 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenBA-V2: Reaching 77.3% High Compression Ratio with Fast Multi-Stage Pruning
May 09, 2024



Large Language Models (LLMs) have played an important role in many fields due to their powerful capabilities.However, their massive number of parameters leads to high deployment requirements and incurs significant inference costs, which impedes their practical applications. Training smaller models is an effective way to address this problem. Therefore, we introduce OpenBA-V2, a 3.4B model derived from multi-stage compression and continual pre-training from the original 15B OpenBA model. OpenBA-V2 utilizes more data, more flexible training objectives, and techniques such as layer pruning, neural pruning, and vocabulary pruning to achieve a compression rate of 77.3\% with minimal performance loss. OpenBA-V2 demonstrates competitive performance compared to other open-source models of similar size, achieving results close to or on par with the 15B OpenBA model in downstream tasks such as common sense reasoning and Named Entity Recognition (NER). OpenBA-V2 illustrates that LLMs can be compressed into smaller ones with minimal performance loss by employing advanced training objectives and data strategies, which may help deploy LLMs in resource-limited scenarios.
Pipelined Biomedical Event Extraction Rivaling Joint Learning
Mar 19, 2024



Biomedical event extraction is an information extraction task to obtain events from biomedical text, whose targets include the type, the trigger, and the respective arguments involved in an event. Traditional biomedical event extraction usually adopts a pipelined approach, which contains trigger identification, argument role recognition, and finally event construction either using specific rules or by machine learning. In this paper, we propose an n-ary relation extraction method based on the BERT pre-training model to construct Binding events, in order to capture the semantic information about an event's context and its participants. The experimental results show that our method achieves promising results on the GE11 and GE13 corpora of the BioNLP shared task with F1 scores of 63.14% and 59.40%, respectively. It demonstrates that by significantly improving theperformance of Binding events, the overall performance of the pipelined event extraction approach or even exceeds those of current joint learning methods.
ChatASU: Evoking LLM's Reflexion to Truly Understand Aspect Sentiment in Dialogues
Mar 12, 2024



Aspect Sentiment Understanding (ASU) in interactive scenarios (e.g., Question-Answering and Dialogue) has attracted ever-more interest in recent years and achieved important progresses. However, existing studies on interactive ASU largely ignore the coreference issue for opinion targets (i.e., aspects), while this phenomenon is ubiquitous in interactive scenarios especially dialogues, limiting the ASU performance. Recently, large language models (LLMs) shows the powerful ability to integrate various NLP tasks with the chat paradigm. In this way, this paper proposes a new Chat-based Aspect Sentiment Understanding (ChatASU) task, aiming to explore LLMs' ability in understanding aspect sentiments in dialogue scenarios. Particularly, this ChatASU task introduces a sub-task, i.e., Aspect Chain Reasoning (ACR) task, to address the aspect coreference issue. On this basis, we propose a Trusted Self-reflexion Approach (TSA) with ChatGLM as backbone to ChatASU. Specifically, this TSA treats the ACR task as an auxiliary task to boost the performance of the primary ASU task, and further integrates trusted learning into reflexion mechanisms to alleviate the LLMs-intrinsic factual hallucination problem in TSA. Furthermore, a high-quality ChatASU dataset is annotated to evaluate TSA, and extensive experiments show that our proposed TSA can significantly outperform several state-of-the-art baselines, justifying the effectiveness of TSA to ChatASU and the importance of considering the coreference and hallucination issues in ChatASU.
TopicDiff: A Topic-enriched Diffusion Approach for Multimodal Conversational Emotion Detection
Mar 11, 2024Multimodal Conversational Emotion (MCE) detection, generally spanning across the acoustic, vision and language modalities, has attracted increasing interest in the multimedia community. Previous studies predominantly focus on learning contextual information in conversations with only a few considering the topic information in single language modality, while always neglecting the acoustic and vision topic information. On this basis, we propose a model-agnostic Topic-enriched Diffusion (TopicDiff) approach for capturing multimodal topic information in MCE tasks. Particularly, we integrate the diffusion model into neural topic model to alleviate the diversity deficiency problem of neural topic model in capturing topic information. Detailed evaluations demonstrate the significant improvements of TopicDiff over the state-of-the-art MCE baselines, justifying the importance of multimodal topic information to MCE and the effectiveness of TopicDiff in capturing such information. Furthermore, we observe an interesting finding that the topic information in acoustic and vision is more discriminative and robust compared to the language.
