 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review on Object Pose Recovery: from 3D Bounding Box Detectors to Full 6D Pose Estimators
Jan 28, 2020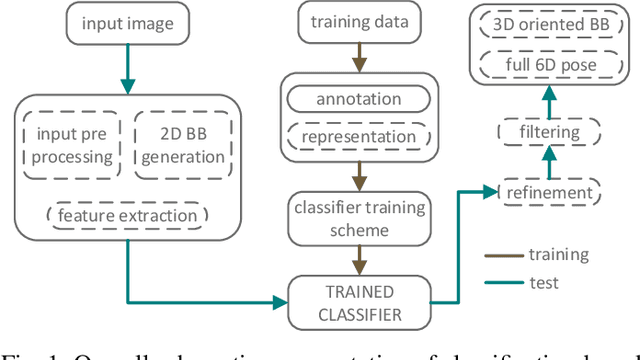
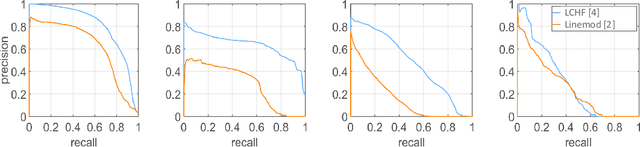
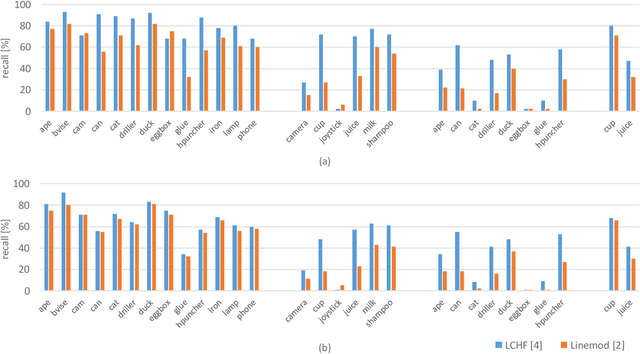
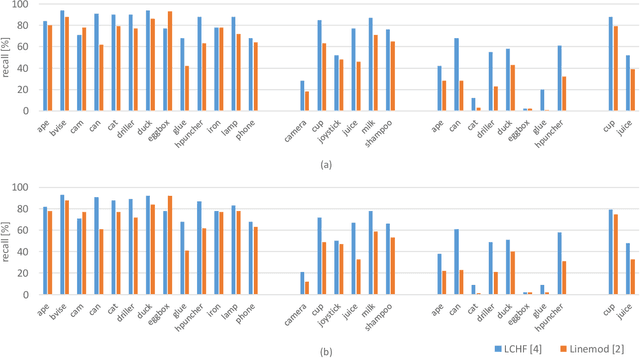
Object pose recovery has gained increasing attention in the computer vision field as it has become an important problem in rapidly evolving technological areas related to autonomous driving, robotics, and augmented reality. Existing review-related studies have addressed the problem at visual level in 2D, going through the methods which produce 2D bounding boxes of objects of interest in RGB images. The 2D search space is enlarged either using the geometry information available in the 3D space along with RGB (Mono/Stereo) images, or utilizing depth data from LIDAR sensors and/or RGB-D cameras. 3D bounding box detectors, producing category-level amodal 3D bounding boxes, are evaluated on gravity aligned images, while full 6D object pose estimators are mostly tested at instance-level on the images where the alignment constraint is removed. Recently, 6D object pose estimation is tackled at the level of categories. In this paper, we present the first comprehensive and most recent review of the methods on object pose recovery, from 3D bounding box detectors to full 6D pose estimators. The methods mathematically model the problem as a classification, regression, classification & regression, template matching, and point-pair feature matching task. Based on this, a mathematical-model-based categorization of the methods is established. Datasets used for evaluating the methods are investigated with respect to the challenges, and evaluation metrics are studied. Quantitative results of experiments in the literature are analysed to show which category of methods best performs across what types of challenges. The analyses are further extended comparing two methods, which are our own implementations, so that the outcomes from the public results are further solidified. Current position of the field is summarized regarding object pose recovery, and possible research directions are identified.
