 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Evaluation of Federated Contextual Bandit Algorithms
Mar 17, 2023As the adoption of federated learning increases for learning from sensitive data local to user devices, it is natural to ask if the learning can be done using implicit signals generated as users interact with the applications of interest, rather than requiring access to explicit labels which can be difficult to acquire in many tasks. We approach such problems with the framework of federated contextual bandits, and develop variants of prominent contextual bandit algorithms from the centralized seting for the federated setting. We carefully evaluate these algorithms in a range of scenarios simulated using publicly available datasets. Our simulations model typical setups encountered in the real-world, such as various misalignments between an initial pre-trained model and the subsequent user interactions due to non-stationarity in the data and/or heterogeneity across clients. Our experiments reveal the surprising effectiveness of the simple and commonly used softmax heuristic in balancing the well-know exploration-exploitation tradeoff across the breadth of our settings.
How to DP-fy ML: A Practical Guide to Machine Learning with Differential Privacy
Mar 02, 2023



ML models are ubiquitous in real world applications and are a constant focus of research. At the same time, the community has started to realize the importance of protecting the privacy of ML training data. Differential Privacy (DP) has become a gold standard for making formal statements about data anonymization. However, while some adoption of DP has happened in industry, attempts to apply DP to real world complex ML models are still few and far between. The adoption of DP is hindered by limited practical guidance of what DP protection entails, what privacy guarantees to aim for, and the difficulty of achieving good privacy-utility-computation trade-offs for ML models. Tricks for tuning and maximizing performance are scattered among papers or stored in the heads of practitioners. Furthermore, the literature seems to present conflicting evidence on how and whether to apply architectural adjustments and which components are "safe" to use with DP. This work is a self-contained guide that gives an in-depth overview of the field of DP ML and presents information about achieving the best possible DP ML model with rigorous privacy guarantees. Our target audience is both researchers and practitioners. Researchers interested in DP for ML will benefit from a clear overview of current advances and areas for improvement. We include theory-focused sections that highlight important topics such as privacy accounting and its assumptions, and convergence. For a practitioner, we provide a background in DP theory and a clear step-by-step guide for choosing an appropriate privacy definition and approach, implementing DP training, potentially updating the model architecture, and tuning hyperparameters. For both researchers and practitioners, consistently and fully reporting privacy guarantees is critical, and so we propose a set of specific best practices for stating guarantees.
One-shot Empirical Privacy Estimation for Federated Learning
Feb 08, 2023



Privacy auditing techniques for differentially private (DP) algorithms are useful for estimating the privacy loss to compare against analytical bounds, or empirically measure privacy in settings where known analytical bounds on the DP loss are not tight. However, existing privacy auditing techniques usually make strong assumptions on the adversary (e.g., knowledge of intermediate model iterates or the training data distribution), are tailored to specific tasks and model architectures, and require retraining the model many times (typically on the order of thousands). These shortcomings make deploying such techniques at scale difficult in practice, especially in federated settings where model training can take days or weeks. In this work, we present a novel "one-shot" approach that can systematically address these challenges, allowing efficient auditing or estimation of the privacy loss of a model during the same, single training run used to fit model parameters. Our privacy auditing method for federated learning does not require a priori knowledge about the model architecture or task. We show that our method provides provably correct estimates for privacy loss under the Gaussian mechanism, and we demonstrate its performance on a well-established FL benchmark dataset under several adversarial models.
Differentially Private Adaptive Optimization with Delayed Preconditioners
Dec 01, 2022Privacy noise may negate the benefits of using adaptive optimizers in differentially private model training. Prior works typically address this issue by using auxiliary information (e.g., public data) to boost the effectiveness of adaptive optimization. In this work, we explore techniques to estimate and efficiently adapt to gradient geometry in private adaptive optimization without auxiliary data. Motivated by the observation that adaptive methods can tolerate stale preconditioners, we propose differentially private adaptive training with delayed preconditioners (DP^2), a simple method that constructs delayed but less noisy preconditioners to better realize the benefits of adaptivity. Theoretically, we provide convergence guarantees for our method for both convex and non-convex problems, and analyze trade-offs between delay and privacy noise reduction. Empirically, we explore DP^2 across several real-world datasets, demonstrating that it can improve convergence speed by as much as 4x relative to non-adaptive baselines and match the performance of state-of-the-art optimization methods that require auxiliary data.
