 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGen-L-Video: Multi-Text to Long Video Generation via Temporal Co-Denoising
May 29, 2023



Leveraging large-scale image-text datasets and advancements in diffusion models, text-driven generative models have made remarkable strides in the field of image generation and editing. This study explores the potential of extending the text-driven ability to the generation and editing of multi-text conditioned long videos. Current methodologies for video generation and editing, while innovative, are often confined to extremely short videos (typically less than 24 frames) and are limited to a single text condition. These constraints significantly limit their applications given that real-world videos usually consist of multiple segments, each bearing different semantic information. To address this challenge, we introduce a novel paradigm dubbed as Gen-L-Video, capable of extending off-the-shelf short video diffusion models for generating and editing videos comprising hundreds of frames with diverse semantic segments without introducing additional training, all while preserving content consistency. We have implemented three mainstream text-driven video generation and editing methodologies and extended them to accommodate longer videos imbued with a variety of semantic segments with our proposed paradigm. Our experimental outcomes reveal that our approach significantly broadens the generative and editing capabilities of video diffusion models, offering new possibilities for future research and applications. The code is available at https://github.com/G-U-N/Gen-L-Video.
Temporal Enhanced Training of Multi-view 3D Object Detector via Historical Object Prediction
Apr 03, 2023



In this paper, we propose a new paradigm, named Historical Object Prediction (HoP) for multi-view 3D detection to leverage temporal information more effectively. The HoP approach is straightforward: given the current timestamp t, we generate a pseudo Bird's-Eye View (BEV) feature of timestamp t-k from its adjacent frames and utilize this feature to predict the object set at timestamp t-k. Our approach is motivated by the observation that enforcing the detector to capture both the spatial location and temporal motion of objects occurring at historical timestamps can lead to more accurate BEV feature learning. First, we elaborately design short-term and long-term temporal decoders, which can generate the pseudo BEV feature for timestamp t-k without the involvement of its corresponding camera images. Second, an additional object decoder is flexibly attached to predict the object targets using the generated pseudo BEV feature. Note that we only perform HoP during training, thus the proposed method does not introduce extra overheads during inference. As a plug-and-play approach, HoP can be easily incorporated into state-of-the-art BEV detection frameworks, including BEVFormer and BEVDet series. Furthermore, the auxiliary HoP approach is complementary to prevalent temporal modeling methods, leading to significant performance gains. Extensive experiments are conducted to evaluate the effectiveness of the proposed HoP on the nuScenes dataset. We choose the representative methods, including BEVFormer and BEVDet4D-Depth to evaluate our method. Surprisingly, HoP achieves 68.5% NDS and 62.4% mAP with ViT-L on nuScenes test, outperforming all the 3D object detectors on the leaderboard. Codes will be available at https://github.com/Sense-X/HoP.
Teach-DETR: Better Training DETR with Teachers
Nov 23, 2022In this paper, we present a novel training scheme, namely Teach-DETR, to learn better DETR-based detectors from versatile teacher detectors. We show that the predicted boxes from teacher detectors are effective medium to transfer knowledge of teacher detectors, which could be either RCNN-based or DETR-based detectors, to train a more accurate and robust DETR model. This new training scheme can easily incorporate the predicted boxes from multiple teacher detectors, each of which provides parallel supervisions to the student DETR. Our strategy introduces no additional parameters and adds negligible computational cost to the original detector during training. During inference, Teach-DETR brings zero additional overhead and maintains the merit of requiring no non-maximum suppression. Extensive experiments show that our method leads to consistent improvement for various DETR-based detectors. Specifically, we improve the state-of-the-art detector DINO with Swin-Large backbone, 4 scales of feature maps and 36-epoch training schedule, from 57.8% to 58.9% in terms of mean average precision on MSCOCO 2017 validation set. Code will be available at https://github.com/LeonHLJ/Teach-DETR.
