 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirectQE: Direct Pretraining for Machine Translation Quality Estimation
May 15, 2021
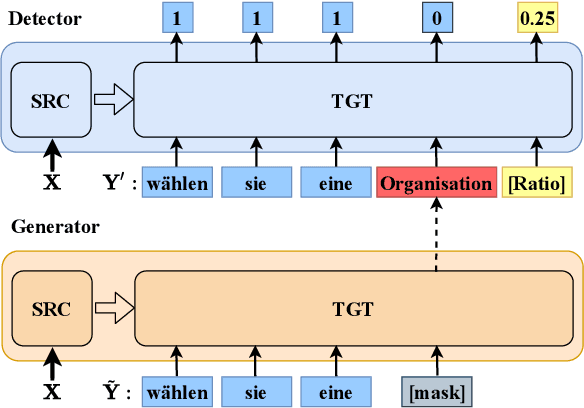
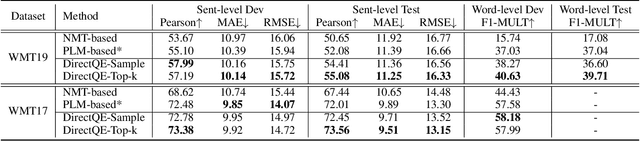
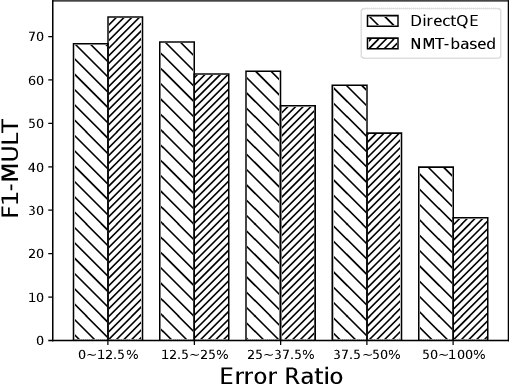
Machine Translation Quality Estimation (QE) is a task of predicting the quality of machine translations without relying on any reference. Recently, the predictor-estimator framework trains the predictor as a feature extractor, which leverages the extra parallel corpora without QE labels, achieving promising QE performance. However, we argue that there are gaps between the predictor and the estimator in both data quality and training objectives, which preclude QE models from benefiting from a large number of parallel corpora more directly. We propose a novel framework called DirectQE that provides a direct pretraining for QE tasks. In DirectQE, a generator is trained to produce pseudo data that is closer to the real QE data, and a detector is pretrained on these data with novel objectives that are akin to the QE task. Experiments on widely used benchmarks show that DirectQE outperforms existing methods, without using any pretraining models such as BERT. We also give extensive analyses showing how fixing the two gaps contributes to our improvements.
On the Branching Bias of Syntax Extracted from Pre-trained Language Models
Oct 06, 2020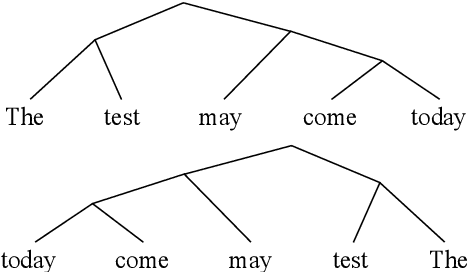
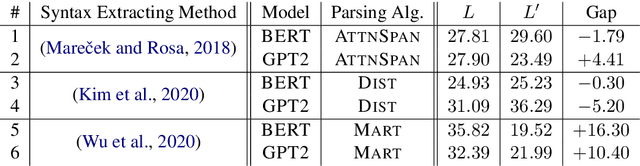
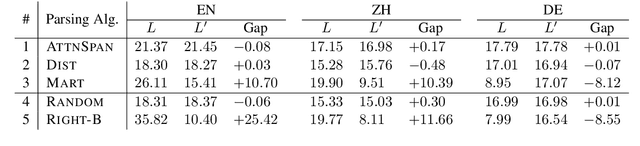

Many efforts have been devoted to extracting constituency trees from pre-trained language models, often proceeding in two stages: feature definition and parsing. However, this kind of methods may suffer from the branching bias issue, which will inflate the performances on languages with the same branch it biases to. In this work, we propose quantitatively measuring the branching bias by comparing the performance gap on a language and its reversed language, which is agnostic to both language models and extracting methods. Furthermore, we analyze the impacts of three factors on the branching bias, namely parsing algorithms, feature definitions, and language models. Experiments show that several existing works exhibit branching biases, and some implementations of these three factors can introduce the branching bias.
