 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTD-GEN: Graph Generation With Tree Decomposition
Jun 20, 2021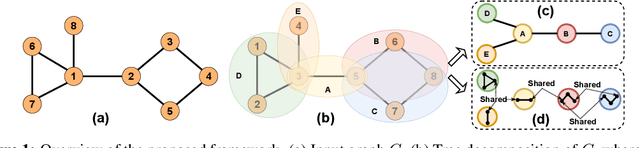
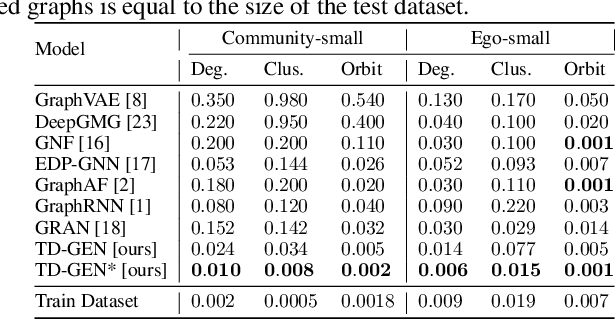
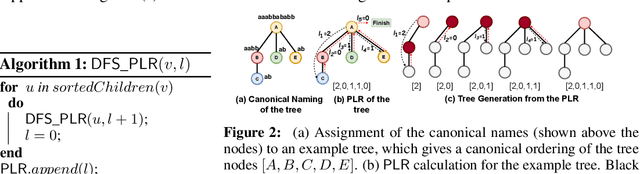
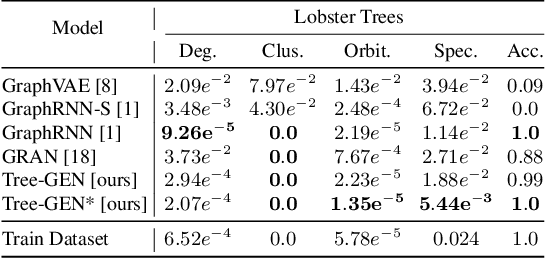
We propose TD-GEN, a graph generation framework based on tree decomposition, and introduce a reduced upper bound on the maximum number of decisions needed for graph generation. The framework includes a permutation invariant tree generation model which forms the backbone of graph generation. Tree nodes are supernodes, each representing a cluster of nodes in the graph. Graph nodes and edges are incrementally generated inside the clusters by traversing the tree supernodes, respecting the structure of the tree decomposition, and following node sharing decisions between the clusters. Finally, we discuss the shortcomings of standard evaluation criteria based on statistical properties of the generated graphs as performance measures. We propose to compare the performance of models based on likelihood. Empirical results on a variety of standard graph generation datasets demonstrate the superior performance of our method.