DETRs with Collaborative Hybrid Assignments Training
Nov 22, 2022In this paper, we provide the observation that too few queries assigned as positive samples in DETR with one-to-one set matching leads to sparse supervisions on the encoder's output which considerably hurt the discriminative feature learning of the encoder and vice visa for attention learning in the decoder. To alleviate this, we present a novel collaborative hybrid assignments training scheme, namely Co-DETR, to learn more efficient and effective DETR-based detectors from versatile label assignment manners. This new training scheme can easily enhance the encoder's learning ability in end-to-end detectors by training the multiple parallel auxiliary heads supervised by one-to-many label assignments such as ATSS, FCOS, and Faster RCNN. In addition, we conduct extra customized positive queries by extracting the positive coordinates from these auxiliary heads to improve the training efficiency of positive samples in the decoder. In inference, these auxiliary heads are discarded and thus our method introduces no additional parameters and computational cost to the original detector while requiring no hand-crafted non-maximum suppression (NMS). We conduct extensive experiments to evaluate the effectiveness of the proposed approach on DETR variants, including DAB-DETR, Deformable-DETR, and H-Deformable-DETR. Specifically, we improve the basic Deformable-DETR by 5.8% in 12-epoch training and 3.2% in 36-epoch training. The state-of-the-art H-Deformable-DETR can still be improved from 57.9% to 58.7% on the MS COCO val. Surprisingly, incorporated with the large-scale backbone MixMIM-g with 1-Billion parameters, we achieve the 64.5% mAP on MS COCO test-dev, achieving superior performance with much fewer extra data sizes. Codes will be available at https://github.com/Sense-X/Co-DETR.
Towards Robust Face Recognition with Comprehensive Search
Aug 29, 2022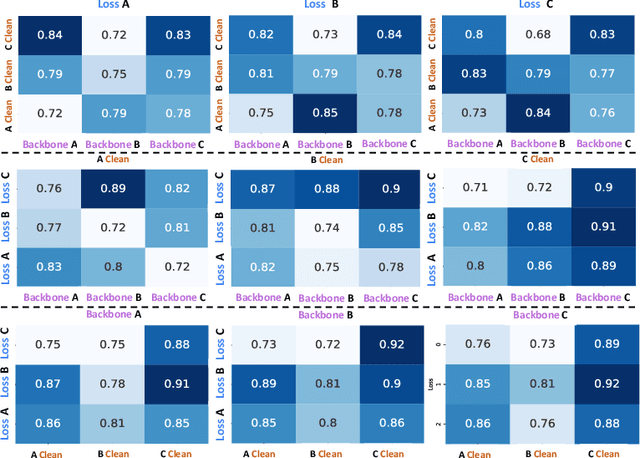
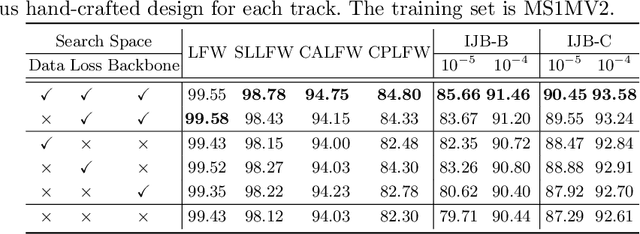
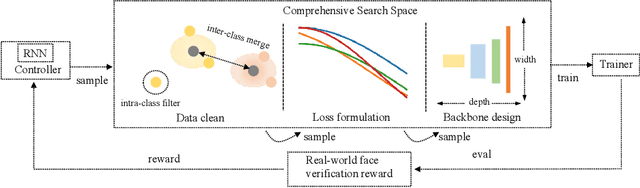
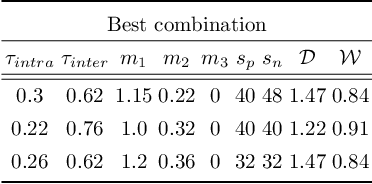
Data cleaning, architecture, and loss function design are important factors contributing to high-performance face recognition. Previously, the research community tries to improve the performance of each single aspect but failed to present a unified solution on the joint search of the optimal designs for all three aspects. In this paper, we for the first time identify that these aspects are tightly coupled to each other. Optimizing the design of each aspect actually greatly limits the performance and biases the algorithmic design. Specifically, we find that the optimal model architecture or loss function is closely coupled with the data cleaning. To eliminate the bias of single-aspect research and provide an overall understanding of the face recognition model design, we first carefully design the search space for each aspect, then a comprehensive search method is introduced to jointly search optimal data cleaning, architecture, and loss function design. In our framework, we make the proposed comprehensive search as flexible as possible, by using an innovative reinforcement learning based approach. Extensive experiments on million-level face recognition benchmarks demonstrate the effectiveness of our newly-designed search space for each aspect and the comprehensive search. We outperform expert algorithms developed for each single research track by large margins. More importantly, we analyze the difference between our searched optimal design and the independent design of the single factors. We point out that strong models tend to optimize with more difficult training datasets and loss functions. Our empirical study can provide guidance in future research towards more robust face recognition systems.
