propelled significant advances in GNN analysis and architecture developments, it suffers from several significant limitations. These include a complex definition that lacks direct guidance for model improvement and a WL hierarchy that is too coarse to study current GNNs. This paper introduces an alternative expressive power hierarchy based on the ability of GNNs to calculate equivariant polynomials of a certain degree. As a first step, we provide a full characterization of all equivariant graph polynomials by introducing a concrete basis, significantly generalizing previous results. Each basis element corresponds to a specific multi-graph, and its computation over some graph data input corresponds to a tensor contraction problem. Second, we propose algorithmic tools for evaluating the expressiveness of GNNs using tensor contraction sequences, and calculate the expressive power of popular GNNs. Finally, we enhance the expressivity of common GNN architectures by adding polynomial features or additional operations / aggregations inspired by our theory. These enhanced GNNs demonstrate state-of-the-art results in experiments across multiple graph learning benchmarks.
Equivariant Architectures for Learning in Deep Weight Spaces
Jan 30, 2023



Designing machine learning architectures for processing neural networks in their raw weight matrix form is a newly introduced research direction. Unfortunately, the unique symmetry structure of deep weight spaces makes this design very challenging. If successful, such architectures would be capable of performing a wide range of intriguing tasks, from adapting a pre-trained network to a new domain to editing objects represented as functions (INRs or NeRFs). As a first step towards this goal, we present here a novel network architecture for learning in deep weight spaces. It takes as input a concatenation of weights and biases of a pre-trained MLP and processes it using a composition of layers that are equivariant to the natural permutation symmetry of the MLP's weights: Changing the order of neurons in intermediate layers of the MLP does not affect the function it represents. We provide a full characterization of all affine equivariant and invariant layers for these symmetries and show how these layers can be implemented using three basic operations: pooling, broadcasting, and fully connected layers applied to the input in an appropriate manner. We demonstrate the effectiveness of our architecture and its advantages over natural baselines in a variety of learning tasks.
Generalized Laplacian Positional Encoding for Graph Representation Learning
Nov 10, 2022



Graph neural networks (GNNs) are the primary tool for processing graph-structured data. Unfortunately, the most commonly used GNNs, called Message Passing Neural Networks (MPNNs) suffer from several fundamental limitations. To overcome these limitations, recent works have adapted the idea of positional encodings to graph data. This paper draws inspiration from the recent success of Laplacian-based positional encoding and defines a novel family of positional encoding schemes for graphs. We accomplish this by generalizing the optimization problem that defines the Laplace embedding to more general dissimilarity functions rather than the 2-norm used in the original formulation. This family of positional encodings is then instantiated by considering p-norms. We discuss a method for calculating these positional encoding schemes, implement it in PyTorch and demonstrate how the resulting positional encoding captures different properties of the graph. Furthermore, we demonstrate that this novel family of positional encodings can improve the expressive power of MPNNs. Lastly, we present preliminary experimental results.
Understanding and Extending Subgraph GNNs by Rethinking Their Symmetries
Jun 22, 2022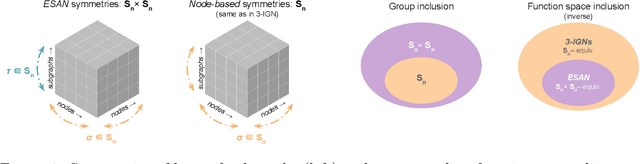
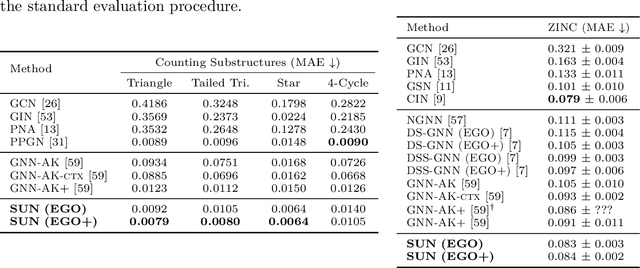
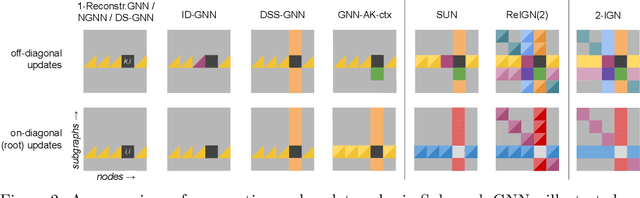
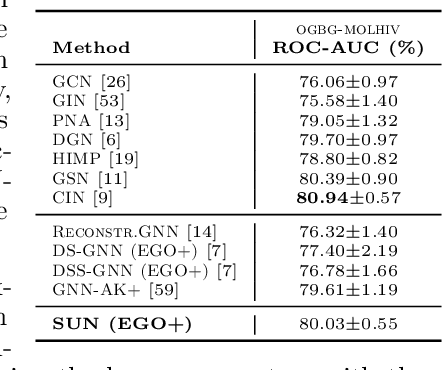
Subgraph GNNs are a recent class of expressive Graph Neural Networks (GNNs) which model graphs as collections of subgraphs. So far, the design space of possible Subgraph GNN architectures as well as their basic theoretical properties are still largely unexplored. In this paper, we study the most prominent form of subgraph methods, which employs node-based subgraph selection policies such as ego-networks or node marking and deletion. We address two central questions: (1) What is the upper-bound of the expressive power of these methods? and (2) What is the family of equivariant message passing layers on these sets of subgraphs?. Our first step in answering these questions is a novel symmetry analysis which shows that modelling the symmetries of node-based subgraph collections requires a significantly smaller symmetry group than the one adopted in previous works. This analysis is then used to establish a link between Subgraph GNNs and Invariant Graph Networks (IGNs). We answer the questions above by first bounding the expressive power of subgraph methods by 3-WL, and then proposing a general family of message-passing layers for subgraph methods that generalises all previous node-based Subgraph GNNs. Finally, we design a novel Subgraph GNN dubbed SUN, which theoretically unifies previous architectures while providing better empirical performance on multiple benchmarks.
Optimizing Tensor Network Contraction Using Reinforcement Learning
Apr 18, 2022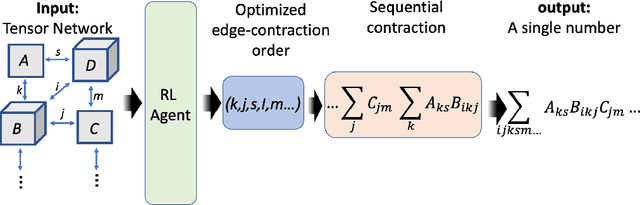
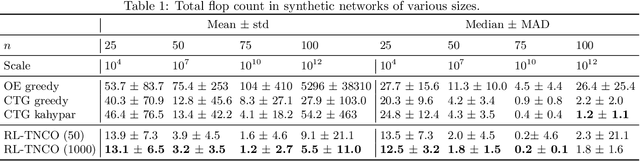
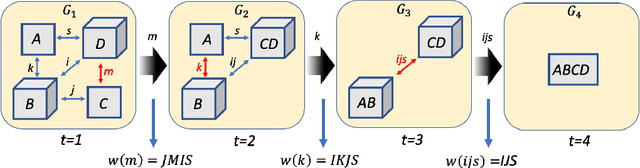

