 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-Temporal Transformer Networks for Traffic Flow Forecasting
Jan 09, 2020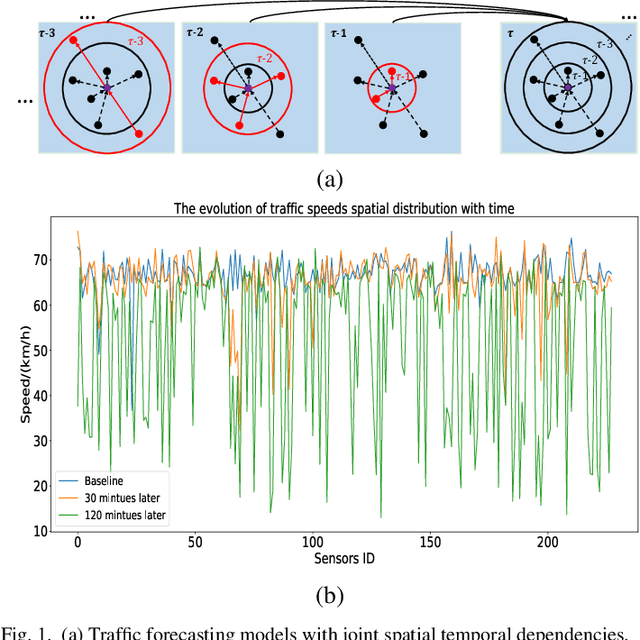
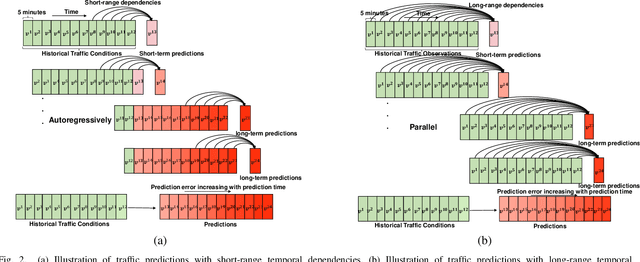
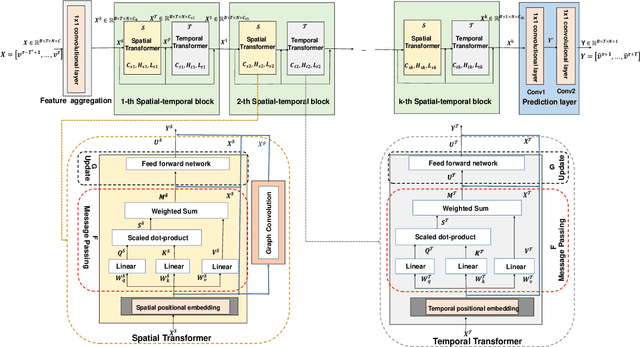
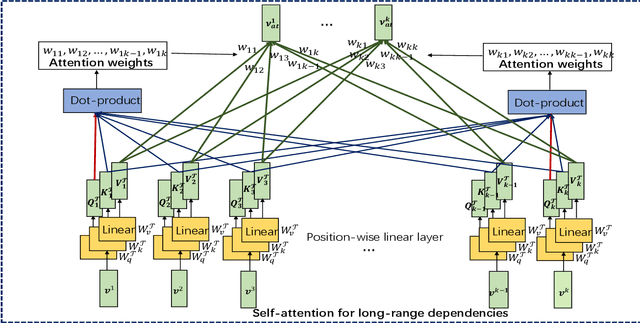
Traffic forecasting has emerged as a core component of intelligent transportation systems. However, timely accurate traffic forecasting, especially long-term forecasting, still remains an open challenge due to the highly nonlinear and dynamic spatial-temporal dependencies of traffic flows. In this paper, we propose a novel paradigm of Spatial-Temporal Transformer Networks (STTNs) that leverages dynamical directed spatial dependencies and long-range temporal dependencies to improve the accuracy of long-term traffic forecasting. Specifically, we present a new variant of graph neural networks, named spatial transformer, by dynamically modeling directed spatial dependencies with self-attention mechanism to capture realtime traffic conditions as well as the directionality of traffic flows. Furthermore, different spatial dependency patterns can be jointly modeled with multi-heads attention mechanism to consider diverse relationships related to different factors (e.g. similarity, connectivity and covariance). On the other hand, the temporal transformer is utilized to model long-range bidirectional temporal dependencies across multiple time steps. Finally, they are composed as a block to jointly model the spatial-temporal dependencies for accurate traffic prediction. Compared to existing works, the proposed model enables fast and scalable training over a long range spatial-temporal dependencies. Experiment results demonstrate that the proposed model achieves competitive results compared with the state-of-the-arts, especially forecasting long-term traffic flows on real-world PeMS-Bay and PeMSD7(M) datasets.