Unifying Visual Perception by Dispersible Points Learning
Aug 18, 2022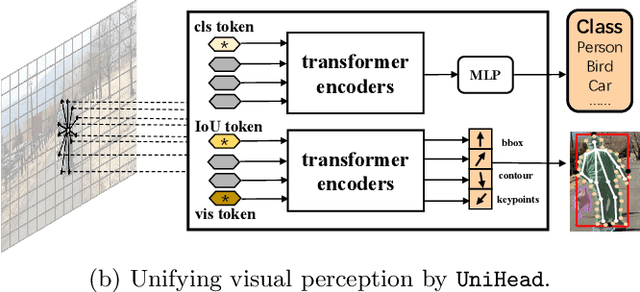
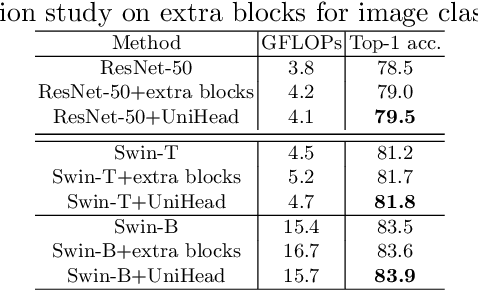
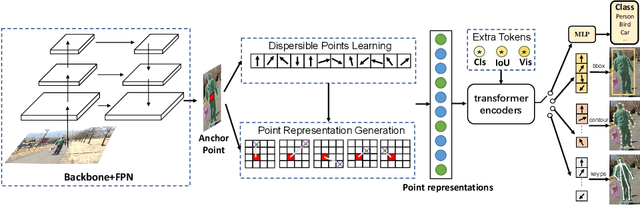
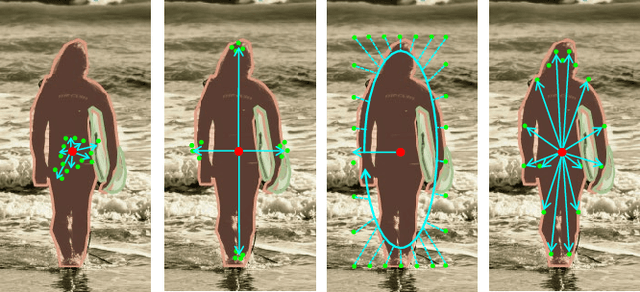
We present a conceptually simple, flexible, and universal visual perception head for variant visual tasks, e.g., classification, object detection, instance segmentation and pose estimation, and different frameworks, such as one-stage or two-stage pipelines. Our approach effectively identifies an object in an image while simultaneously generating a high-quality bounding box or contour-based segmentation mask or set of keypoints. The method, called UniHead, views different visual perception tasks as the dispersible points learning via the transformer encoder architecture. Given a fixed spatial coordinate, UniHead adaptively scatters it to different spatial points and reasons about their relations by transformer encoder. It directly outputs the final set of predictions in the form of multiple points, allowing us to perform different visual tasks in different frameworks with the same head design. We show extensive evaluations on ImageNet classification and all three tracks of the COCO suite of challenges, including object detection, instance segmentation and pose estimation. Without bells and whistles, UniHead can unify these visual tasks via a single visual head design and achieve comparable performance compared to expert models developed for each task.We hope our simple and universal UniHead will serve as a solid baseline and help promote universal visual perception research. Code and models are available at https://github.com/Sense-X/UniHead.