Piggyback GAN: Efficient Lifelong Learning for Image Conditioned Generation
Apr 24, 2021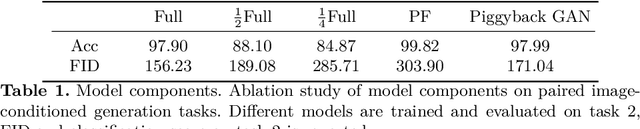
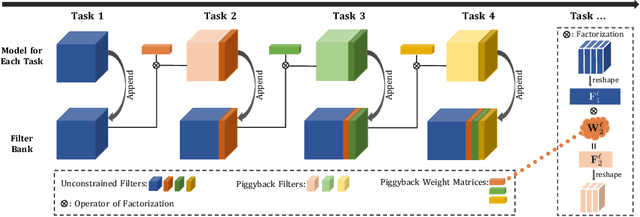
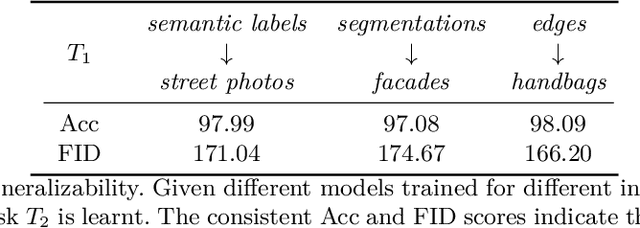
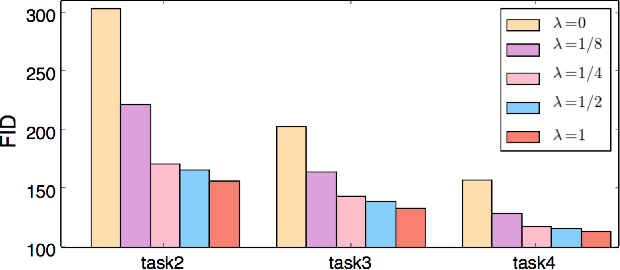
Humans accumulate knowledge in a lifelong fashion. Modern deep neural networks, on the other hand, are susceptible to catastrophic forgetting: when adapted to perform new tasks, they often fail to preserve their performance on previously learned tasks. Given a sequence of tasks, a naive approach addressing catastrophic forgetting is to train a separate standalone model for each task, which scales the total number of parameters drastically without efficiently utilizing previous models. In contrast, we propose a parameter efficient framework, Piggyback GAN, which learns the current task by building a set of convolutional and deconvolutional filters that are factorized into filters of the models trained on previous tasks. For the current task, our model achieves high generation quality on par with a standalone model at a lower number of parameters. For previous tasks, our model can also preserve generation quality since the filters for previous tasks are not altered. We validate Piggyback GAN on various image-conditioned generation tasks across different domains, and provide qualitative and quantitative results to show that the proposed approach can address catastrophic forgetting effectively and efficiently.
Adaptive Appearance Rendering
Apr 24, 2021
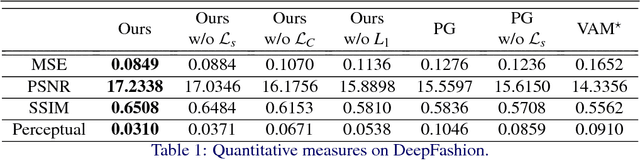
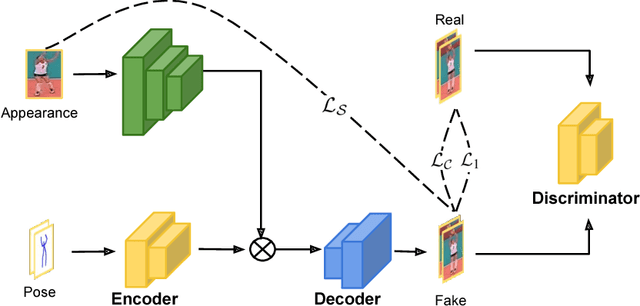
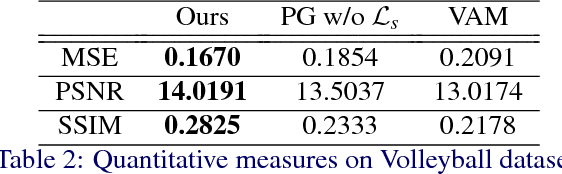
We propose an approach to generate images of people given a desired appearance and pose. Disentangled representations of pose and appearance are necessary to handle the compound variability in the resulting generated images. Hence, we develop an approach based on intermediate representations of poses and appearance: our pose-guided appearance rendering network firstly encodes the targets' poses using an encoder-decoder neural network. Then the targets' appearances are encoded by learning adaptive appearance filters using a fully convolutional network. Finally, these filters are placed in the encoder-decoder neural networks to complete the rendering. We demonstrate that our model can generate images and videos that are superior to state-of-the-art methods, and can handle pose guided appearance rendering in both image and video generation.