EnAET: Self-Trained Ensemble AutoEncoding Transformations for Semi-Supervised Learning
Nov 21, 2019


Deep neural networks have been successfully applied to many real-world applications. However, these successes rely heavily on large amounts of labeled data, which is expensive to obtain. Recently, Auto-Encoding Transformation (AET) and MixMatch have been proposed and achieved state-of-the-art results for unsupervised and semi-supervised learning, respectively. In this study, we train an Ensemble of Auto-Encoding Transformations (EnAET) to learn from both labeled and unlabeled data based on the embedded representations by decoding both spatial and non-spatial transformations. This distinguishes EnAET from conventional semi-supervised methods that focus on improving prediction consistency and confidence by different models on both unlabeled and labeled examples. In contrast, we propose to explore the role of self-supervised representations in semi-supervised learning under a rich family of transformations. Experiment results on CIFAR-10, CIFAR-100, SVHN and STL10 demonstrate that the proposed EnAET outperforms the state-of-the-art semi-supervised methods by significant margins. In particular, we apply the proposed method to extremely challenging scenarios with only 10 images per class, and show that EnAET can achieve an error rate of 9.35% on CIFAR-10 and 16.92% on SVHN. In addition, EnAET achieves the best result when compared with fully supervised learning using all labeled data with the same network architecture. The performance on CIFAR-10, CIFAR-100 and SVHN with a smaller network is even more competitive than the state-of-the-art of supervised learning methods based on a larger network. We also set a new performance record with an error rate of 1.99% on CIFAR-10 and 4.52% on STL10. The code and experiment records are released at https://github.com/maple-research-lab/EnAET.
GraphTER: Unsupervised Learning of Graph Transformation Equivariant Representations via Auto-Encoding Node-wise Transformations
Nov 19, 2019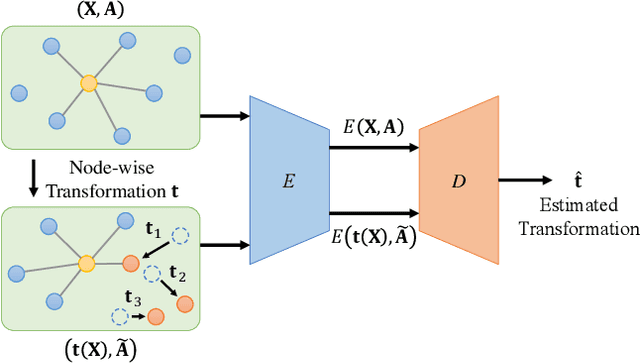

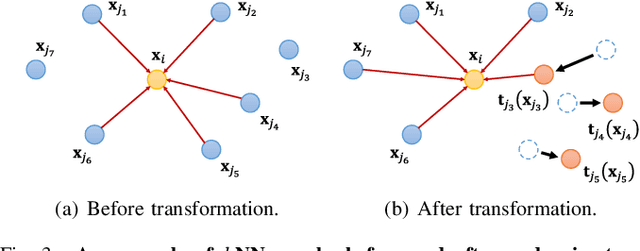
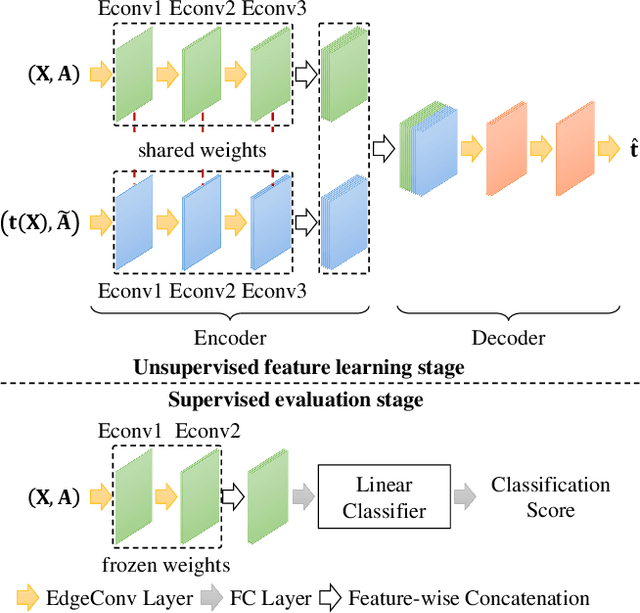
