 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Accuracies, Worse Reasoning: A Step-Level Audit of Medical Chain-of-Thought Distillation
May 27, 2026Chain-of-thought (CoT) distillation trains a smaller model to imitate a teacher's reasoning trace, but it is typically evaluated by final-answer metrics including accuracy. We ask whether gains in answer quality are accompanied by improvements in the trace. In medical QA, where short answer options can leave a richer clinical justification under-specified, a Qwen3-8B student distilled from a DeepSeek-V3-family teacher improves on MedQA-USMLE answer metrics (SC@64 74.7% to 84.4%; expected calibration error (ECE) 0.096 to 0.034). Yet under a Kimi-K2.6 style-blind LLM-judge audit, its error rate over non-abstained steps rises from 30.6% to 50.3%. In this primary medical setting, answer quality and trace factuality move in opposite directions. This before--after pattern persists across evaluators, teacher strengths, student scales and families, medical benchmarks, and style, segmentation, and answer-correctness controls. A 150-step blinded audit by a clinical expert reproduces the same ordering. Boundary checks narrow the scope of the claim: the risk appears when a compact answer under-constrains the rationale and a capable student can imitate expert-like form without reliably grounding each local claim. Standard answer metrics and aggregate hedging rates do not reveal the shift. When such traces are released or reused, answer-level metrics alone are insufficient.
A Regime Theory of Controller Class Selection for LLM Action Decisions
May 07, 2026Deployed language and vision-language models must decide, on each input, whether to answer directly, retrieve evidence, defer to a stronger model, or abstain. Contrary to the common monotonicity intuition, greater per-input expressivity is not uniformly beneficial in finite samples: under identical strict cross-validation, different benchmarks prefer different controller classes. This reflects a finite-sample limitation of instance-level uncertainty signals, which can be exhausted at a distribution-dependent scale. We organize controllers into a nested lattice of four classes: fixed actions, partition routers, instance-level controllers, and prior-gated controllers, ordered by complexity. We prove a regime theory that turns three data-estimable bottlenecks into a class choice: how much improvement is possible beyond the best fixed action, whether there are enough samples for instance-level controllers to make reliable decisions, and how much improvement a coarse partition router can recover when instance-level signal is unreliable. The resulting Bernstein-tight threshold has a matching information-theoretic lower bound, and strict nested cross-validation provably selects a near-best class. Across SMS-Spam, HallusionBench, A-OKVQA, and FOLIO, the predicted class matches the empirical winner; the prior-gated controller wins on TextVQA when OCR tokens supply a label-free prediction-time prior. Code is available at https://github.com/Anonymous-Awesome-Submissions/Regime-Theory.
Focus on the Whole Character: Discriminative Character Modeling for Scene Text Recognition
Jul 08, 2024Recently, scene text recognition (STR) models have shown significant performance improvements. However, existing models still encounter difficulties in recognizing challenging texts that involve factors such as severely distorted and perspective characters. These challenging texts mainly cause two problems: (1) Large Intra-Class Variance. (2) Small Inter-Class Variance. An extremely distorted character may prominently differ visually from other characters within the same category, while the variance between characters from different classes is relatively small. To address the above issues, we propose a novel method that enriches the character features to enhance the discriminability of characters. Firstly, we propose the Character-Aware Constraint Encoder (CACE) with multiple blocks stacked. CACE introduces a decay matrix in each block to explicitly guide the attention region for each token. By continuously employing the decay matrix, CACE enables tokens to perceive morphological information at the character level. Secondly, an Intra-Inter Consistency Loss (I^2CL) is introduced to consider intra-class compactness and inter-class separability at feature space. I^2CL improves the discriminative capability of features by learning a long-term memory unit for each character category. Trained with synthetic data, our model achieves state-of-the-art performance on common benchmarks (94.1% accuracy) and Union14M-Benchmark (61.6% accuracy). Code is available at https://github.com/bang123-box/CFE.