How to Understand "Support"? An Implicit-enhanced Causal Inference Approach for Weakly-supervised Phrase Grounding
Mar 04, 2024



Weakly-supervised Phrase Grounding (WPG) is an emerging task of inferring the fine-grained phrase-region matching, while merely leveraging the coarse-grained sentence-image pairs for training. However, existing studies on WPG largely ignore the implicit phrase-region matching relations, which are crucial for evaluating the capability of models in understanding the deep multimodal semantics. To this end, this paper proposes an Implicit-Enhanced Causal Inference (IECI) approach to address the challenges of modeling the implicit relations and highlighting them beyond the explicit. Specifically, this approach leverages both the intervention and counterfactual techniques to tackle the above two challenges respectively. Furthermore, a high-quality implicit-enhanced dataset is annotated to evaluate IECI and detailed evaluations show the great advantages of IECI over the state-of-the-art baselines. Particularly, we observe an interesting finding that IECI outperforms the advanced multimodal LLMs by a large margin on this implicit-enhanced dataset, which may facilitate more research to evaluate the multimodal LLMs in this direction.
Comment-aided Video-Language Alignment via Contrastive Pre-training for Short-form Video Humor Detection
Feb 14, 2024



The growing importance of multi-modal humor detection within affective computing correlates with the expanding influence of short-form video sharing on social media platforms. In this paper, we propose a novel two-branch hierarchical model for short-form video humor detection (SVHD), named Comment-aided Video-Language Alignment (CVLA) via data-augmented multi-modal contrastive pre-training. Notably, our CVLA not only operates on raw signals across various modal channels but also yields an appropriate multi-modal representation by aligning the video and language components within a consistent semantic space. The experimental results on two humor detection datasets, including DY11k and UR-FUNNY, demonstrate that CVLA dramatically outperforms state-of-the-art and several competitive baseline approaches. Our dataset, code and model release at https://github.com/yliu-cs/CVLA.
OpenBA: An Open-sourced 15B Bilingual Asymmetric seq2seq Model Pre-trained from Scratch
Oct 01, 2023



Large language models (LLMs) with billions of parameters have demonstrated outstanding performance on various natural language processing tasks. This report presents OpenBA, an open-sourced 15B bilingual asymmetric seq2seq model, to contribute an LLM variant to the Chinese-oriented open-source model community. We enhance OpenBA with effective and efficient techniques as well as adopt a three-stage training strategy to train the model from scratch. Our solution can also achieve very competitive performance with only 380B tokens, which is better than LLaMA-70B on the BELEBELE benchmark, BLOOM-176B on the MMLU benchmark, GLM-130B on the C-Eval (hard) benchmark. This report provides the main details to pre-train an analogous model, including pre-training data processing, Bilingual Flan data collection, the empirical observations that inspire our model architecture design, training objectives of different stages, and other enhancement techniques. Additionally, we also provide the fine-tuning details of OpenBA on four downstream tasks. We have refactored our code to follow the design principles of the Huggingface Transformers Library, making it more convenient for developers to use, and released checkpoints of different training stages at https://huggingface.co/openBA. More details of our project are available at https://github.com/OpenNLG/openBA.git.
Opinion Tree Parsing for Aspect-based Sentiment Analysis
Jun 15, 2023Extracting sentiment elements using pre-trained generative models has recently led to large improvements in aspect-based sentiment analysis benchmarks. However, these models always need large-scale computing resources, and they also ignore explicit modeling of structure between sentiment elements. To address these challenges, we propose an opinion tree parsing model, aiming to parse all the sentiment elements from an opinion tree, which is much faster, and can explicitly reveal a more comprehensive and complete aspect-level sentiment structure. In particular, we first introduce a novel context-free opinion grammar to normalize the opinion tree structure. We then employ a neural chart-based opinion tree parser to fully explore the correlations among sentiment elements and parse them into an opinion tree structure. Extensive experiments show the superiority of our proposed model and the capacity of the opinion tree parser with the proposed context-free opinion grammar. More importantly, the results also prove that our model is much faster than previous models.