Evaluating Explanation Methods for Neural Machine Translation
May 04, 2020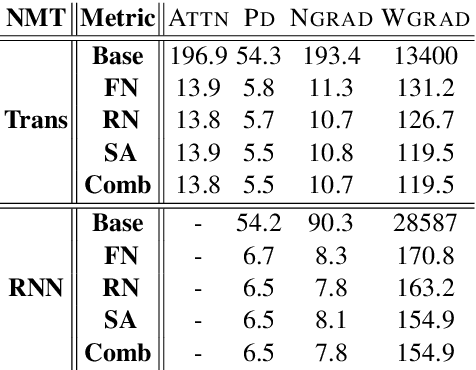
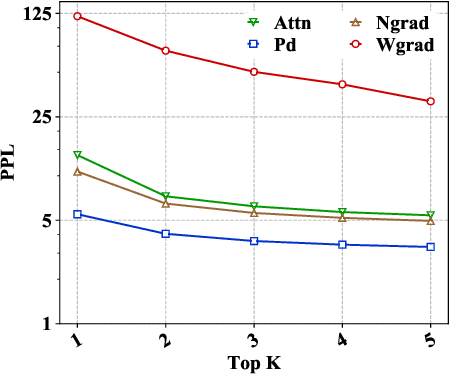

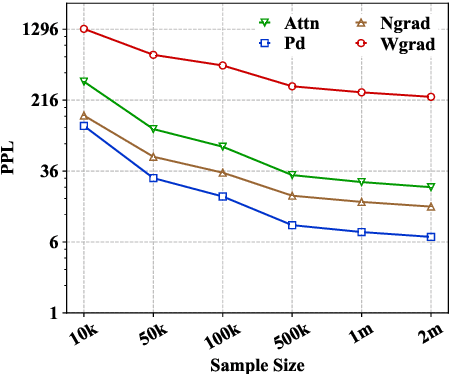
Recently many efforts have been devoted to interpreting the black-box NMT models, but little progress has been made on metrics to evaluate explanation methods. Word Alignment Error Rate can be used as such a metric that matches human understanding, however, it can not measure explanation methods on those target words that are not aligned to any source word. This paper thereby makes an initial attempt to evaluate explanation methods from an alternative viewpoint. To this end, it proposes a principled metric based on fidelity in regard to the predictive behavior of the NMT model. As the exact computation for this metric is intractable, we employ an efficient approach as its approximation. On six standard translation tasks, we quantitatively evaluate several explanation methods in terms of the proposed metric and we reveal some valuable findings for these explanation methods in our experiments.
Regularized Context Gates on Transformer for Machine Translation
Aug 29, 2019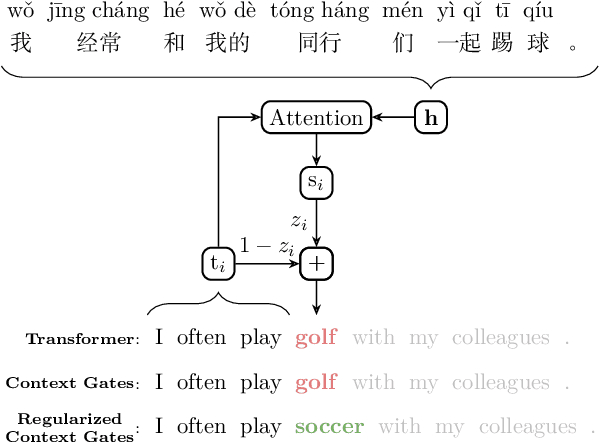
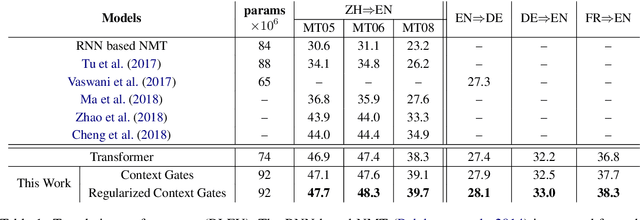
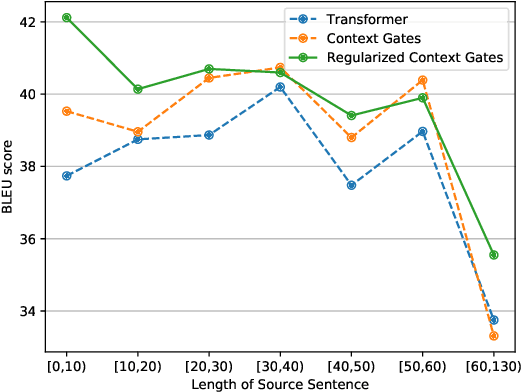
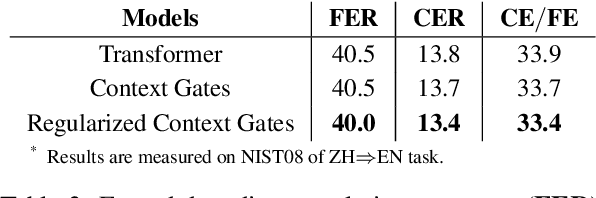
Context gates are effective to control the contributions from the source and target contexts in the recurrent neural network (RNN) based neural machine translation (NMT). However, it is challenging to extend them into the advanced Transformer architecture, which is more