Rethinking Robust Representation Learning Under Fine-grained Noisy Faces
Aug 08, 2022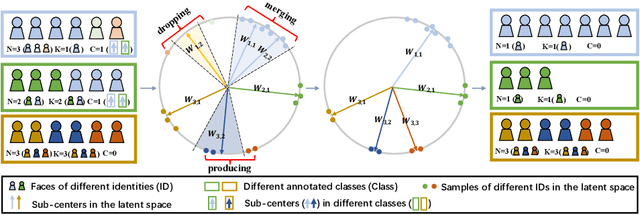

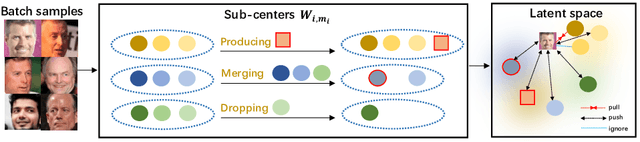
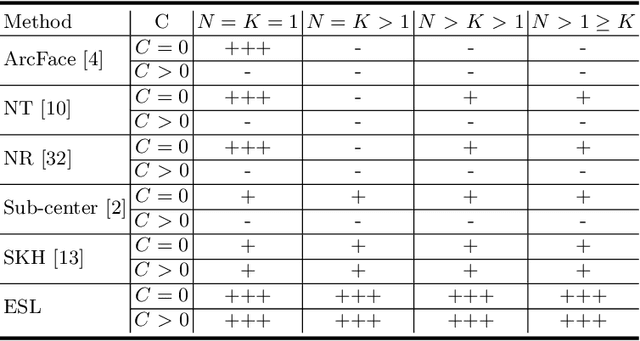
Learning robust feature representation from large-scale noisy faces stands out as one of the key challenges in high-performance face recognition. Recent attempts have been made to cope with this challenge by alleviating the intra-class conflict and inter-class conflict. However, the unconstrained noise type in each conflict still makes it difficult for these algorithms to perform well. To better understand this, we reformulate the noise type of each class in a more fine-grained manner as N-identities|K^C-clusters. Different types of noisy faces can be generated by adjusting the values of \nkc. Based on this unified formulation, we found that the main barrier behind the noise-robust representation learning is the flexibility of the algorithm under different N, K, and C. For this potential problem, we propose a new method, named Evolving Sub-centers Learning~(ESL), to find optimal hyperplanes to accurately describe the latent space of massive noisy faces. More specifically, we initialize M sub-centers for each class and ESL encourages it to be automatically aligned to N-identities|K^C-clusters faces via producing, merging, and dropping operations. Images belonging to the same identity in noisy faces can effectively converge to the same sub-center and samples with different identities will be pushed away. We inspect its effectiveness with an elaborate ablation study on the synthetic noisy dataset with different N, K, and C. Without any bells and whistles, ESL can achieve significant performance gains over state-of-the-art methods on large-scale noisy faces
UniNet: Unified Architecture Search with Convolution, Transformer, and MLP
Jul 12, 2022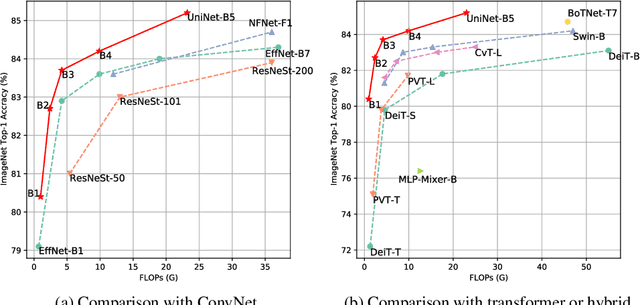
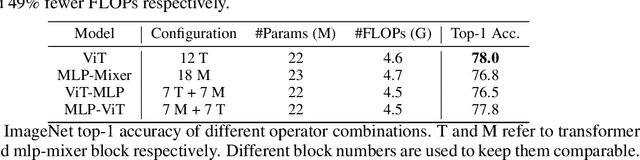
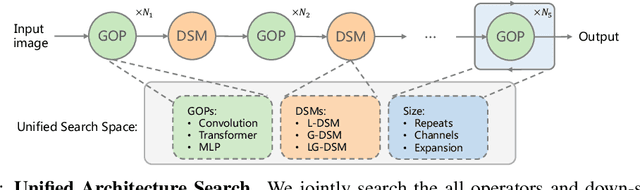