Discourse Cohesion Evaluation for Document-Level Neural Machine Translation
Aug 19, 2022
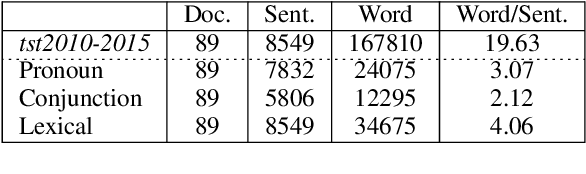
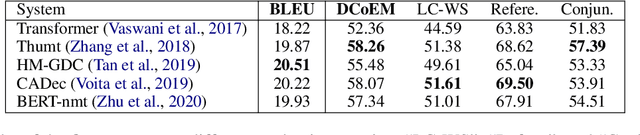
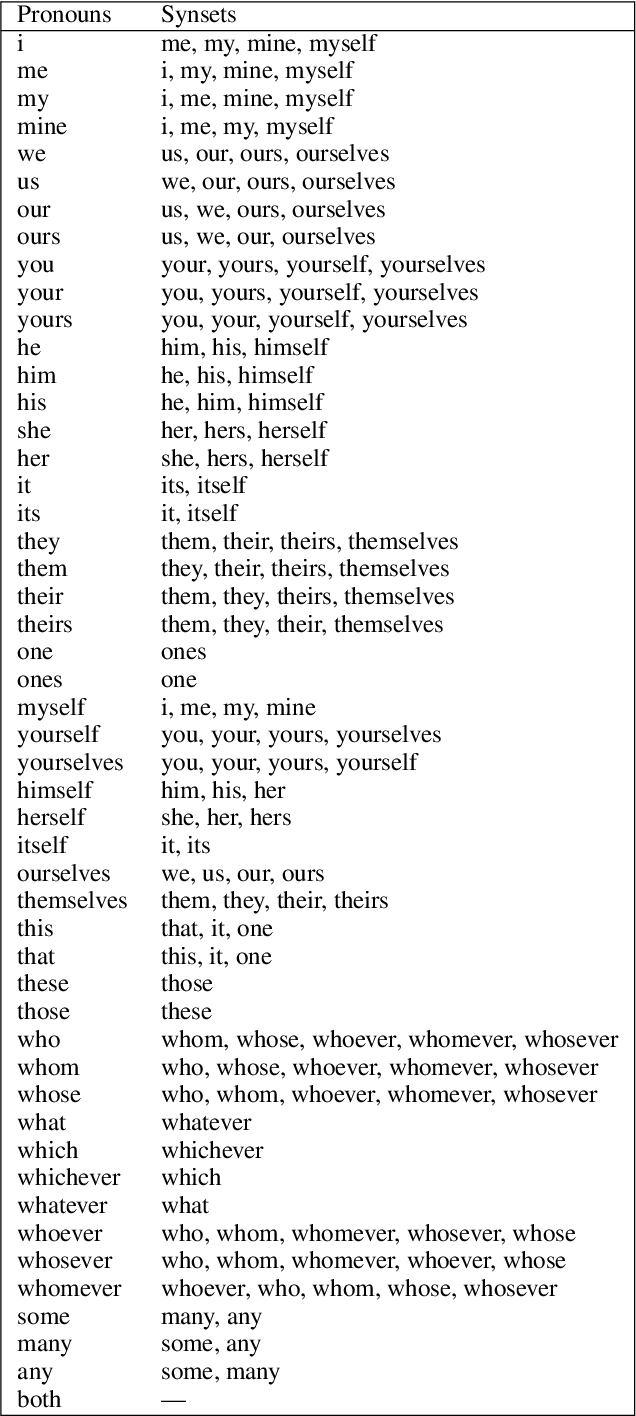
It is well known that translations generated by an excellent document-level neural machine translation (NMT) model are consistent and coherent. However, existing sentence-level evaluation metrics like BLEU can hardly reflect the model's performance at the document level. To tackle this issue, we propose a Discourse Cohesion Evaluation Method (DCoEM) in this paper and contribute a new test suite that considers four cohesive manners (reference, conjunction, substitution, and lexical cohesion) to measure the cohesiveness of document translations. The evaluation results on recent document-level NMT systems show that our method is practical and essential in estimating translations at the document level.
