 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Optimization in Games via Control Theory: Connecting Regret, Passivity and Poincaré Recurrence
Jun 15, 2021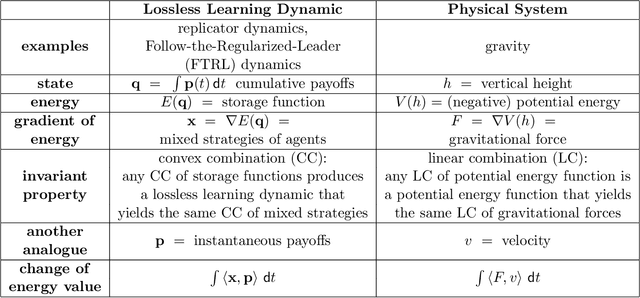



We present a novel control-theoretic understanding of online optimization and learning in games, via the notion of passivity. Passivity is a fundamental concept in control theory, which abstracts energy conservation and dissipation in physical systems. It has become a standard tool in analysis of general feedback systems, to which game dynamics belong. Our starting point is to show that all continuous-time Follow-the-Regularized-Leader (FTRL) dynamics, which include the well-known Replicator Dynamic, are lossless, i.e. it is passive with no energy dissipation. Interestingly, we prove that passivity implies bounded regret, connecting two fundamental primitives of control theory and online optimization. The observation of energy conservation in FTRL inspires us to present a family of lossless learning dynamics, each of which has an underlying energy function with a simple gradient structure. This family is closed under convex combination; as an immediate corollary, any convex combination of FTRL dynamics is lossless and thus has bounded regret. This allows us to extend the framework of Fox and Shamma [Games, 2013] to prove not just global asymptotic stability results for game dynamics, but Poincar\'e recurrence results as well. Intuitively, when a lossless game (e.g. graphical constant-sum game) is coupled with lossless learning dynamics, their feedback interconnection is also lossless, which results in a pendulum-like energy-preserving recurrent behavior, generalizing the results of Piliouras and Shamma [SODA, 2014] and Mertikopoulos, Papadimitriou and Piliouras [SODA, 2018].
Efficient Online Learning for Dynamic k-Clustering
Jun 08, 2021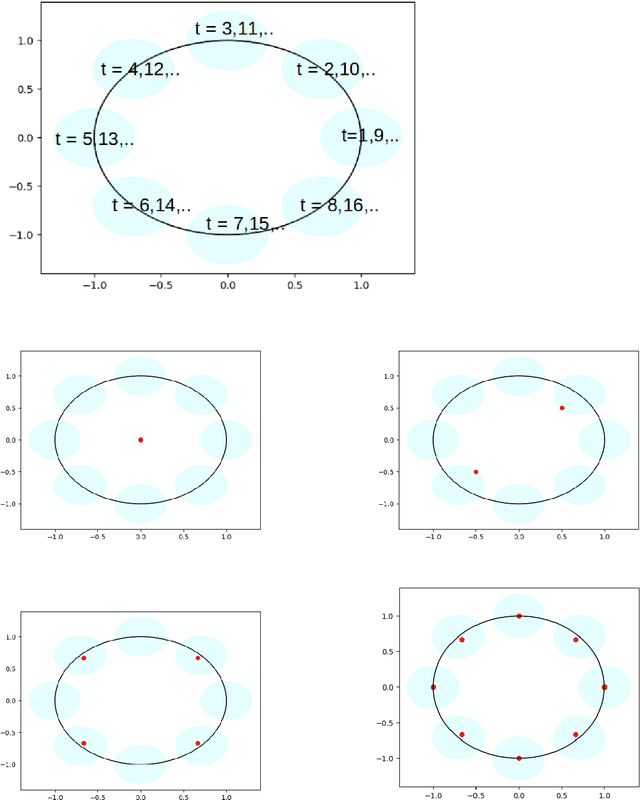
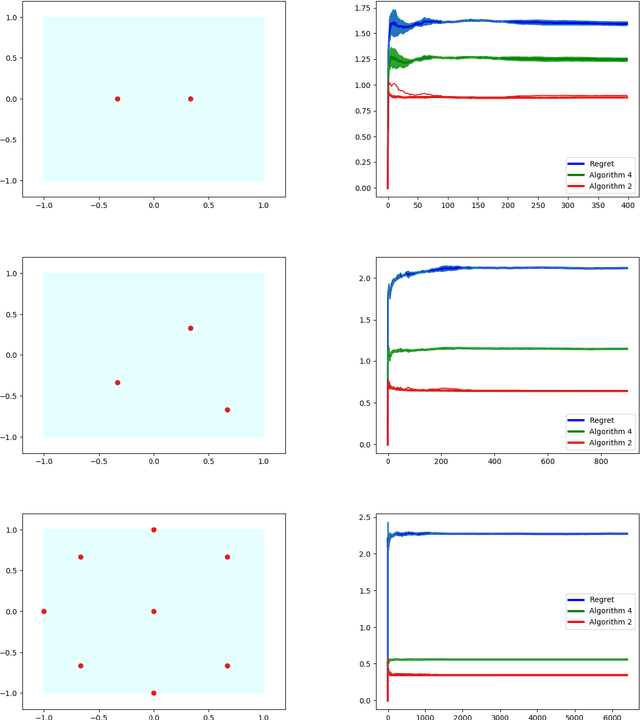
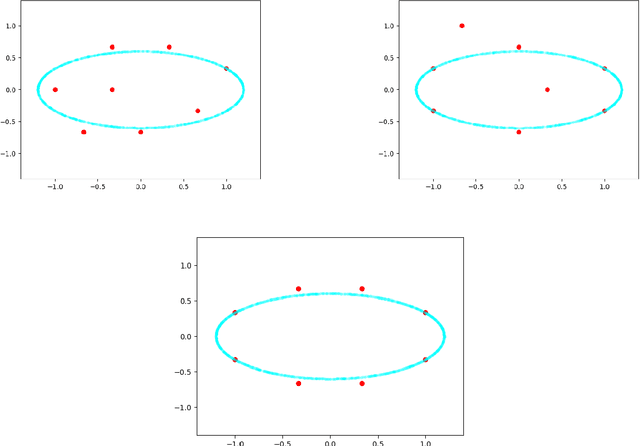
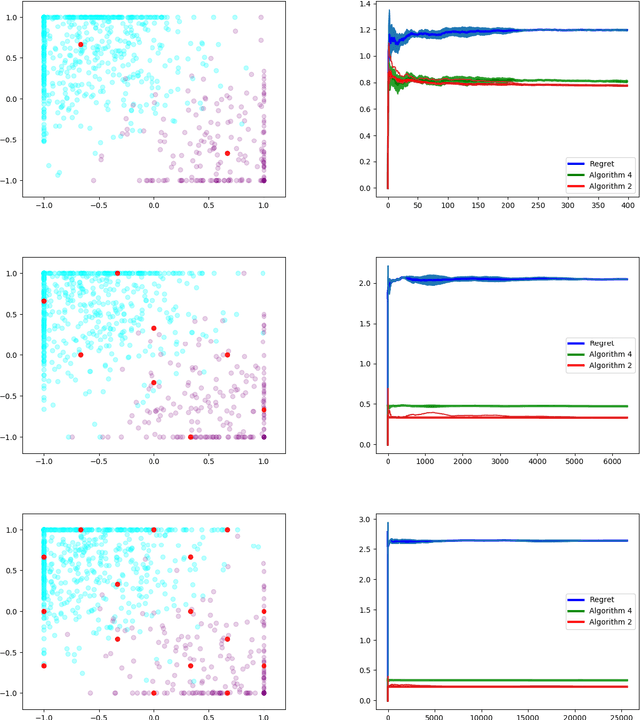
We study dynamic clustering problems from the perspective of online learning. We consider an online learning problem, called \textit{Dynamic $k$-Clustering}, in which $k$ centers are maintained in a metric space over time (centers may change positions) such as a dynamically changing set of $r$ clients is served in the best possible way. The connection cost at round $t$ is given by the \textit{$p$-norm} of the vector consisting of the distance of each client to its closest center at round $t$, for some $p\geq 1$ or $p = \infty$. We present a \textit{$\Theta\left( \min(k,r) \right)$-regret} polynomial-time online learning algorithm and show that, under some well-established computational complexity conjectures, \textit{constant-regret} cannot be achieved in polynomial-time. In addition to the efficient solution of Dynamic $k$-Clustering, our work contributes to the long line of research on combinatorial online learning.