Learning to Generate Image Embeddings with User-level Differential Privacy
Nov 20, 2022



Small on-device models have been successfully trained with user-level differential privacy (DP) for next word prediction and image classification tasks in the past. However, existing methods can fail when directly applied to learn embedding models using supervised training data with a large class space. To achieve user-level DP for large image-to-embedding feature extractors, we propose DP-FedEmb, a variant of federated learning algorithms with per-user sensitivity control and noise addition, to train from user-partitioned data centralized in the datacenter. DP-FedEmb combines virtual clients, partial aggregation, private local fine-tuning, and public pretraining to achieve strong privacy utility trade-offs. We apply DP-FedEmb to train image embedding models for faces, landmarks and natural species, and demonstrate its superior utility under same privacy budget on benchmark datasets DigiFace, EMNIST, GLD and iNaturalist. We further illustrate it is possible to achieve strong user-level DP guarantees of $\epsilon<2$ while controlling the utility drop within 5%, when millions of users can participate in training.
Multi-Epoch Matrix Factorization Mechanisms for Private Machine Learning
Nov 12, 2022



We introduce new differentially private (DP) mechanisms for gradient-based machine learning (ML) training involving multiple passes (epochs) of a dataset, substantially improving the achievable privacy-utility-computation tradeoffs. Our key contribution is an extension of the online matrix factorization DP mechanism to multiple participations, substantially generalizing the approach of DMRST2022. We first give conditions under which it is possible to reduce the problem with per-iteration vector contributions to the simpler one of scalar contributions. Using this, we formulate the construction of optimal (in total squared error at each iterate) matrix mechanisms for SGD variants as a convex program. We propose an efficient optimization algorithm via a closed form solution to the dual function. While tractable, both solving the convex problem offline and computing the necessary noise masks during training can become prohibitively expensive when many training steps are necessary. To address this, we design a Fourier-transform-based mechanism with significantly less computation and only a minor utility decrease. Extensive empirical evaluation on two tasks: example-level DP for image classification and user-level DP for language modeling, demonstrate substantial improvements over the previous state-of-the-art. Though our primary application is to ML, we note our main DP results are applicable to arbitrary linear queries and hence may have much broader applicability.
A Field Guide to Federated Optimization
Jul 14, 2021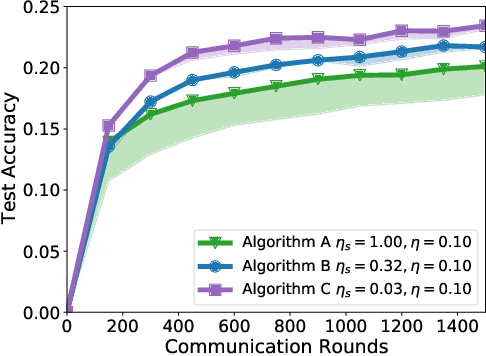


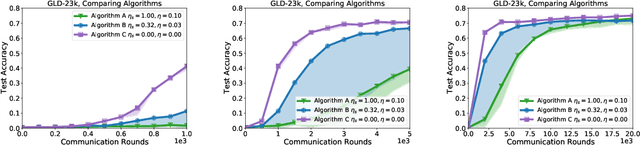
Federated learning and analytics are a distributed approach for collaboratively learning models (or statistics) from decentralized data, motivated by and designed for privacy protection. The distributed learning process can be formulated as solving federated optimization problems, which emphasize communication efficiency, data heterogeneity, compatibility with privacy and system requirements, and other constraints that are not primary considerations in other problem settings. This paper provides recommendations and guidelines on formulating, designing, evaluating and analyzing federated optimization algorithms through concrete examples and practical implementation, with a focus on conducting effective simulations to infer real-world performance. The goal of this work is not to survey the current literature, but to inspire researchers and practitioners to design federated learning algorithms that can be used in various practical applications.