Pre-trained Token-replaced Detection Model as Few-shot Learner
Mar 07, 2022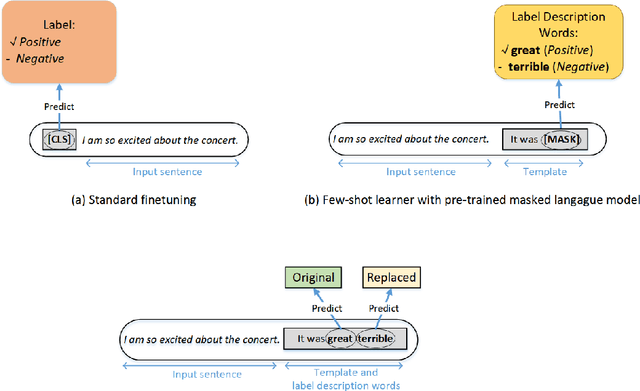
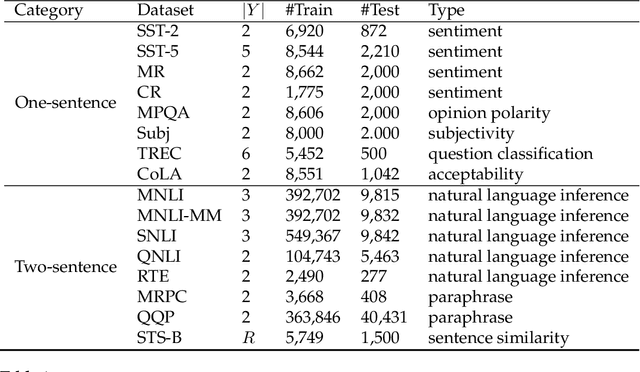
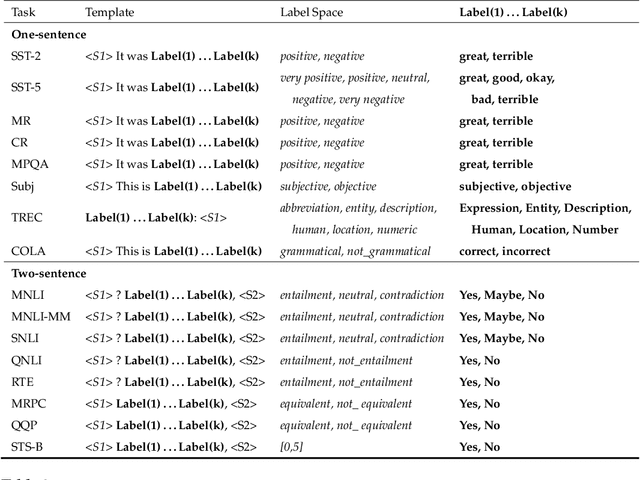
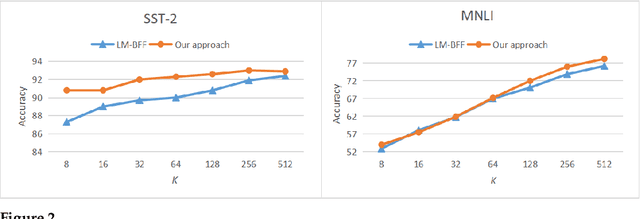
Pre-trained masked language models have demonstrated remarkable ability as few-shot learners. In this paper, as an alternative, we propose a novel approach to few-shot learning with pre-trained token-replaced detection models like ELECTRA. In this approach, we reformulate a classification or a regression task as a token-replaced detection problem. Specifically, we first define a template and label description words for each task and put them into the input to form a natural language prompt. Then, we employ the pre-trained token-replaced detection model to predict which label description word is the most original (i.e., least replaced) among all label description words in the prompt. A systematic evaluation on 16 datasets demonstrates that our approach outperforms few-shot learners with pre-trained masked language models in both one-sentence and two-sentence learning tasks.