Active 6D Multi-Object Pose Estimation in Cluttered Scenarios with Deep Reinforcement Learning
Oct 19, 2019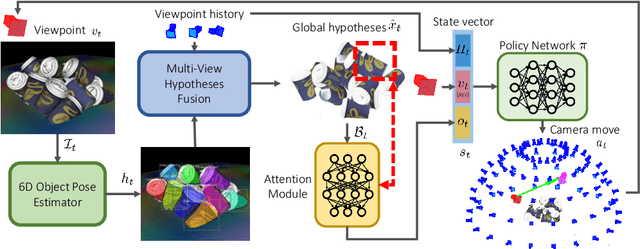
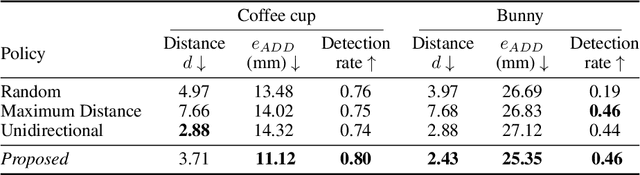
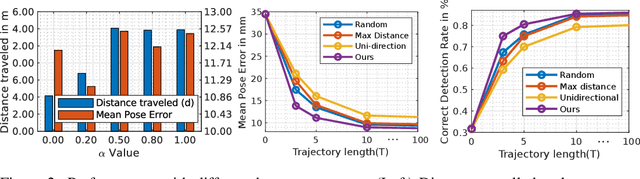
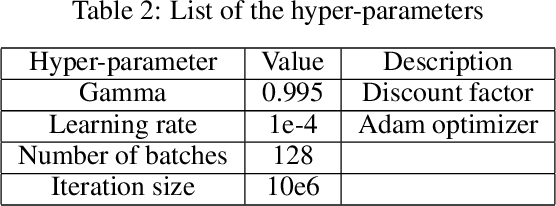
In this work, we explore how a strategic selection of camera movements can facilitate the task of 6D multi-object pose estimation in cluttered scenarios while respecting real-world constraints important in robotics and augmented reality applications, such as time and distance traveled. In the proposed framework, a set of multiple object hypotheses is given to an agent, which is inferred by an object pose estimator and subsequently spatio-temporally selected by a fusion function that makes use of a verification score that circumvents the need of ground-truth annotations. The agent reasons about these hypotheses, directing its attention to the object which it is most uncertain about, moving the camera towards such an object. Unlike previous works that propose short-sighted policies, our agent is trained in simulated scenarios using reinforcement learning, attempting to learn the camera moves that produce the most accurate object poses hypotheses for a given temporal and spatial budget, without the need of viewpoints rendering during inference. Our experiments show that the proposed approach successfully estimates the 6D object pose of a stack of objects in both challenging cluttered synthetic and real scenarios, showing superior performance compared to strong baselines.