complicated than RNN. This paper first provides a method to identify source and target contexts and then introduce a gate mechanism to control the source and target contributions in Transformer. In addition, to further reduce the bias problem in the gate mechanism, this paper proposes a regularization method to guide the learning of the gates with supervision automatically generated using pointwise mutual information. Extensive experiments on 4 translation datasets demonstrate that the proposed model obtains an averaged gain of 1.0 BLEU score over strong Transformer baseline.
Neural Machine Translation with Noisy Lexical Constraints
Aug 13, 2019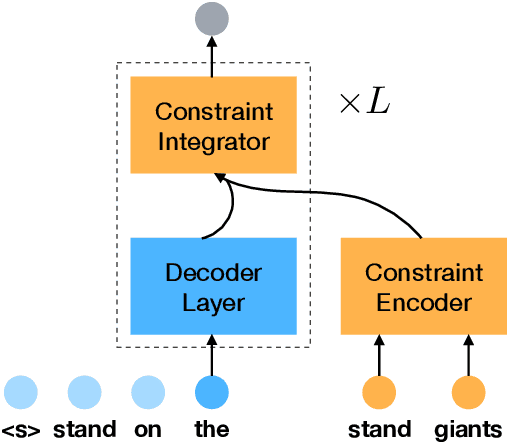
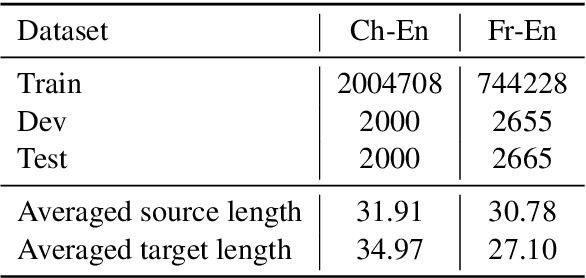
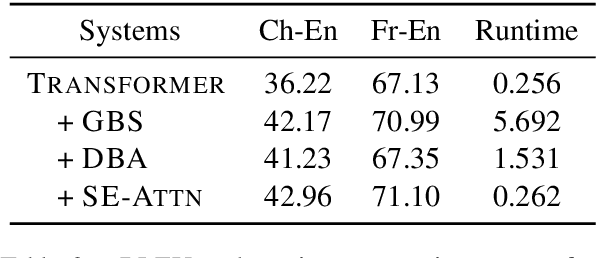
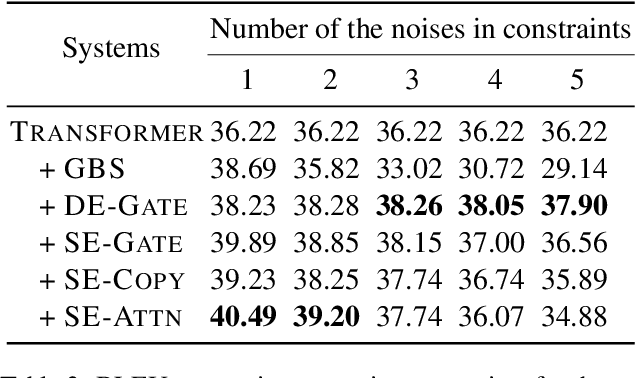
Lexically constrained decoding for machine translation has shown to be beneficial in previous studies. Unfortunately, constraints provided by users may contain mistakes in real-world situations. It is still an open question that how to manipulate these noisy constraints in such practical scenarios. We present a novel framework that treats constraints as external memories. In this soft manner, a mistaken constraint can be corrected. Experiments demonstrate that our approach can achieve substantial BLEU gains in handling noisy constraints. These results motivate us to apply the proposed approach on a new scenario where constraints are generated without the help of users. Experiments show that our approach can indeed improve the translation quality with the automatically generated constraints.