Learning Discriminative Prototypes with Dynamic Time Warping
Mar 17, 2021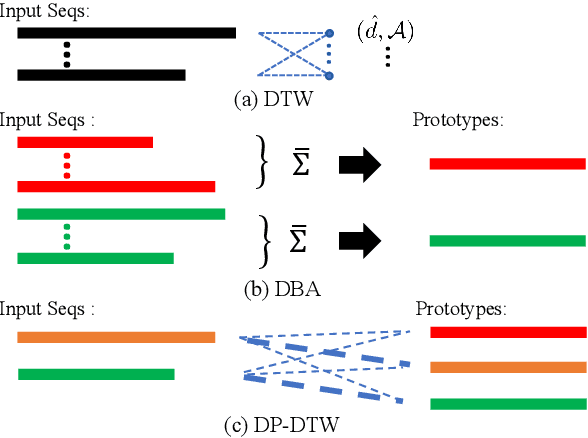

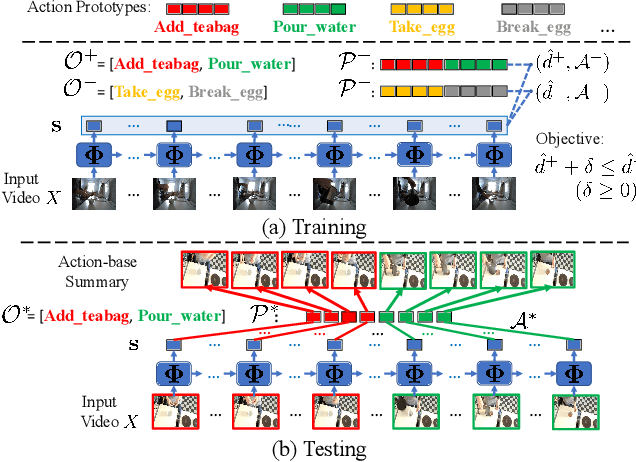
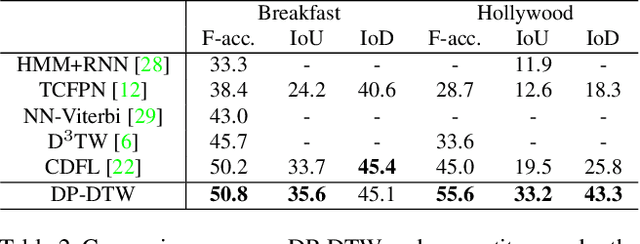
Dynamic Time Warping (DTW) is widely used for temporal data processing. However, existing methods can neither learn the discriminative prototypes of different classes nor exploit such prototypes for further analysis. We propose Discriminative Prototype DTW (DP-DTW), a novel method to learn class-specific discriminative prototypes for temporal recognition tasks. DP-DTW shows superior performance compared to conventional DTWs on time series classification benchmarks. Combined with end-to-end deep learning, DP-DTW can handle challenging weakly supervised action segmentation problems and achieves state of the art results on standard benchmarks. Moreover, detailed reasoning on the input video is enabled by the learned action prototypes. Specifically, an action-based video summarization can be obtained by aligning the input sequence with action prototypes.