Instance- and Category-level 6D Object Pose Estimation
Mar 11, 2019
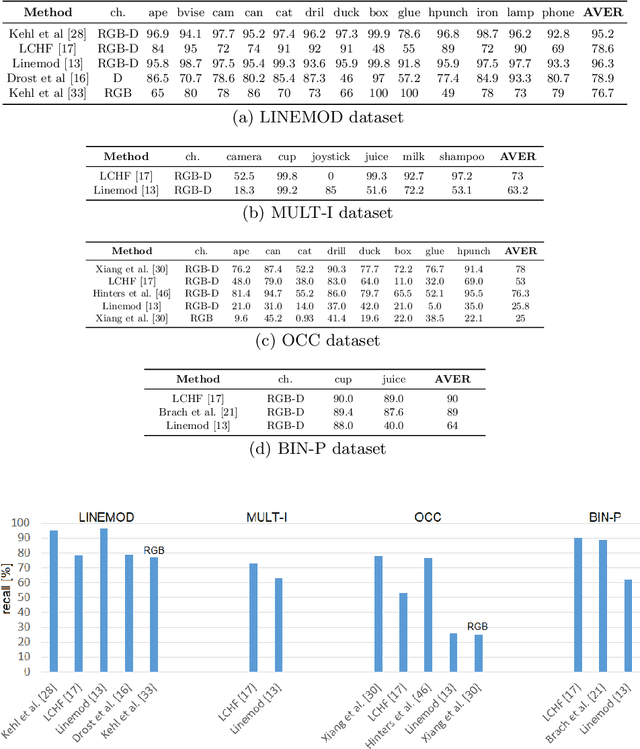

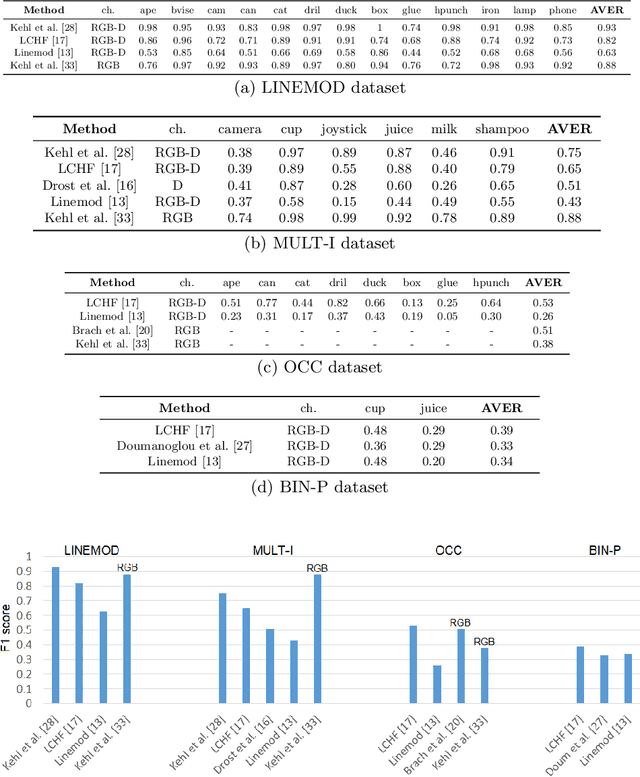
6D object pose estimation is an important task that determines the 3D position and 3D rotation of an object in camera-centred coordinates. By utilizing such a task, one can propose promising solutions for various problems related to scene understanding, augmented reality, control and navigation of robotics. Recent developments on visual depth sensors and low-cost availability of depth data significantly facilitate object pose estimation. Using depth information from RGB-D sensors, substantial progress has been made in the last decade by the methods addressing the challenges such as viewpoint variability, occlusion and clutter, and similar looking distractors. Particularly, with the recent advent of convolutional neural networks, RGB-only based solutions have been presented. However, improved results have only been reported for recovering the pose of known instances, i.e., for the instance-level object pose estimation tasks. More recently, state-of-the-art approaches target to solve object pose estimation problem at the level of categories, recovering the 6D pose of unknown instances. To this end, they address the challenges of the category-level tasks such as distribution shift among source and target domains, high intra-class variations, and shape discrepancies between objects.