Recent advances in Graph Convolutional Neural Networks (GCNNs) have shown their efficiency for non-Euclidean data on graphs, which often require a large amount of labeled data with high cost. It it thus critical to learn graph feature representations in an unsupervised manner in practice. To this end, we propose a novel unsupervised learning of Graph Transformation Equivariant Representations (GraphTER), aiming to capture intrinsic patterns of graph structure under both global and local transformations. Specifically, we allow to sample different groups of nodes from a graph and then transform them node-wise isotropically or anisotropically. Then, we self-train a representation encoder to capture the graph structures by reconstructing these node-wise transformations from the feature representations of the original and transformed graphs. In experiments, we apply the learned GraphTER to graphs of 3D point cloud data, and results on point cloud segmentation/classification show that GraphTER significantly outperforms state-of-the-art unsupervised approaches and pushes greatly closer towards the upper bound set by the fully supervised counterparts.
AETv2: AutoEncoding Transformations for Self-Supervised Representation Learning by Minimizing Geodesic Distances in Lie Groups
Nov 16, 2019
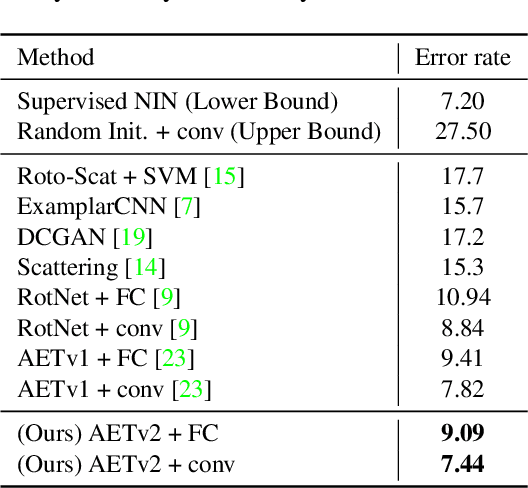
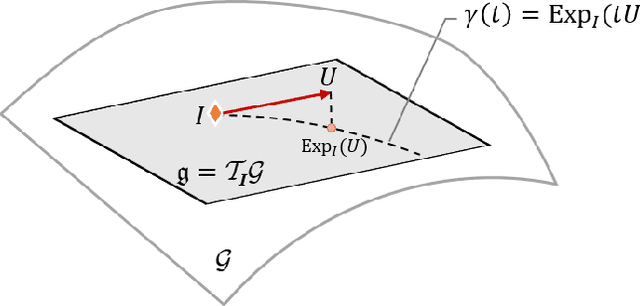

Self-supervised learning by predicting transformations has demonstrated outstanding performances in both unsupervised and (semi-)supervised tasks. Among the state-of-the-art methods is the AutoEncoding Transformations (AET) by decoding transformations from the learned representations of original and transformed images. Both deterministic and probabilistic AETs rely on the Euclidean distance to measure the deviation of estimated transformations from their groundtruth counterparts. However, this assumption is questionable as a group of transformations often reside on a curved manifold rather staying in a flat Euclidean space. For this reason, we should use the geodesic to characterize how an image transform along the manifold of a transformation group, and adopt its length to measure the deviation between transformations. Particularly, we present to autoencode a Lie group of homography transformations PG(2) to learn image representations. For this, we make an estimate of the intractable Riemannian logarithm by projecting PG(2) to a subgroup of rotation transformations SO(3) that allows the closed-form expression of geodesic distances. Experiments demonstrate the proposed AETv2 model outperforms the previous version as well as the other state-of-the-art self-supervised models in multiple tasks.