Variational Selective Autoencoder: Learning from Partially-Observed Heterogeneous Data
Feb 25, 2021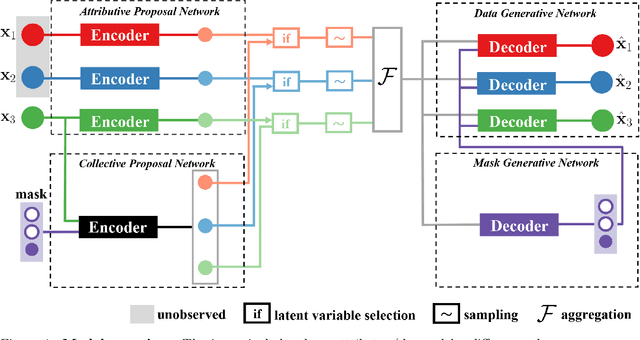
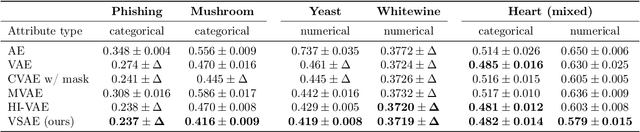
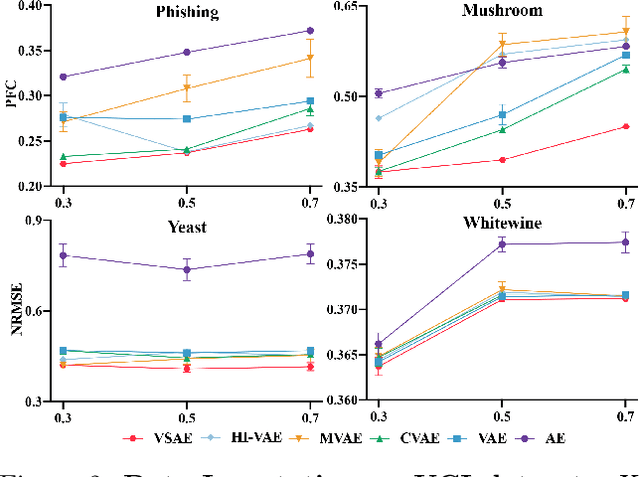
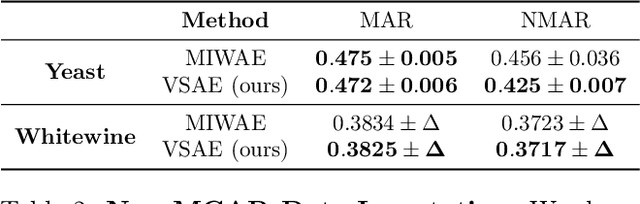
Learning from heterogeneous data poses challenges such as combining data from various sources and of different types. Meanwhile, heterogeneous data are often associated with missingness in real-world applications due to heterogeneity and noise of input sources. In this work, we propose the variational selective autoencoder (VSAE), a general framework to learn representations from partially-observed heterogeneous data. VSAE learns the latent dependencies in heterogeneous data by modeling the joint distribution of observed data, unobserved data, and the imputation mask which represents how the data are missing. It results in a unified model for various downstream tasks including data generation and imputation. Evaluation on both low-dimensional and high-dimensional heterogeneous datasets for these two tasks shows improvement over state-of-the-art models.
Activity Graph Transformer for Temporal Action Localization
Jan 28, 2021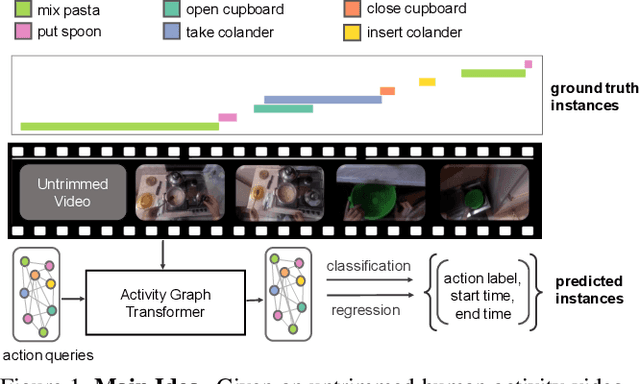
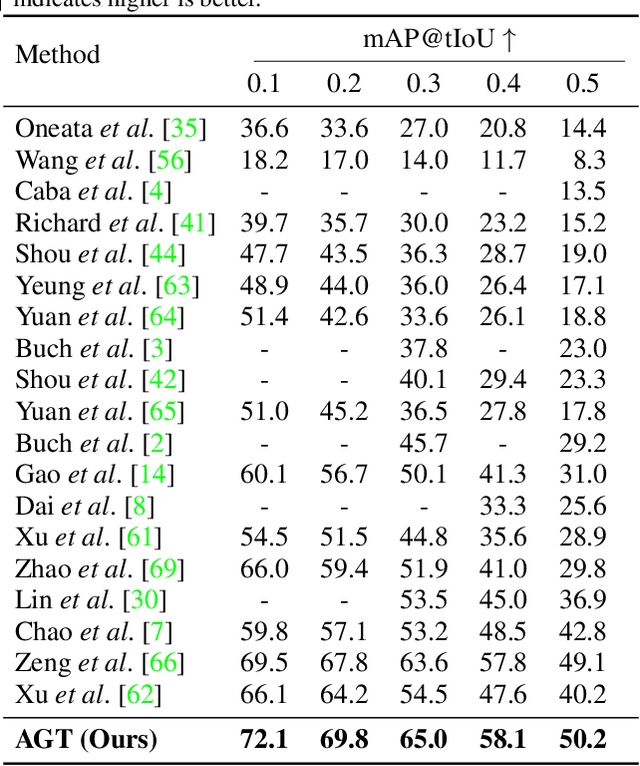
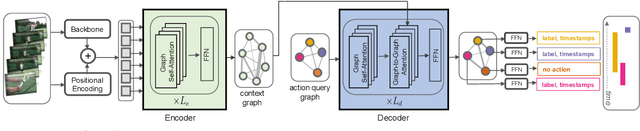

We introduce Activity Graph Transformer, an end-to-end learnable model for temporal action localization, that receives a video as input and directly predicts a set of action instances that appear in the video. Detecting and localizing action instances in untrimmed videos requires