Joint Learning-based Causal Relation Extraction from Biomedical Literature
Aug 02, 2022
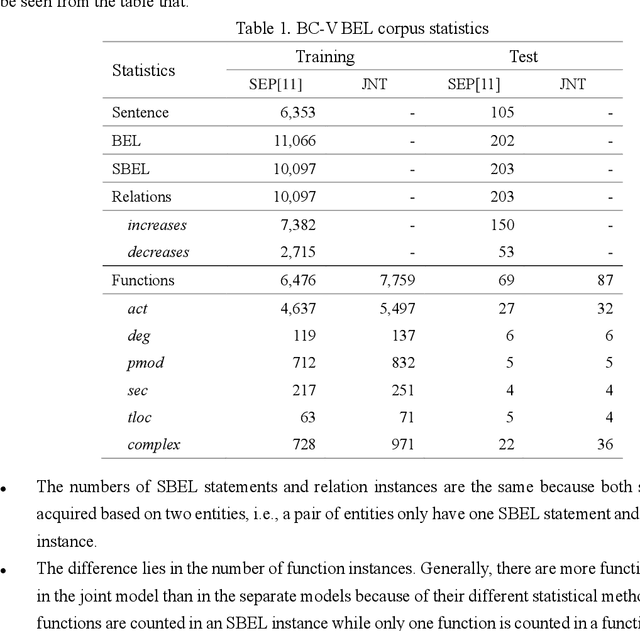
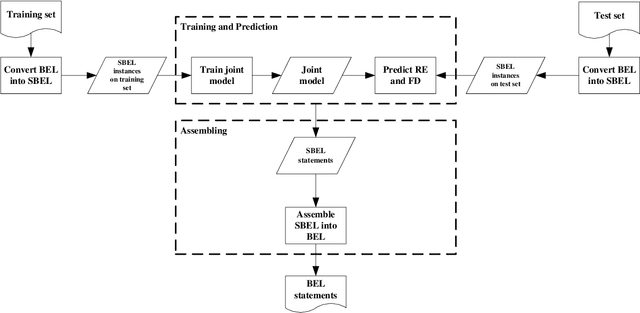
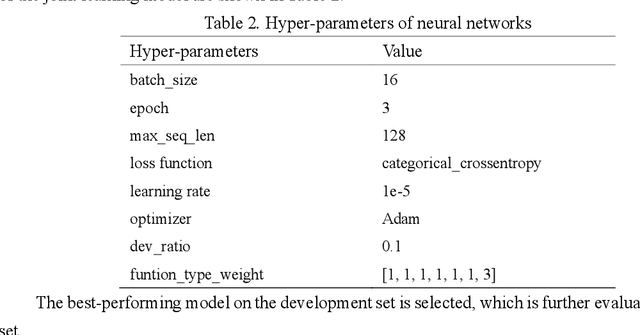
Causal relation extraction of biomedical entities is one of the most complex tasks in biomedical text mining, which involves two kinds of information: entity relations and entity functions. One feasible approach is to take relation extraction and function detection as two independent sub-tasks. However, this separate learning method ignores the intrinsic correlation between them and leads to unsatisfactory performance. In this paper, we propose a joint learning model, which combines entity relation extraction and entity function detection to exploit their commonality and capture their inter-relationship, so as to improve the performance of biomedical causal relation extraction. Meanwhile, during the model training stage, different function types in the loss function are assigned different weights. Specifically, the penalty coefficient for negative function instances increases to effectively improve the precision of function detection. Experimental results on the BioCreative-V Track 4 corpus show that our joint learning model outperforms the separate models in BEL statement extraction, achieving the F1 scores of 58.4% and 37.3% on the test set in Stage 2 and Stage 1 evaluations, respectively. This demonstrates that our joint learning system reaches the state-of-the-art performance in Stage 2 compared with other systems.