Progressive Unsupervised Person Re-identification by Tracklet Association with Spatio-Temporal Regularization
Oct 25, 2019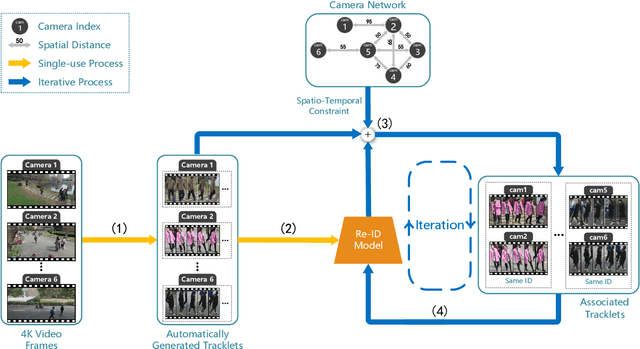


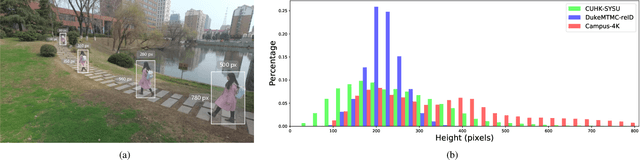
Existing methods for person re-identification (Re-ID) are mostly based on supervised learning which requires numerous manually labeled samples across all camera views for training. Such a paradigm suffers the scalability issue since in real-world Re-ID application, it is difficult to exhaustively label abundant identities over multiple disjoint camera views. To this end, we propose a progressive deep learning method for unsupervised person Re-ID in the wild by Tracklet Association with Spatio-Temporal Regularization (TASTR). In our approach, we first collect tracklet data within each camera by automatic person detection and tracking. Then, an initial Re-ID model is trained based on within-camera triplet construction for person representation learning. After that, based on the person visual feature and spatio-temporal constraint, we associate cross-camera tracklets to generate cross-camera triplets and update the Re-ID model. Lastly, with the refined Re-ID model, better visual feature of person can be extracted, which further promote the association of cross-camera tracklets. The last two steps are iterated multiple times to progressively upgrade the Re-ID model.
Spatiotemporal Co-attention Recurrent Neural Networks for Human-Skeleton Motion Prediction
Oct 01, 2019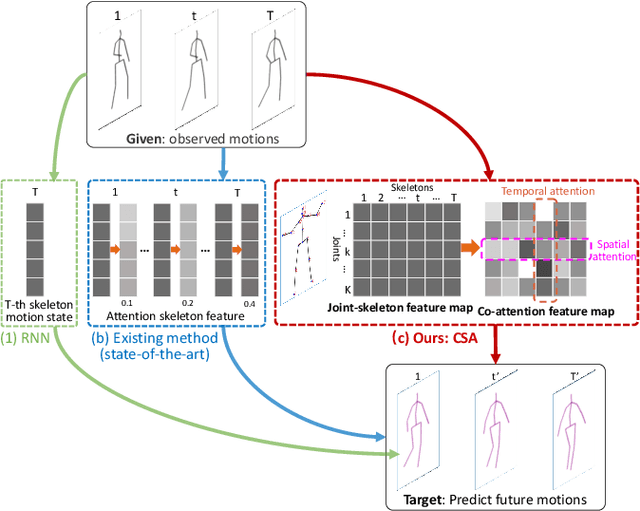

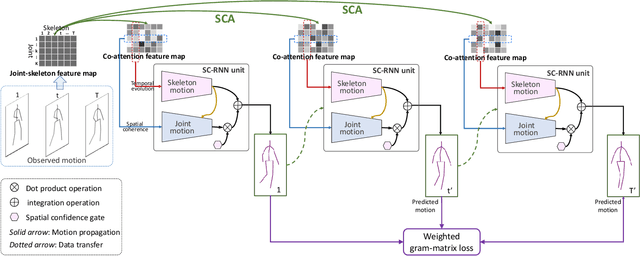
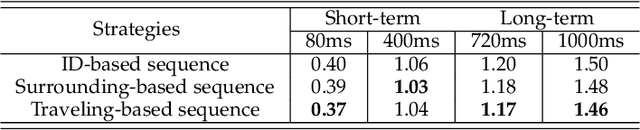
Human motion prediction aims to generate future motions based on the observed human motions. Witnessing the success of Recurrent Neural Networks (RNN) in modeling the sequential data, recent works utilize RNN to model human-skeleton motion on the observed motion sequence and predict future human motions. However, these methods did not consider the existence of the spatial coherence among joints and the temporal evolution among skeletons, which reflects the crucial characteristics of human motion in spatiotemporal space. To this end, we propose a novel Skeleton-joint Co-attention