reasoning over multiple action instances in a video. The dominant paradigms in the literature process videos temporally to either propose action regions or directly produce frame-level detections. However, sequential processing of videos is problematic when the action instances have non-sequential dependencies and/or non-linear temporal ordering, such as overlapping action instances or re-occurrence of action instances over the course of the video. In this work, we capture this non-linear temporal structure by reasoning over the videos as non-sequential entities in the form of graphs. We evaluate our model on challenging datasets: THUMOS14, Charades, and EPIC-Kitchens-100. Our results show that our proposed model outperforms the state-of-the-art by a considerable margin.
Neural fidelity warping for efficient robot morphology design
Dec 09, 2020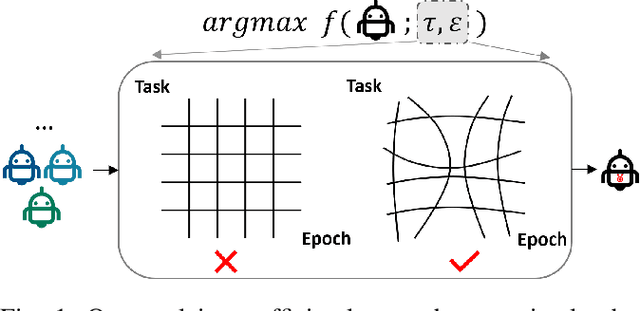
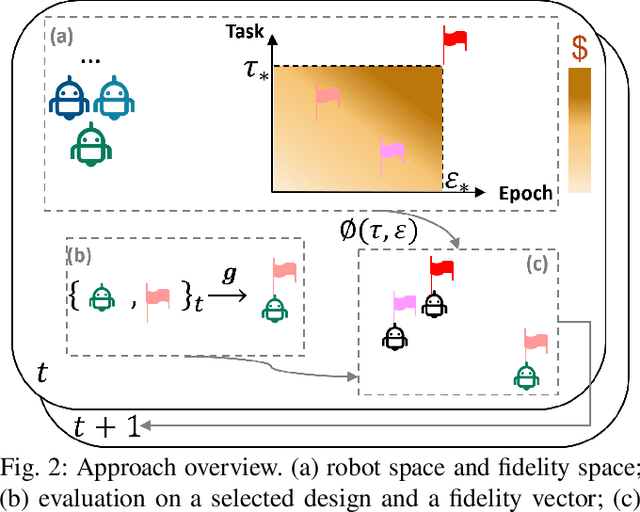
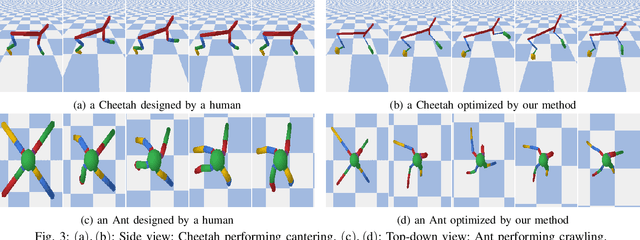
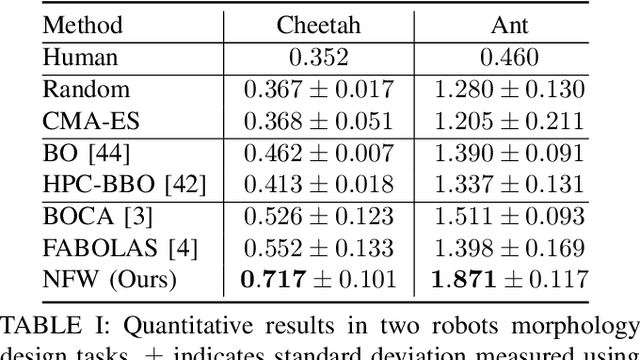
We consider the problem of optimizing a robot morphology to achieve the best performance for a target task, under computational resource limitations. The evaluation process for each morphological design involves learning a controller for the design, which can consume substantial time and computational resources. To address the challenge of expensive robot morphology evaluation, we present a continuous multi-fidelity Bayesian Optimization framework that efficiently utilizes computational resources via low-fidelity evaluations. We identify the problem of non-stationarity over