Global Convergence of Multi-Agent Policy Gradient in Markov Potential Games
Jun 03, 2021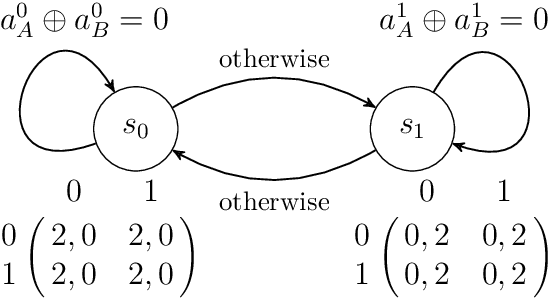
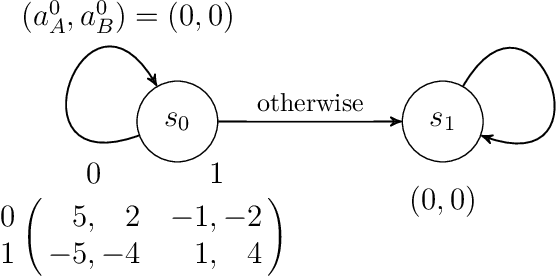
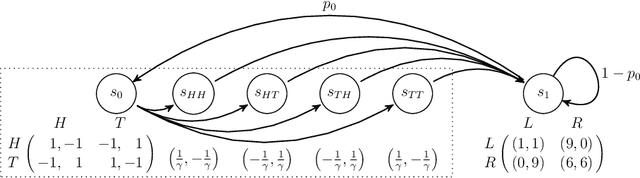
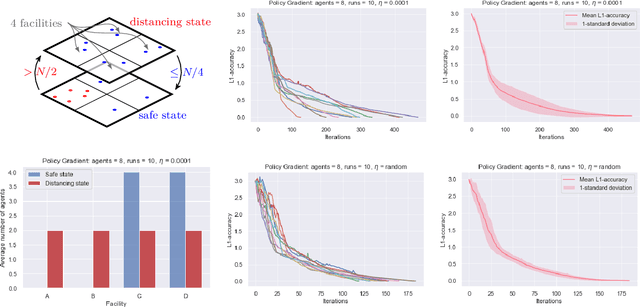
Potential games are arguably one of the most important and widely studied classes of normal form games. They define the archetypal setting of multi-agent coordination as all agent utilities are perfectly aligned with each other via a common potential function. Can this intuitive framework be transplanted in the setting of Markov Games? What are the similarities and differences between multi-agent coordination with and without state dependence? We present a novel definition of Markov Potential Games (MPG) that generalizes prior attempts at capturing complex stateful multi-agent coordination. Counter-intuitively, insights from normal-form potential games do not carry over as MPGs can consist of settings where state-games can be zero-sum games. In the opposite direction, Markov games where every state-game is a potential game are not necessarily MPGs. Nevertheless, MPGs showcase standard desirable properties such as the existence of deterministic Nash policies. In our main technical result, we prove fast convergence of independent policy gradient to Nash policies by adapting recent gradient dominance property arguments developed for single agent MDPs to multi-agent learning settings.
Learning in Matrix Games can be Arbitrarily Complex
Mar 05, 2021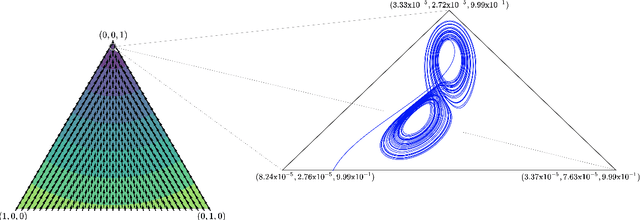
A growing number of machine learning architectures, such as Generative Adversarial Networks, rely on the design of games which implement a desired functionality via a Nash equilibrium. In practice these games have an implicit complexity (e.g. from underlying datasets and the deep networks used) that makes directly computing a Nash equilibrium impractical or impossible. For this reason, numerous learning algorithms have been developed with the goal of iteratively converging to a Nash equilibrium. Unfortunately, the dynamics generated by the learning process can be very intricate and instances of training failure hard to interpret. In this paper we show that, in a strong sense, this dynamic complexity is inherent to games. Specifically, we prove that replicator dynamics, the continuous-time analogue of Multiplicative Weights Update, even when applied in a very restricted class of games -- known as finite matrix games -- is rich enough to be able to approximate arbitrary dynamical systems. Our results are positive in the sense that they show the nearly boundless dynamic modelling capabilities of current machine learning practices, but also negative in implying that these capabilities may come at the cost of interpretability. As a concrete example, we show how replicator dynamics can effectively reproduce the well-known strange attractor of Lonrenz dynamics (the "butterfly effect") while achieving no regret.