Recurrent Neural Networks (SC-RNN) to capture the spatial coherence among joints, and the temporal evolution among skeletons simultaneously on a skeleton-joint co-attention feature map in spatiotemporal space. First, a skeleton-joint feature map is constructed as the representation of the observed motion sequence. Second, we design a new Skeleton-joint Co-Attention (SCA) mechanism to dynamically learn a skeleton-joint co-attention feature map of this skeleton-joint feature map, which can refine the useful observed motion information to predict one future motion. Third, a variant of GRU embedded with SCA collaboratively models the human-skeleton motion and human-joint motion in spatiotemporal space by regarding the skeleton-joint co-attention feature map as the motion context. Experimental results on human motion prediction demonstrate the proposed method outperforms the related methods.
PC-DARTS: Partial Channel Connections for Memory-Efficient Differentiable Architecture Search
Jul 12, 2019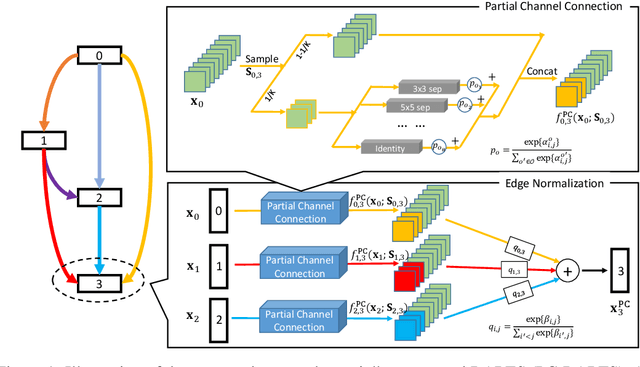
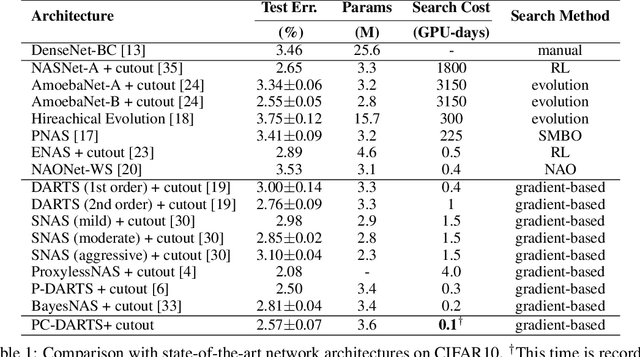
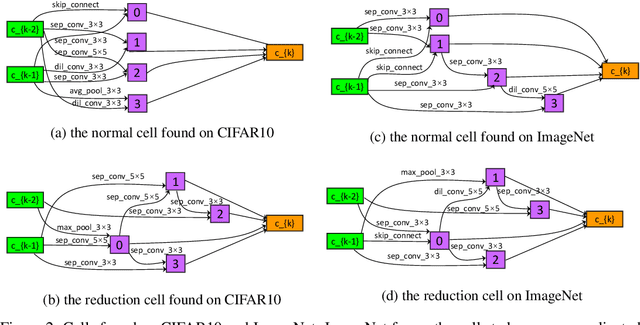
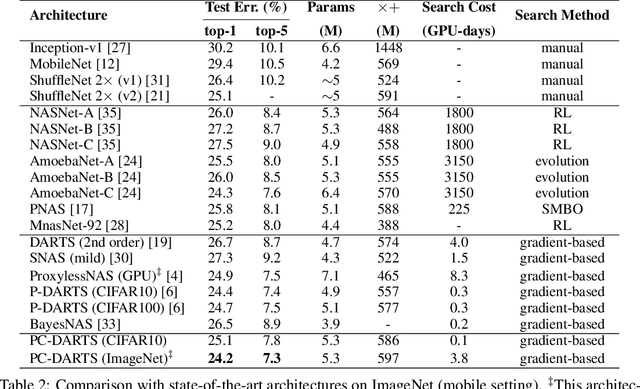
Differentiable architecture search (DARTS) provided a fast solution in finding effective network architectures, but suffered from large memory and computing overheads in jointly training a super-net and search for an optimal architecture. In this paper, we present a novel approach, namely Partially-Connected DARTS, by sampling a small part of super-net to reduce the redundancy in network space, thereby performing a more efficient search without comprising the performance. In particular, we perform operation search in a subset of channels and leave the held out part unchanged. This strategy may suffer from an undesired inconsistency on selecting the edges of super-net caused by the sampling of different channels. We solve it by introducing edge normalization, which adds a new set of edge-level hyper-parameters during search to reduce uncertainty in search. Thanks to the reduced memory cost, PC-DARTS can be trained with a larger batch size and, consequently, enjoys both faster speed and higher training stability. Experimental