Training Production Language Models without Memorizing User Data
Sep 21, 2020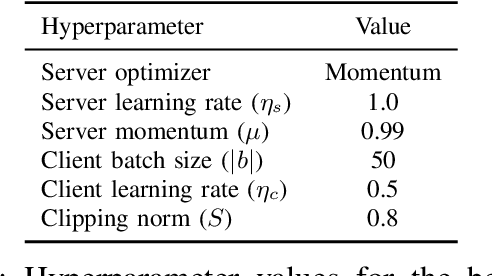
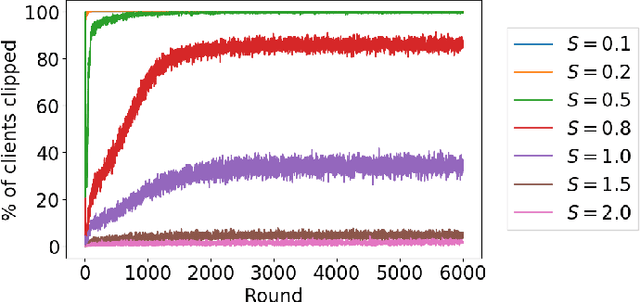
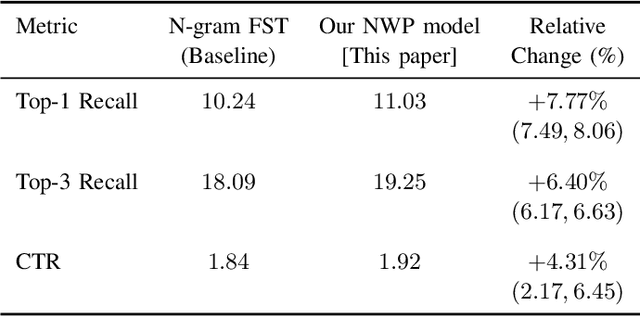
This paper presents the first consumer-scale next-word prediction (NWP) model trained with Federated Learning (FL) while leveraging the Differentially Private Federated Averaging (DP-FedAvg) technique. There has been prior work on building practical FL infrastructure, including work demonstrating the feasibility of training language models on mobile devices using such infrastructure. It has also been shown (in simulations on a public corpus) that it is possible to train NWP models with user-level differential privacy using the DP-FedAvg algorithm. Nevertheless, training production-quality NWP models with DP-FedAvg in a real-world production environment on a heterogeneous fleet of mobile phones requires addressing numerous challenges. For instance, the coordinating central server has to keep track of the devices available at the start of each round and sample devices uniformly at random from them, while ensuring \emph{secrecy of the sample}, etc. Unlike all prior privacy-focused FL work of which we are aware, for the first time we demonstrate the deployment of a differentially private mechanism for the training of a production neural network in FL, as well as the instrumentation of the production training infrastructure to perform an end-to-end empirical measurement of unintended memorization.
Privacy Amplification via Random Check-Ins
Jul 30, 2020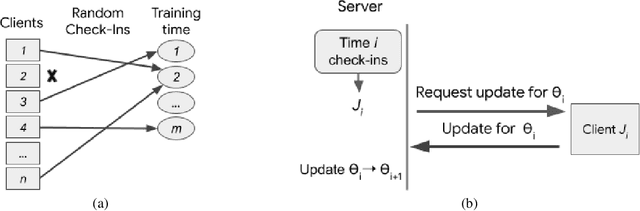

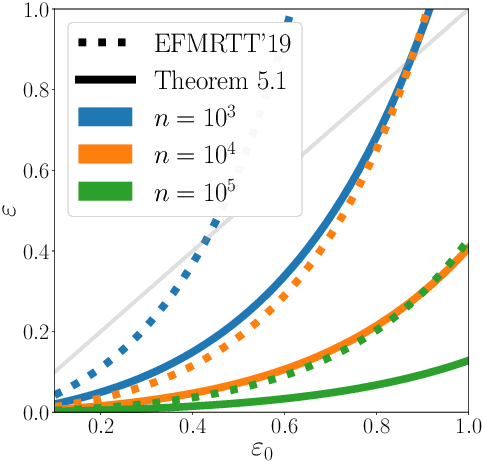
Differentially Private Stochastic Gradient Descent (DP-SGD) forms a fundamental building block in many applications for learning over sensitive data. Two standard approaches, privacy amplification by subsampling, and privacy amplification by shuffling, permit adding lower noise in DP-SGD than via na\"{\i}ve schemes. A key assumption in both these approaches is that the elements in the data set can be uniformly sampled, or be uniformly permuted -- constraints that may become prohibitive when the data is processed in a decentralized or distributed fashion. In this paper, we focus on conducting iterative methods like DP-SGD in the setting of federated learning (FL) wherein the data is distributed among many devices (clients). Our main contribution is the \emph{random check-in} distributed protocol, which crucially relies only on randomized participation decisions made locally and independently by each client. It has privacy/accuracy trade-offs similar to privacy amplification by subsampling/shuffling. However, our method does not require server-initiated communication, or even knowledge of the population size. To our knowledge, this is the first privacy amplification tailored for a distributed learning framework, and it may have broader applicability beyond FL. Along the way, we extend privacy amplification by shuffling to incorporate $(\epsilon,\delta)$-DP local randomizers, and exponentially improve its guarantees. In practical regimes, this improvement allows for similar privacy and utility using data from an order of magnitude fewer users.
