 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEach Prompt Matters: Scaling Reinforcement Learning Without Wasting Rollouts on Hundred-Billion-Scale MoE
Dec 08, 2025We present CompassMax-V3-Thinking, a hundred-billion-scale MoE reasoning model trained with a new RL framework built on one principle: each prompt must matter. Scaling RL to this size exposes critical inefficiencies-zero-variance prompts that waste rollouts, unstable importance sampling over long horizons, advantage inversion from standard reward models, and systemic bottlenecks in rollout processing. To overcome these challenges, we introduce several unified innovations: (1) Multi-Stage Zero-Variance Elimination, which filters out non-informative prompts and stabilizes group-based policy optimization (e.g. GRPO) by removing wasted rollouts; (2) ESPO, an entropy-adaptive optimization method that balances token-level and sequence-level importance sampling to maintain stable learning dynamics; (3) a Router Replay strategy that aligns training-time MoE router decisions with inference-time behavior to mitigate train-infer discrepancies, coupled with a reward model adjustment to prevent advantage inversion; (4) a high-throughput RL system with FP8-precision rollouts, overlapped reward computation, and length-aware scheduling to eliminate performance bottlenecks. Together, these contributions form a cohesive pipeline that makes RL on hundred-billion-scale MoE models stable and efficient. The resulting model delivers strong performance across both internal and public evaluations.
Neural Free-Viewpoint Performance Rendering under Complex Human-object Interactions
Aug 03, 2021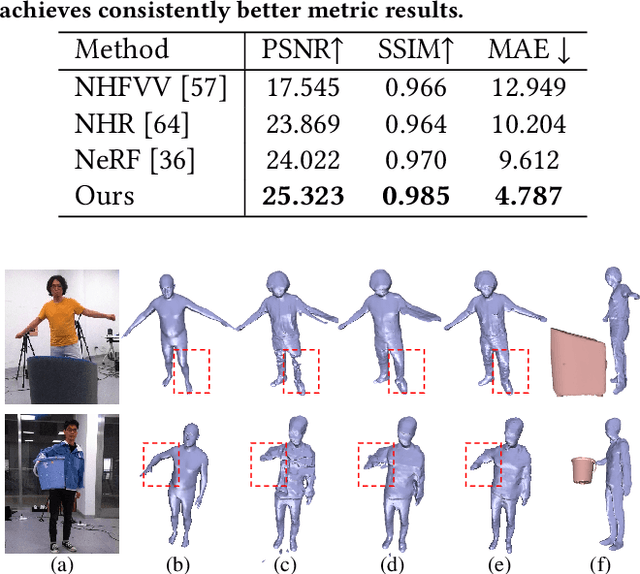
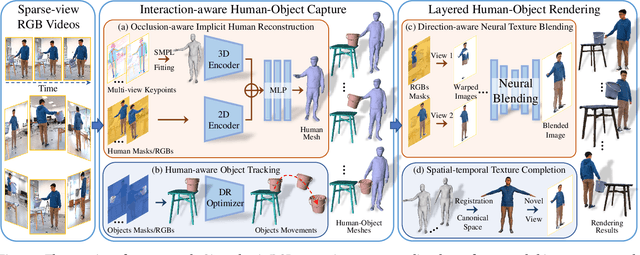
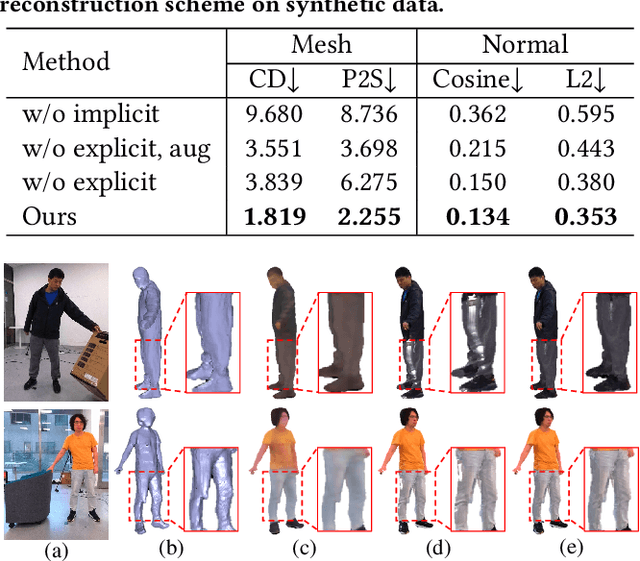

4D reconstruction of human-object interaction is critical for immersive VR/AR experience and human activity understanding. Recent advances still fail to recover fine geometry and texture results from sparse RGB inputs, especially under challenging human-object interactions scenarios. In this paper, we propose a neural human performance capture and rendering system to generate both high-quality geometry and photo-realistic texture of both human and objects under challenging interaction scenarios in arbitrary novel views, from only sparse RGB streams. To deal with complex occlusions raised by human-object interactions, we adopt a layer-wise scene decoupling strategy and perform volumetric reconstruction and neural rendering of the human and object. Specifically, for geometry reconstruction, we propose an interaction-aware human-object capture scheme that jointly considers the human reconstruction and object reconstruction with their correlations. Occlusion-aware human reconstruction and robust human-aware object tracking are proposed for consistent 4D human-object dynamic reconstruction. For neural texture rendering, we propose a layer-wise human-object rendering scheme, which combines direction-aware neural blending weight learning and spatial-temporal texture completion to provide high-resolution and photo-realistic texture results in the occluded scenarios. Extensive experiments demonstrate the effectiveness of our approach to achieve high-quality geometry and texture reconstruction in free viewpoints for challenging human-object interactions.