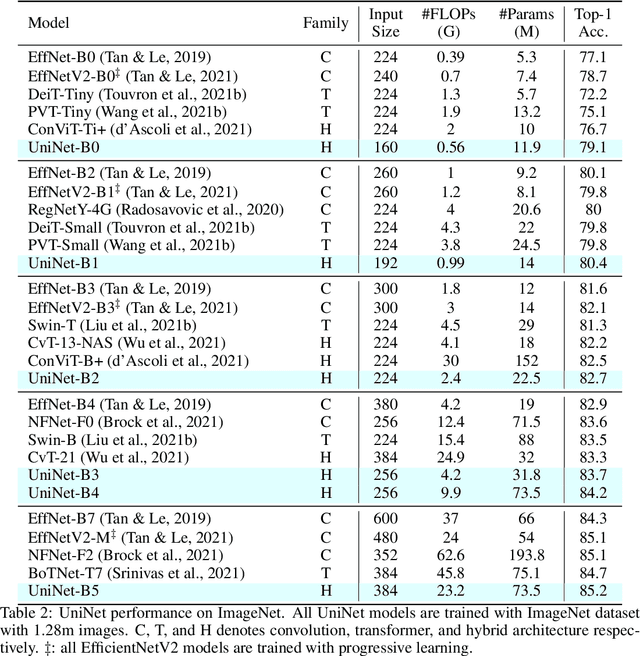
Recently, transformer and multi-layer perceptron (MLP) architectures have achieved impressive results on various vision tasks. However, how to effectively combine those operators to form high-performance hybrid visual architectures still remains a challenge. In this work, we study the learnable combination of convolution, transformer, and MLP by proposing a novel unified architecture search approach. Our approach contains two key designs to achieve the search for high-performance networks. First, we model the very different searchable operators in a unified form, and thus enable the operators to be characterized with the same set of configuration parameters. In this way, the overall search space size is significantly reduced, and the total search cost becomes affordable. Second, we propose context-aware downsampling modules (DSMs) to mitigate the gap between the different types of operators. Our proposed DSMs are able to better adapt features from different types of operators, which is important for identifying high-performance hybrid architectures. Finally, we integrate configurable operators and DSMs into a unified search space and search with a Reinforcement Learning-based search algorithm to fully explore the optimal combination of the operators. To this end, we search a baseline network and scale it up to obtain a family of models, named UniNets, which achieve much better accuracy and efficiency than previous ConvNets and Transformers. In particular, our UniNet-B5 achieves 84.9% top-1 accuracy on ImageNet, outperforming EfficientNet-B7 and BoTNet-T7 with 44% and 55% fewer FLOPs respectively. By pretraining on the ImageNet-21K, our UniNet-B6 achieves 87.4%, outperforming Swin-L with 51% fewer FLOPs and 41% fewer parameters. Code is available at https://github.com/Sense-X/UniNet.
UniFormer: Unified Transformer for Efficient Spatiotemporal Representation Learning