Language-Independent Representor for Neural Machine Translation
Nov 01, 2018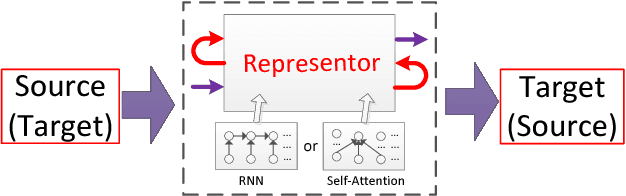
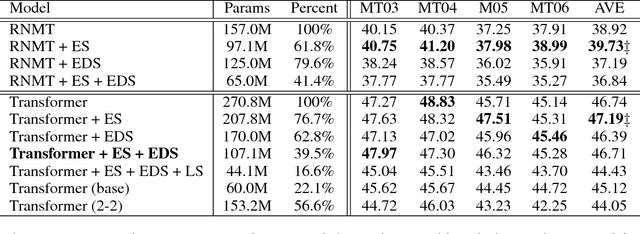
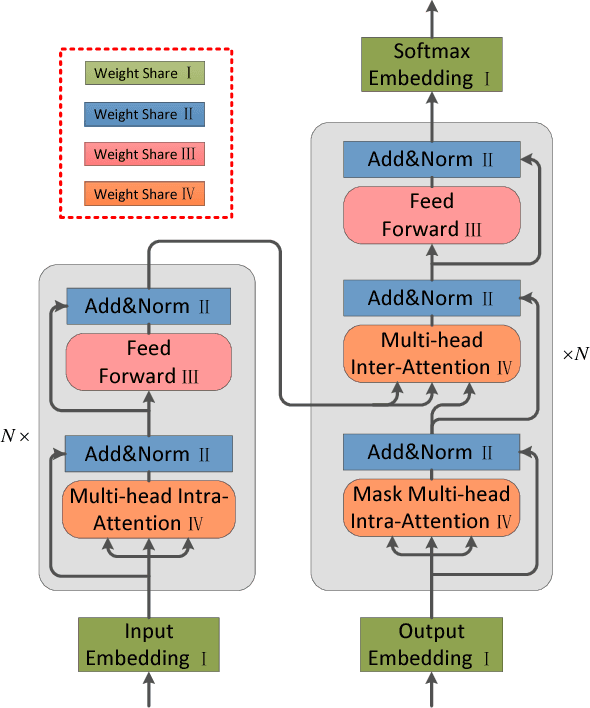

Current Neural Machine Translation (NMT) employs a language-specific encoder to represent the source sentence and adopts a language-specific decoder to generate target translation. This language-dependent design leads to large-scale network parameters and makes the duality of the parallel data underutilized. To address the problem, we propose in this paper a language-independent representor to replace the encoder and decoder by using weight sharing. This shared representor can not only reduce large portion of network parameters, but also facilitate us to fully explore the language duality by jointly training source-to-target, target-to-source, left-to-right and right-to-left translations within a multi-task learning framework. Experiments show that our proposed framework can obtain significant improvements over conventional NMT models on resource-rich and low-resource translation tasks with only a quarter of parameters.