Scaling up Mean Field Games with Online Mirror Descent
Feb 28, 2021
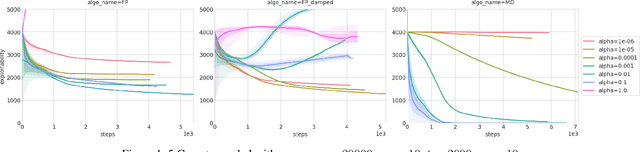

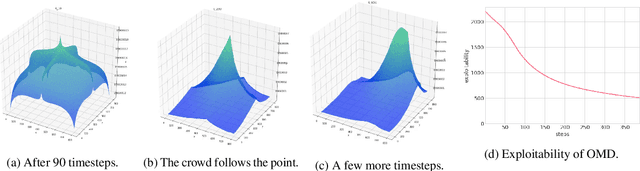
We address scaling up equilibrium computation in Mean Field Games (MFGs) using Online Mirror Descent (OMD). We show that continuous-time OMD provably converges to a Nash equilibrium under a natural and well-motivated set of monotonicity assumptions. This theoretical result nicely extends to multi-population games and to settings involving common noise. A thorough experimental investigation on various single and multi-population MFGs shows that OMD outperforms traditional algorithms such as Fictitious Play (FP). We empirically show that OMD scales up and converges significantly faster than FP by solving, for the first time to our knowledge, examples of MFGs with hundreds of billions states. This study establishes the state-of-the-art for learning in large-scale multi-agent and multi-population games.
Follow-the-Regularized-Leader Routes to Chaos in Routing Games
Feb 17, 2021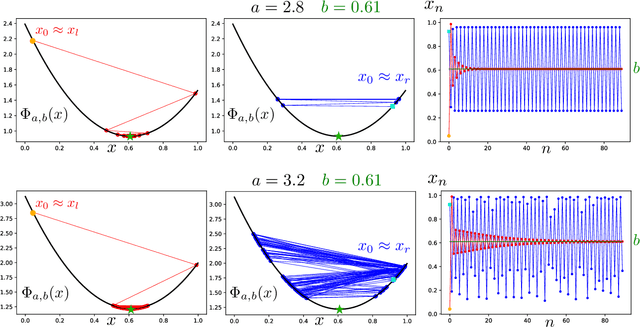
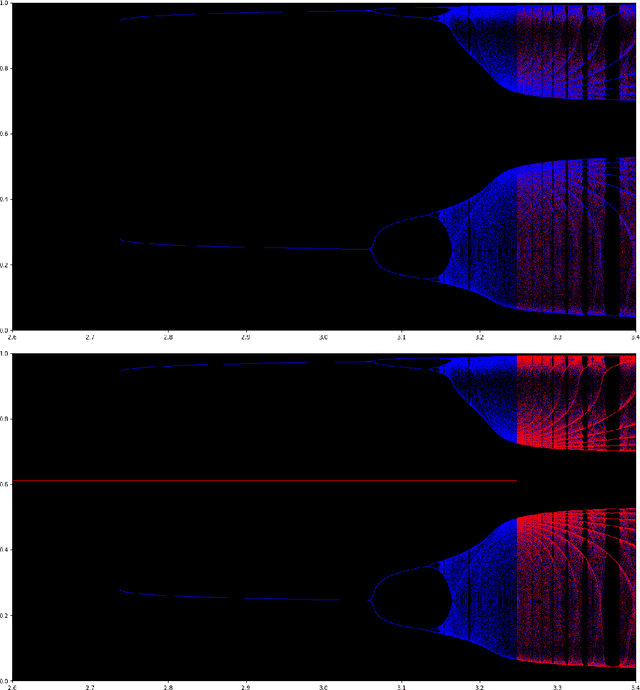
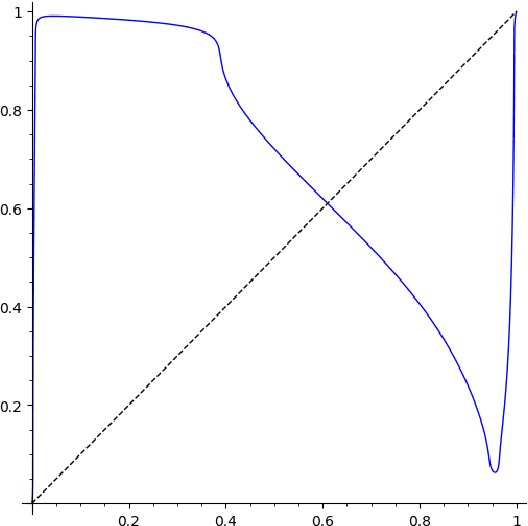
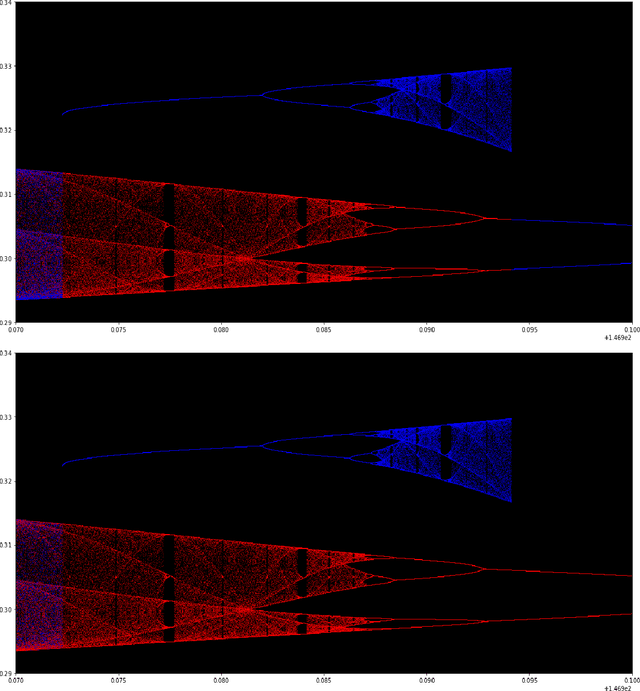
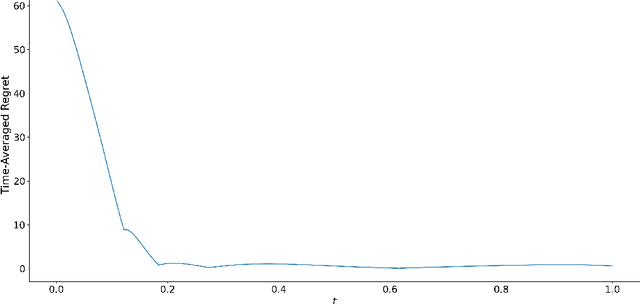