HANDS18: Methods, Techniques and Applications for Hand Observation
Oct 25, 2018
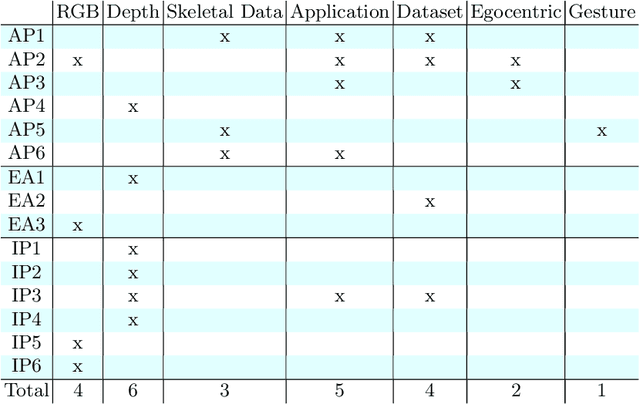
This report outlines the proceedings of the Fourth International Workshop on Observing and Understanding Hands in Action (HANDS 2018). The fourth instantiation of this workshop attracted significant interest from both academia and the industry. The program of the workshop included regular papers that are published as the workshop's proceedings, extended abstracts, invited posters, and invited talks. Topics of the submitted works and invited talks and posters included novel methods for hand pose estimation from RGB, depth, or skeletal data, datasets for special cases and real-world applications, and techniques for hand motion re-targeting and hand gesture recognition. The invited speakers are leaders in their respective areas of specialization, coming from both industry and academia. The main conclusions that can be drawn are the turn of the community towards RGB data and the maturation of some methods and techniques, which in turn has led to increasing interest for real-world applications.
Task-Oriented Hand Motion Retargeting for Dexterous Manipulation Imitation
Oct 03, 2018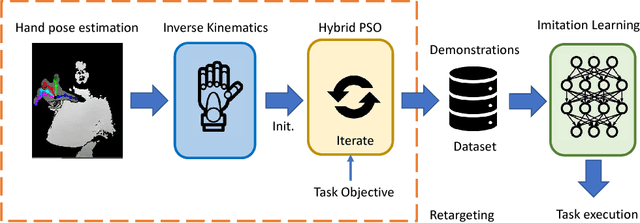
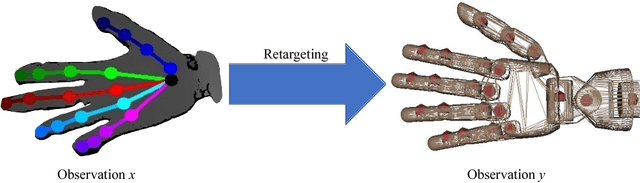
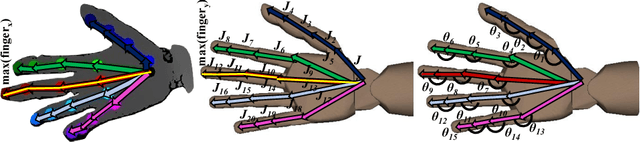
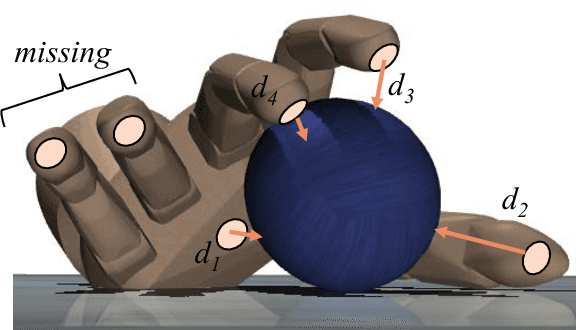
Human hand actions are quite complex, especially when they involve object manipulation, mainly due to the high dimensionality of the hand and the vast action space that entails. Imitating those actions with dexterous hand models involves different important and challenging steps: acquiring human hand information, retargeting it to a hand model, and learning a policy from acquired data. In this work, we capture the hand information by using a state-of-the-art hand pose estimator. We tackle the retargeting problem from the hand pose to a 29 DoF hand model by combining inverse kinematics and PSO with a task objective optimisation. This objective encourages the virtual hand to accomplish the manipulation task, relieving the effect of the estimator's noise and the domain gap. Our approach leads to a better success rate in the grasping task compared to our inverse kinematics baseline, allowing us to record successful human demonstrations. Furthermore, we used these demonstrations to learn a policy network using generative adversarial imitation learning (GAIL) that is able to autonomously grasp an object in the virtual space.