Feb 08, 2022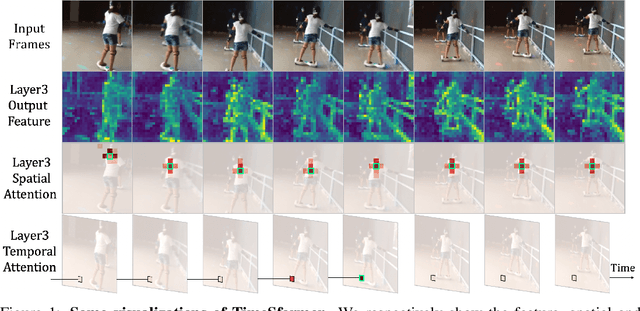

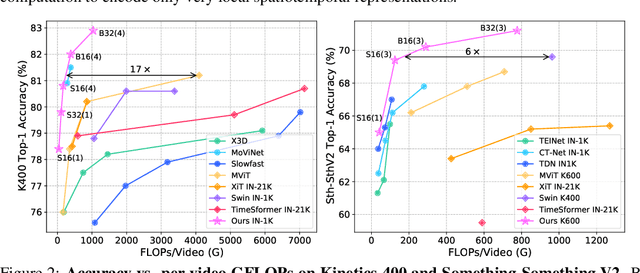
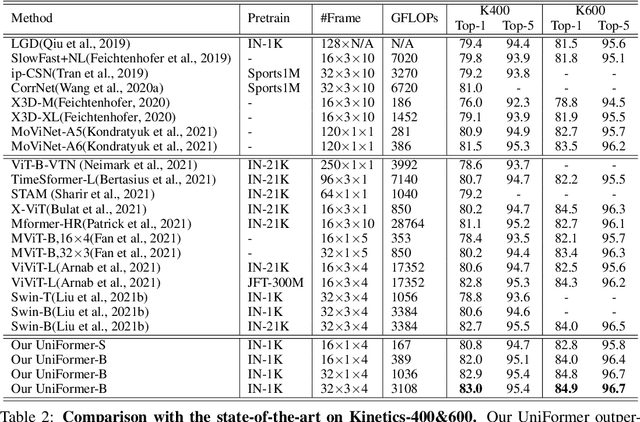
It is a challenging task to learn rich and multi-scale spatiotemporal semantics from high-dimensional videos, due to large local redundancy and complex global dependency between video frames. The recent advances in this research have been mainly driven by 3D convolutional neural networks and vision transformers. Although 3D convolution can efficiently aggregate local context to suppress local redundancy from a small 3D neighborhood, it lacks the capability to capture global dependency because of the limited receptive field. Alternatively, vision transformers can effectively capture long-range dependency by self-attention mechanism, while having the limitation on reducing local redundancy with blind similarity comparison among all the tokens in each layer. Based on these observations, we propose a novel Unified transFormer (UniFormer) which seamlessly integrates merits of 3D convolution and spatiotemporal self-attention in a concise transformer format, and achieves a preferable balance between computation and accuracy. Different from traditional transformers, our relation aggregator can tackle both spatiotemporal redundancy and dependency, by learning local and global token affinity respectively in shallow and deep layers. We conduct extensive experiments on the popular video benchmarks, e.g., Kinetics-400, Kinetics-600, and Something-Something V1&V2. With only ImageNet-1K pretraining, our UniFormer achieves 82.9%/84.8% top-1 accuracy on Kinetics-400/Kinetics-600, while requiring 10x fewer GFLOPs than other state-of-the-art methods. For Something-Something V1 and V2, our UniFormer achieves new state-of-the-art performances of 60.9% and 71.2% top-1 accuracy respectively. Code is available at https://github.com/Sense-X/UniFormer.
UniFormer: Unifying Convolution and Self-attention for Visual Recognition
Jan 24, 2022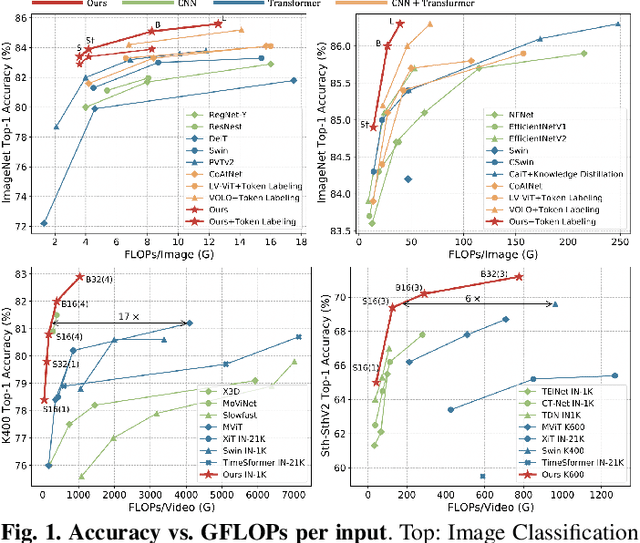