results demonstrate the effectiveness of the proposed method. Specifically, we achieve an error rate of 2:57% on CIFAR10 within merely 0:1 GPU-days for architecture search, and a state-of-the-art top-1 error rate of 24:2% on ImageNet (under the mobile setting) within 3.8 GPU-days for search. We have made our code available: https://github.com/yuhuixu1993/PC-DARTS.
Learning Generalized Transformation Equivariant Representations via Autoencoding Transformations
Jun 19, 2019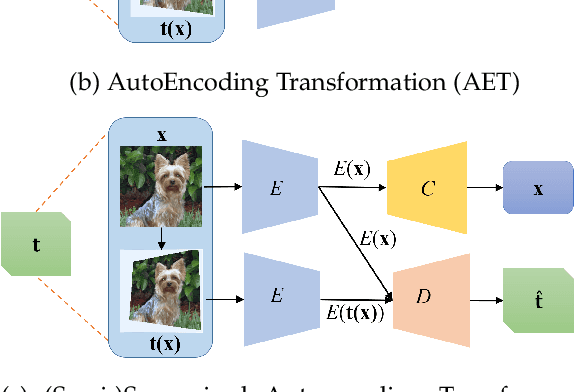
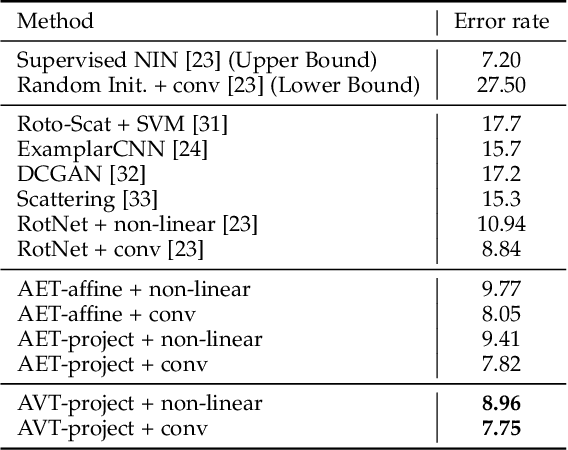
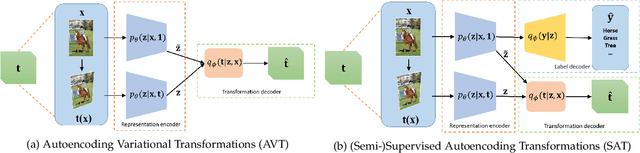
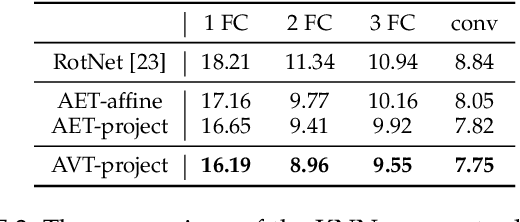
Learning Transformation Equivariant Representations (TERs) seeks to capture the intrinsic visual structures of images through the representations that equivary to the applied transformations. It assumes that a transformation should be decoded from expressive representations of images before and after transformations. It greatly expands the scope of {\em translation} equivariance pinpointing the success of the Convolutional Neural Networks (CNNs) to develop a generic class of {\em transformation} equivariant representations. Unlike group equivariant convolutions that are limited to discrete transformations or linear transformation equivariance, we present a more flexible and tractable AutoEncoding Transformation (AET) model that can handle various types of transformations. Both deterministic AET and probabilistic Autoencoding Variational Transformations (AVT) models are presented. While the former trains transformation equivariant representations by directly reconstructing applied transformations, the latter is trained by maximizing the joint mutual information between the representations and the transformations. It leads to the Generalized TERs (GTERs) that could equivary against transformations in a more general manner by enabling them to capture more complex patterns of transformed visual structures beyond the linear TERs of a transformation group. We will further show that the presented approach can be extended to (semi-)supervised models by jointly maximizing the mutual information in the learned representations about the input labels and transformations. Experiment results following the standard evaluation protocols demonstrate the superior performances of the proposed models to the existing state-of-the-art unsupervised and (semi-)supervised approaches in literature.