fidelity space. Our proposed fidelity warping mechanism can learn representations of learning epochs and tasks to model non-stationary covariances between continuous fidelity evaluations which prove challenging for off-the-shelf stationary kernels. Various experiments demonstrate that our method can utilize the low-fidelity evaluations to efficiently search for the optimal robot morphology, outperforming state-of-the-art methods.
MCMI: Multi-Cycle Image Translation with Mutual Information Constraints
Jul 06, 2020
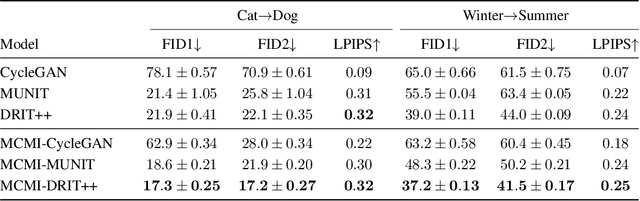

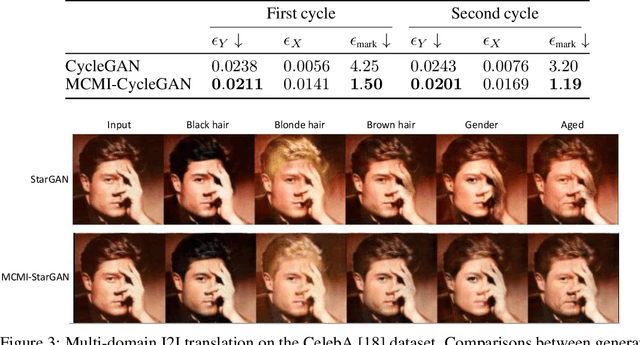
We present a mutual information-based framework for unsupervised image-to-image translation. Our MCMI approach treats single-cycle image translation models as modules that can be used recurrently in a multi-cycle translation setting where the translation process is bounded by mutual information constraints between the input and output images. The proposed mutual information constraints can improve cross-domain mappings by optimizing out translation functions that fail to satisfy the Markov property during image translations. We show that models trained with MCMI produce higher quality images and learn more semantically-relevant mappings compared to state-of-the-art image translation methods. The MCMI framework can be applied to existing unpaired image-to-image translation models with minimum modifications. Qualitative experiments and a perceptual study demonstrate the image quality improvements and generality of our approach using several backbone models and a variety of image datasets.