First-Person Hand Action Benchmark with RGB-D Videos and 3D Hand Pose Annotations
Apr 10, 2018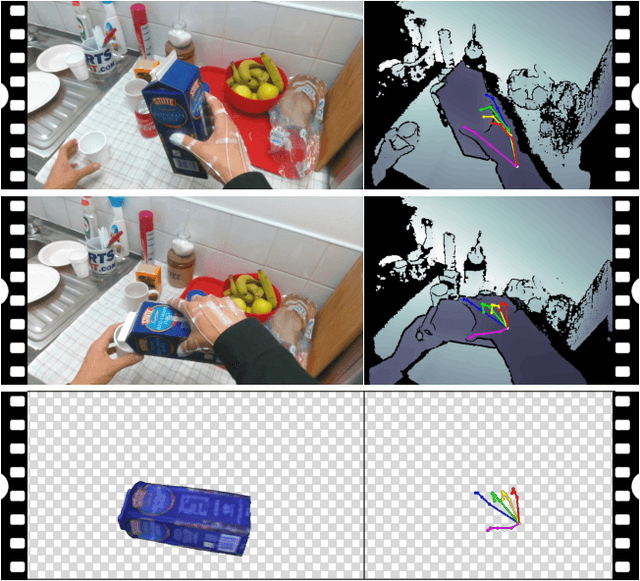
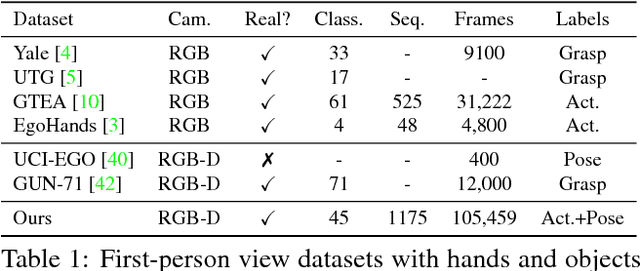
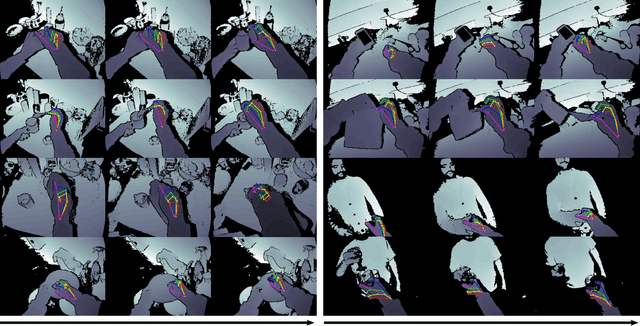

In this work we study the use of 3D hand poses to recognize first-person dynamic hand actions interacting with 3D objects. Towards this goal, we collected RGB-D video sequences comprised of more than 100K frames of 45 daily hand action categories, involving 26 different objects in several hand configurations. To obtain hand pose annotations, we used our own mo-cap system that automatically infers the 3D location of each of the 21 joints of a hand model via 6 magnetic sensors and inverse kinematics. Additionally, we recorded the 6D object poses and provide 3D object models for a subset of hand-object interaction sequences. To the best of our knowledge, this is the first benchmark that enables the study of first-person hand actions with the use of 3D hand poses. We present an extensive experimental evaluation of RGB-D and pose-based action recognition by 18 baselines/state-of-the-art approaches. The impact of using appearance features, poses, and their combinations are measured, and the different training/testing protocols are evaluated. Finally, we assess how ready the 3D hand pose estimation field is when hands are severely occluded by objects in egocentric views and its influence on action recognition. From the results, we see clear benefits of using hand pose as a cue for action recognition compared to other data modalities. Our dataset and experiments can be of interest to communities of 3D hand pose estimation, 6D object pose, and robotics as well as action recognition.