Quantum Computing (QC) stands to revolutionize computing, but is currently still limited. To develop and test quantum algorithms today, quantum circuits are often simulated on classical computers. Simulating a complex quantum circuit requires computing the contraction of a large network of tensors. The order (path) of contraction can have a drastic effect on the computing cost, but finding an efficient order is a challenging combinatorial optimization problem. We propose a Reinforcement Learning (RL) approach combined with Graph Neural Networks (GNN) to address the contraction ordering problem. The problem is extremely challenging due to the huge search space, the heavy-tailed reward distribution, and the challenging credit assignment. We show how a carefully implemented RL-agent that uses a GNN as the basic policy construct can address these challenges and obtain significant improvements over state-of-the-art techniques in three varieties of circuits, including the largest scale networks used in contemporary QC.
Sign and Basis Invariant Networks for Spectral Graph Representation Learning
Apr 11, 2022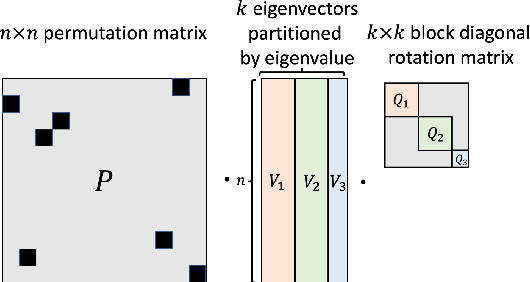
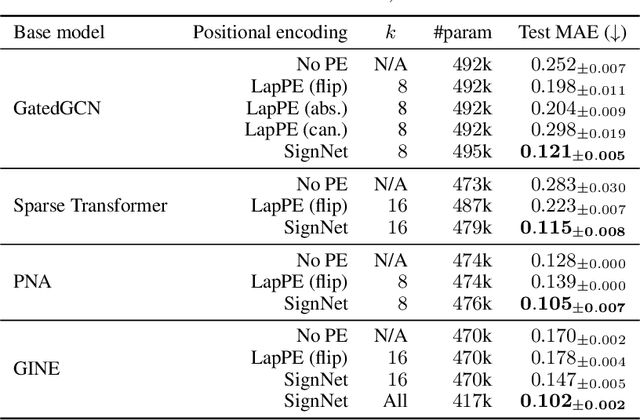