House-GAN: Relational Generative Adversarial Networks for Graph-constrained House Layout Generation
Mar 16, 2020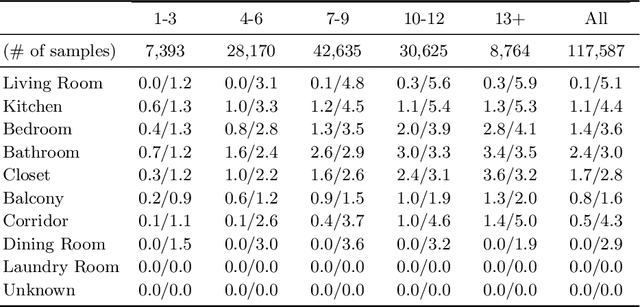
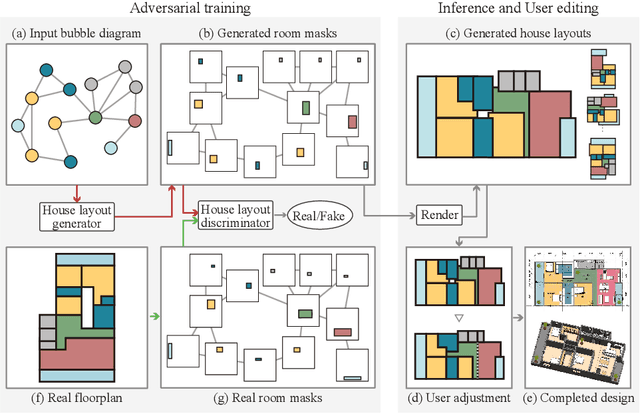
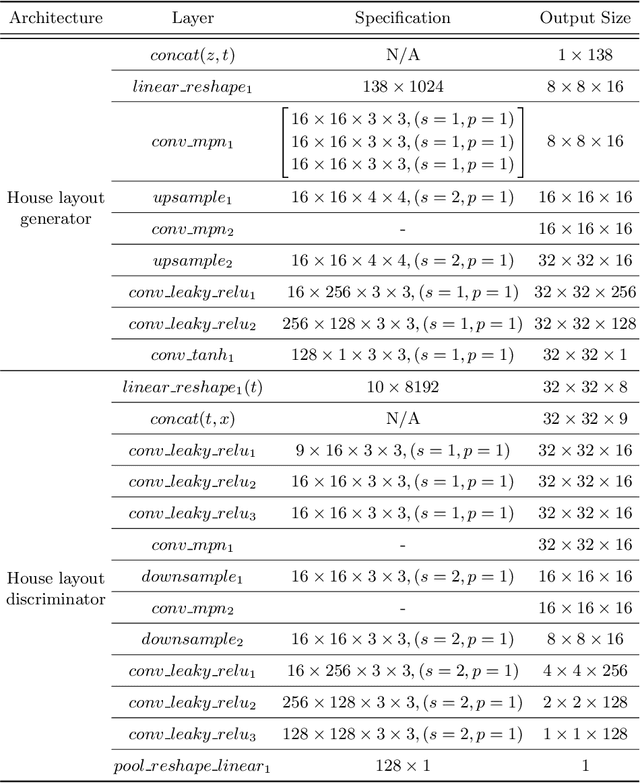
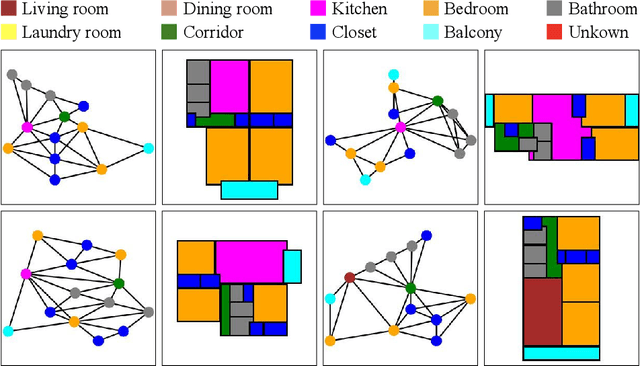
This paper proposes a novel graph-constrained generative adversarial network, whose generator and discriminator are built upon relational architecture. The main idea is to encode the constraint into the graph structure of its relational networks. We have demonstrated the proposed architecture for a new house layout generation problem, whose task is to take an architectural constraint as a graph (i.e., the number and types of rooms with their spatial adjacency) and produce a set of axis-aligned bounding boxes of rooms. We measure the quality of generated house layouts with the three metrics: the realism, the diversity, and the compatibility with the input graph constraint. Our qualitative and quantitative evaluations over 117,000 real floorplan images demonstrate that the proposed approach outperforms existing methods and baselines. We will publicly share all our code and data.