Differential Recurrent Neural Network and its Application for Human Activity Recognition
May 09, 2019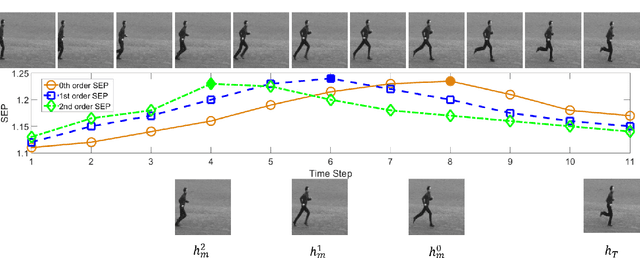
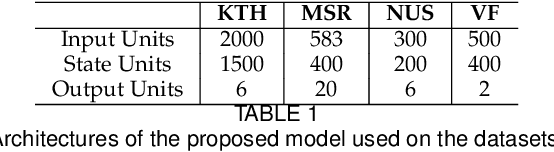

The Long Short-Term Memory (LSTM) recurrent neural network is capable of processing complex sequential information since it utilizes special gating schemes for learning representations from long input sequences. It has the potential to model any sequential time-series data, where the current hidden state has to be considered in the context of the past hidden states. This property makes LSTM an ideal choice to learn the complex dynamics present in long sequences. Unfortunately, the conventional LSTMs do not consider the impact of spatio-temporal dynamics corresponding to the given salient motion patterns, when they gate the information that ought to be memorized through time. To address this problem, we propose a differential gating scheme for the LSTM neural network, which emphasizes on the change in information gain caused by the salient motions between the successive video frames. This change in information gain is quantified by Derivative of States (DoS), and thus the proposed LSTM model is termed as differential Recurrent Neural Network (dRNN). In addition, the original work used the hidden state at the last time-step to model the entire video sequence. Based on the energy profiling of DoS, we further propose to employ the State Energy Profile (SEP) to search for salient dRNN states and construct more informative representations. The effectiveness of the proposed model was demonstrated by automatically recognizing human actions from the real-world 2D and 3D single-person action datasets. We point out that LSTM is a special form of dRNN. As a result, we have introduced a new family of LSTMs. Our study is one of the first works towards demonstrating the potential of learning complex time-series representations via high-order derivatives of states.