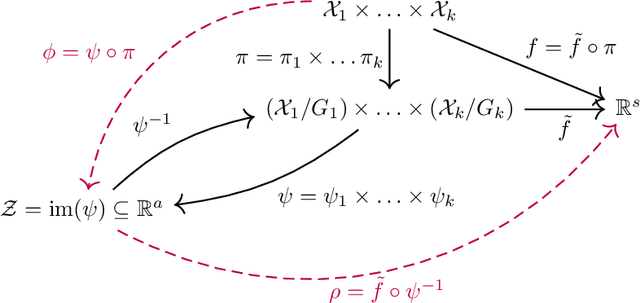
Many machine learning tasks involve processing eigenvectors derived from data. Especially valuable are Laplacian eigenvectors, which capture useful structural information about graphs and other geometric objects. However, ambiguities arise when computing eigenvectors: for each eigenvector $v$, the sign flipped $-v$ is also an eigenvector. More generally, higher dimensional eigenspaces contain infinitely many choices of basis eigenvectors. These ambiguities make it a challenge to process eigenvectors and eigenspaces in a consistent way. In this work we introduce SignNet and BasisNet -- new neural architectures that are invariant to all requisite symmetries and hence process collections of eigenspaces in a principled manner. Our networks are universal, i.e., they can approximate any continuous function of eigenvectors with the proper invariances. They are also theoretically strong for graph representation learning -- they can approximate any spectral graph convolution, can compute spectral invariants that go beyond message passing neural networks, and can provably simulate previously proposed graph positional encodings. Experiments show the strength of our networks for molecular graph regression, learning expressive graph representations, and learning implicit neural representations on triangle meshes. Our code is available at https://github.com/cptq/SignNet-BasisNet .
A Simple and Universal Rotation Equivariant Point-cloud Network
Mar 03, 2022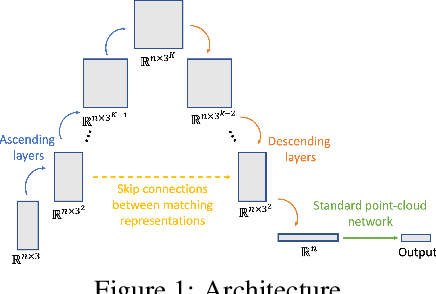
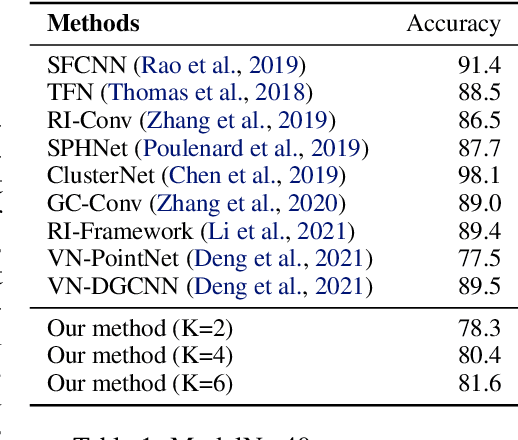
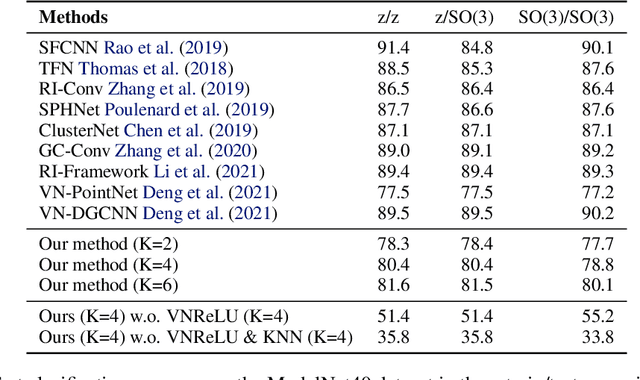
Equivariance to permutations and rigid motions is an important inductive bias for various 3D learning problems. Recently it has been shown that the equivariant Tensor Field Network architecture is universal -- it can approximate any equivariant function. In this paper we suggest a much simpler architecture, prove that it enjoys the same universality guarantees and evaluate its performance on Modelnet40. The code to reproduce our experiments is available at \url{https://github.com/simpleinvariance/UniversalNetwork}
Multi-Task Learning as a Bargaining Game
Feb 02, 2022



In Multi-task learning (MTL), a joint model is trained to simultaneously make predictions for several tasks. Joint training reduces computation costs and improves data efficiency; however, since the gradients of these different tasks may conflict, training a joint model for MTL often yields lower performance than its corresponding single-task counterparts. A common method for alleviating this issue is to combine per-task gradients into a joint update direction using a particular heuristic. In this paper, we propose viewing the gradients combination step as a bargaining game, where tasks negotiate to reach an agreement on a joint direction of parameter update. Under certain assumptions, the bargaining problem has a unique solution, known as the Nash Bargaining Solution, which we propose to use as a principled approach to multi-task learning. We describe a new MTL optimization procedure, Nash-MTL, and derive theoretical guarantees for its convergence. Empirically, we show that Nash-MTL achieves state-of-the-art results on multiple MTL benchmarks in various domains.