Modeling Continuous Stochastic Processes with Dynamic Normalizing Flows
Feb 24, 2020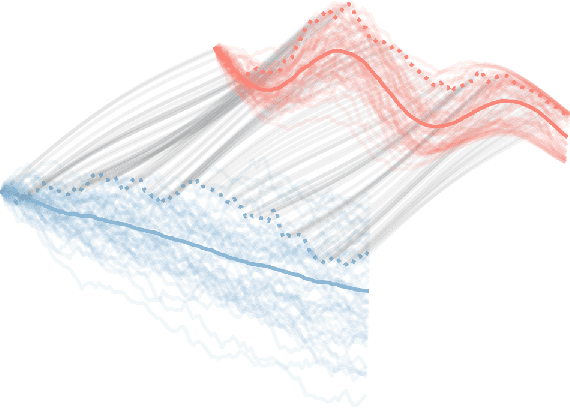
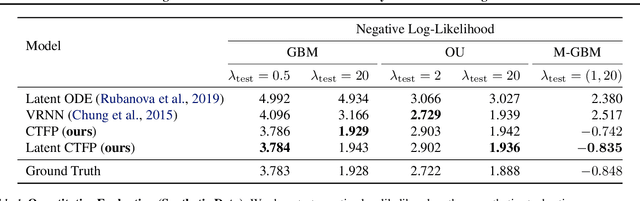
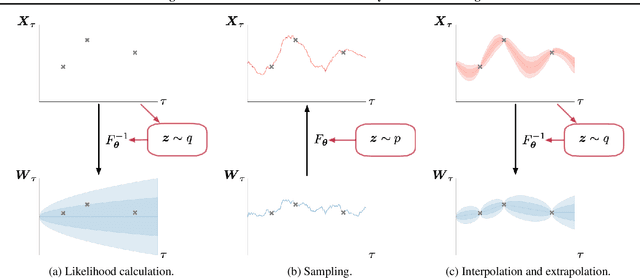

Normalizing flows transform a simple base distribution into a complex target distribution and have proved to be powerful models for data generation and density estimation. In this work, we propose a novel type of normalizing flow driven by a differential deformation of the continuous-time Wiener process. As a result, we obtain a rich time series model whose observable process inherits many of the appealing properties of its base process, such as efficient computation of likelihoods and marginals. Furthermore, our continuous treatment provides a natural framework for irregular time series with an independent arrival process, including straightforward interpolation. We illustrate the desirable properties of the proposed model on popular stochastic processes and demonstrate its superior flexibility to variational RNN and latent ODE baselines in a series of experiments on synthetic and real-world data.