Depth-Based 3D Hand Pose Estimation: From Current Achievements to Future Goals
Mar 29, 2018
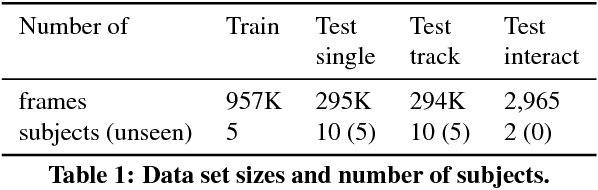
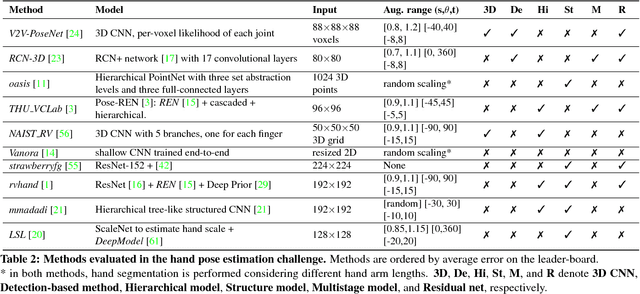
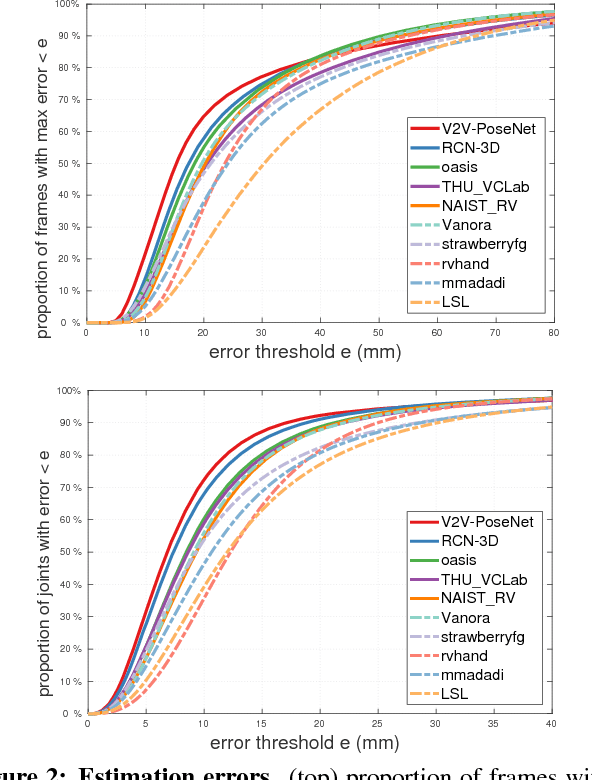
In this paper, we strive to answer two questions: What is the current state of 3D hand pose estimation from depth images? And, what are the next challenges that need to be tackled? Following the successful Hands In the Million Challenge (HIM2017), we investigate the top 10 state-of-the-art methods on three tasks: single frame 3D pose estimation, 3D hand tracking, and hand pose estimation during object interaction. We analyze the performance of different CNN structures with regard to hand shape, joint visibility, view point and articulation distributions. Our findings include: (1) isolated 3D hand pose estimation achieves low mean errors (10 mm) in the view point range of [70, 120] degrees, but it is far from being solved for extreme view points; (2) 3D volumetric representations outperform 2D CNNs, better capturing the spatial structure of the depth data; (3) Discriminative methods still generalize poorly to unseen hand shapes; (4) While joint occlusions pose a challenge for most methods, explicit modeling of structure constraints can significantly narrow the gap between errors on visible and occluded joints.