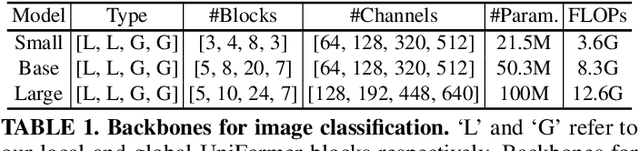

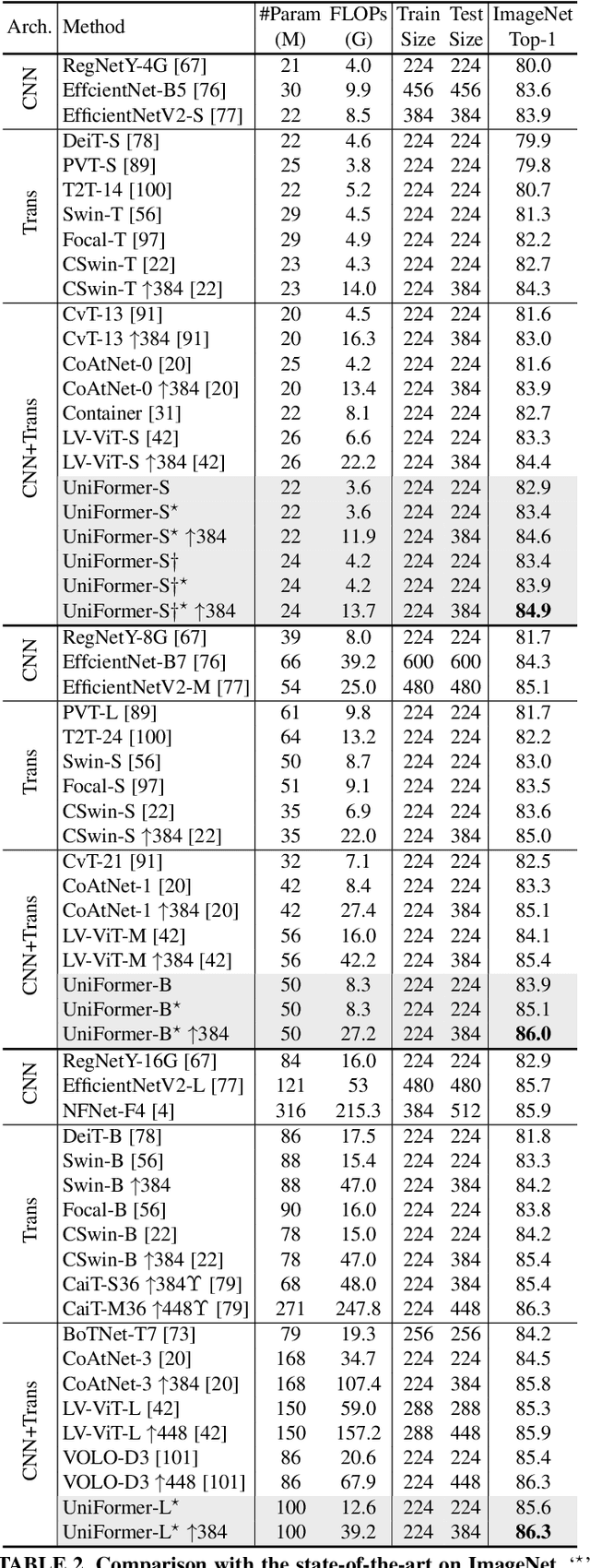
It is a challenging task to learn discriminative representation from images and videos, due to large local redundancy and complex global dependency in these visual data. Convolution neural networks (CNNs) and vision transformers (ViTs) have been two dominant frameworks in the past few years. Though CNNs can efficiently decrease local redundancy by convolution within a small neighborhood, the limited receptive field makes it hard to capture global dependency. Alternatively, ViTs can effectively capture long-range dependency via self-attention, while blind similarity comparisons among all the tokens lead to high redundancy. To resolve these problems, we propose a novel Unified transFormer (UniFormer), which can seamlessly integrate the merits of convolution and self-attention in a concise transformer format. Different from the typical transformer blocks, the relation aggregators in our UniFormer block are equipped with local and global token affinity respectively in shallow and deep layers, allowing to tackle both redundancy and dependency for efficient and effective representation learning. Finally, we flexibly stack our UniFormer blocks into a new powerful backbone, and adopt it for various vision tasks from image to video domain, from classification to dense prediction. Without any extra training data, our UniFormer achieves 86.3 top-1 accuracy on ImageNet-1K classification. With only ImageNet-1K pre-training, it can simply achieve state-of-the-art performance in a broad range of downstream tasks, e.g., it obtains 82.9/84.8 top-1 accuracy on Kinetics-400/600, 60.9/71.2 top-1 accuracy on Something-Something V1/V2 video classification tasks, 53.8 box AP and 46.4 mask AP on COCO object detection task, 50.8 mIoU on ADE20K semantic segmentation task, and 77.4 AP on COCO pose estimation task. Code is available at https://github.com/Sense-X/UniFormer.