AVT: Unsupervised Learning of Transformation Equivariant Representations by Autoencoding Variational Transformations
Apr 01, 2019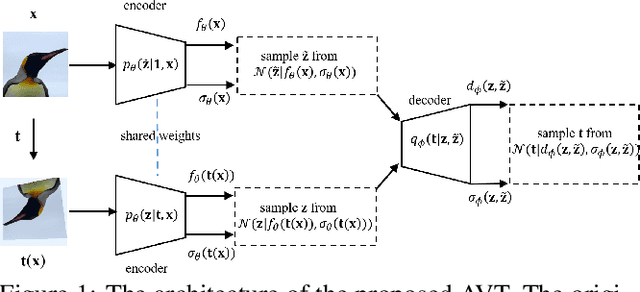
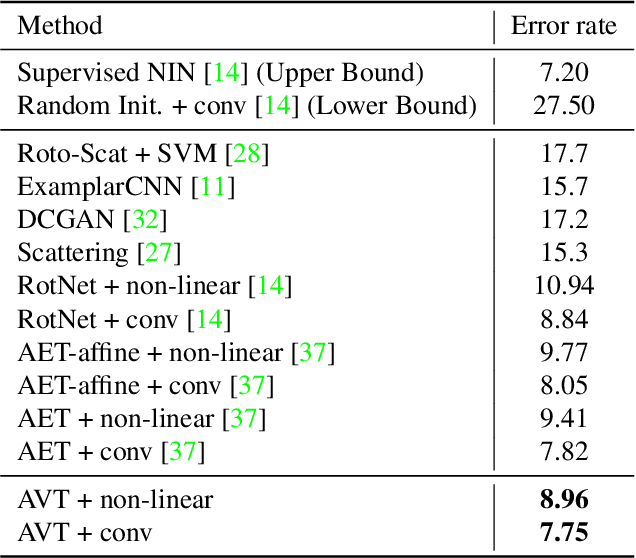
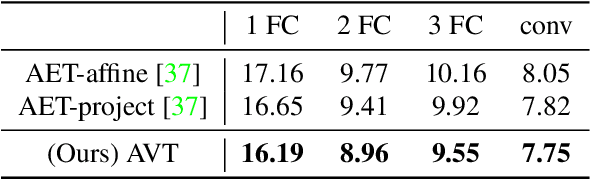
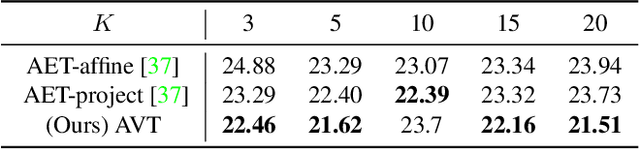
The learning of Transformation-Equivariant Representations (TERs), which is introduced by Hinton et al. \cite{hinton2011transforming}, has been considered as a principle to reveal visual structures under various transformations. It contains the celebrated Convolutional Neural Networks (CNNs) as a special case that only equivary to the translations. In contrast, we seek to train TERs for a generic class of transformations and train them in an {\em unsupervised} fashion. To this end, we present a novel principled method by Autoencoding Variational Transformations (AVT), compared with the conventional approach to autoencoding data. Formally, given transformed images, the AVT seeks to train the networks by maximizing the mutual information between the transformations and representations. This ensures the resultant TERs of individual images contain the {\em intrinsic} information about their visual structures that would equivary {\em extricably} under various transformations. Technically, we show that the resultant optimization problem can be efficiently solved by maximizing a variational lower-bound of the mutual information. This variational approach introduces a transformation decoder to approximate the intractable posterior of transformations, resulting in an autoencoding architecture with a pair of the representation encoder and the transformation decoder. Experiments demonstrate the proposed AVT model sets a new record for the performances on unsupervised tasks, greatly closing the performance gap to the supervised models.