The 2017 Hands in the Million Challenge on 3D Hand Pose Estimation
Jul 07, 2017
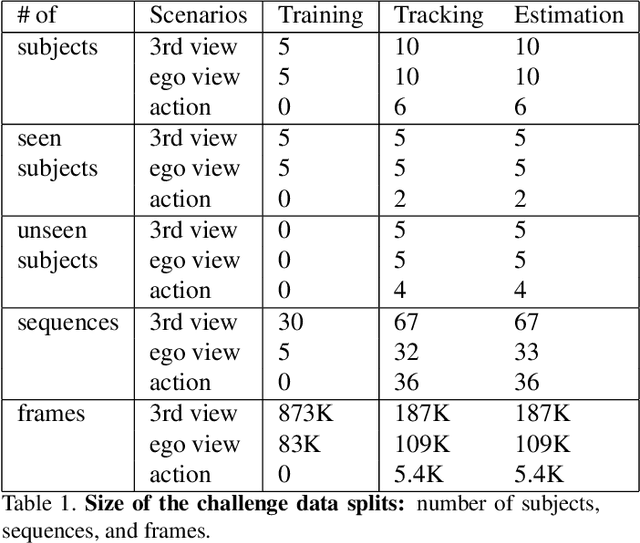

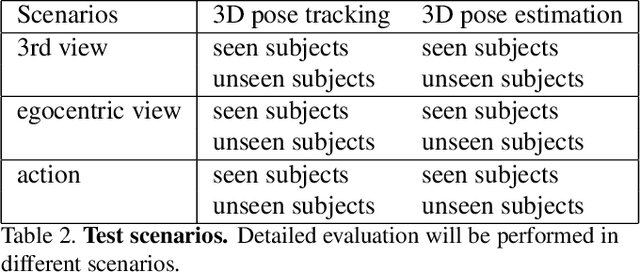
We present the 2017 Hands in the Million Challenge, a public competition designed for the evaluation of the task of 3D hand pose estimation. The goal of this challenge is to assess how far is the state of the art in terms of solving the problem of 3D hand pose estimation as well as detect major failure and strength modes of both systems and evaluation metrics that can help to identify future research directions. The challenge follows up the recent publication of BigHand2.2M and First-Person Hand Action datasets, which have been designed to exhaustively cover multiple hand, viewpoint, hand articulation, and occlusion. The challenge consists of a standardized dataset, an evaluation protocol for two different tasks, and a public competition. In this document we describe the different aspects of the challenge and, jointly with the results of the participants, it will be presented at the 3rd International Workshop on Observing and Understanding Hands in Action, HANDS 2017, with ICCV 2017.
Transition Forests: Learning Discriminative Temporal Transitions for Action Recognition and Detection
Mar 31, 2017

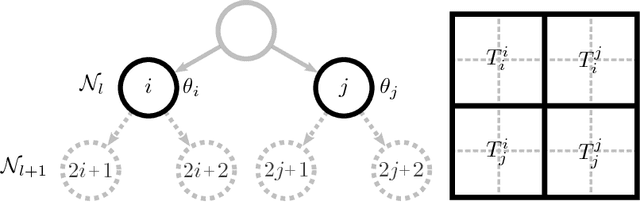
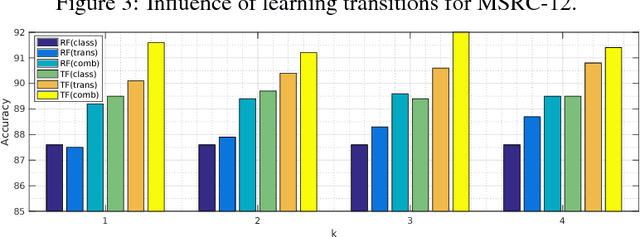
A human action can be seen as transitions between one's body poses over time, where the transition depicts a temporal relation between two poses. Recognizing actions thus involves learning a classifier sensitive to these pose transitions as well as to static poses. In this paper, we introduce a novel method called transitions forests, an ensemble of decision trees that both learn to discriminate static poses and transitions between pairs of two independent frames. During training, node splitting is driven by alternating two criteria: the standard classification objective that maximizes the discrimination power in individual frames, and the proposed one in pairwise frame transitions. Growing the trees tends to group frames that have similar associated transitions and share same action label incorporating temporal information that was not available otherwise. Unlike conventional decision trees where the best split in a node is determined independently of other nodes, the transition forests try to find the best split of nodes jointly (within a layer) for incorporating distant node transitions. When inferring the class label of a new frame, it is passed down the trees and the prediction is made based on previous frame predictions and the current one in an efficient and online manner. We apply our method on varied skeleton action recognition and online detection datasets showing its suitability over several baselines and state-of-the-art approaches.