Adaptive Federated Optimization
Feb 29, 2020
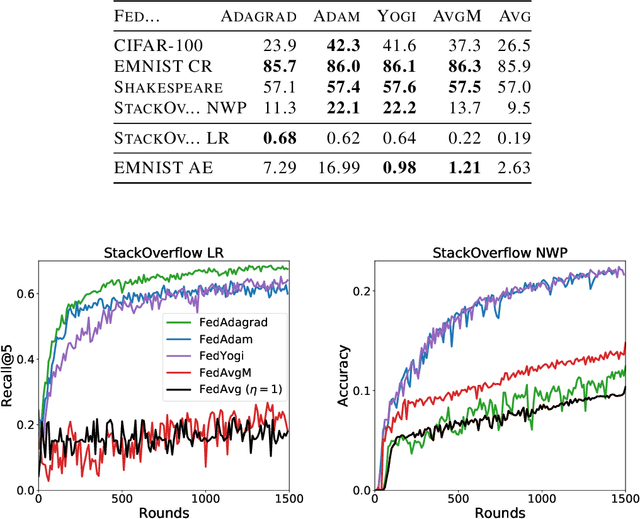
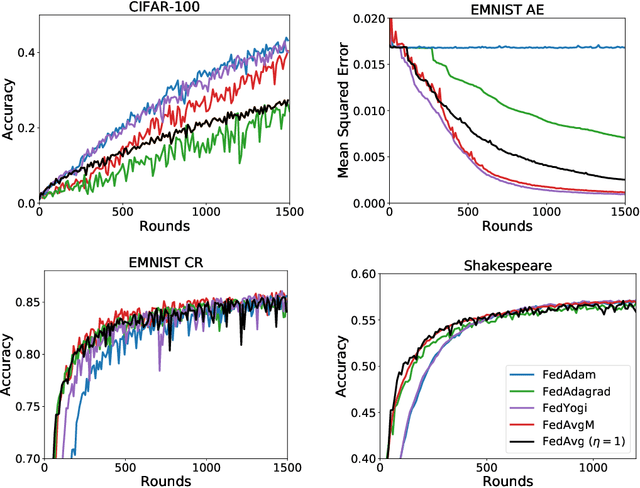
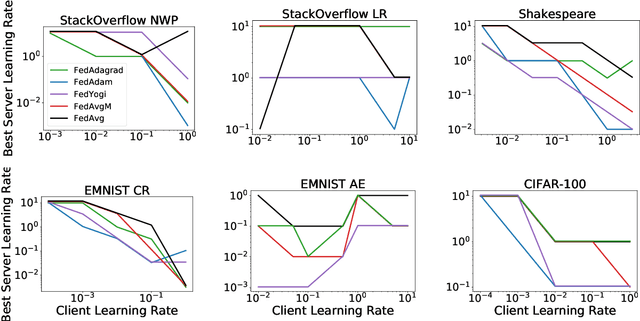
Federated learning is a distributed machine learning paradigm in which a large number of clients coordinate with a central server to learn a model without sharing their own training data. Due to the heterogeneity of the client datasets, standard federated optimization methods such as Federated Averaging (FedAvg) are often difficult to tune and exhibit unfavorable convergence behavior. In non-federated settings, adaptive optimization methods have had notable success in combating such issues. In this work, we propose federated versions of adaptive optimizers, including Adagrad, Adam, and Yogi, and analyze their convergence in the presence of heterogeneous data for general nonconvex settings. Our results highlight the interplay between client heterogeneity and communication efficiency. We also perform extensive experiments on these methods and show that the use of adaptive optimizers can significantly improve the performance of federated learning.