We study the emergence of chaotic behavior of Follow-the-Regularized Leader (FoReL) dynamics in games. We focus on the effects of increasing the population size or the scale of costs in congestion games, and generalize recent results on unstable, chaotic behaviors in the Multiplicative Weights Update dynamics to a much larger class of FoReL dynamics. We establish that, even in simple linear non-atomic congestion games with two parallel links and any fixed learning rate, unless the game is fully symmetric, increasing the population size or the scale of costs causes learning dynamics to become unstable and eventually chaotic, in the sense of Li-Yorke and positive topological entropy. Furthermore, we show the existence of novel non-standard phenomena such as the coexistence of stable Nash equilibria and chaos in the same game. We also observe the simultaneous creation of a chaotic attractor as another chaotic attractor gets destroyed. Lastly, although FoReL dynamics can be strange and non-equilibrating, we prove that the time average still converges to an exact equilibrium for any choice of learning rate and any scale of costs.
Solving Min-Max Optimization with Hidden Structure via Gradient Descent Ascent
Jan 13, 2021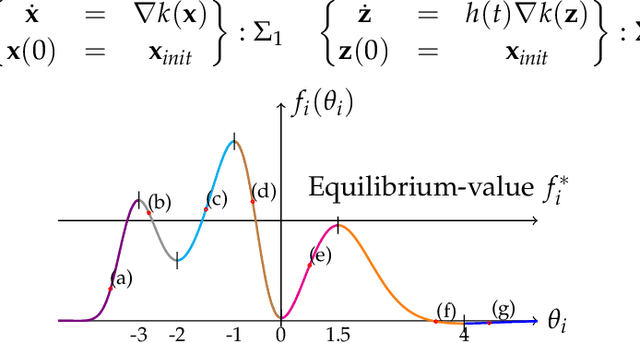
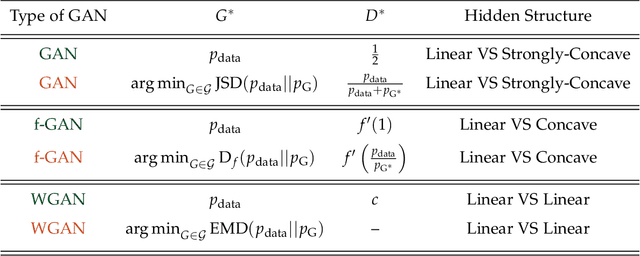
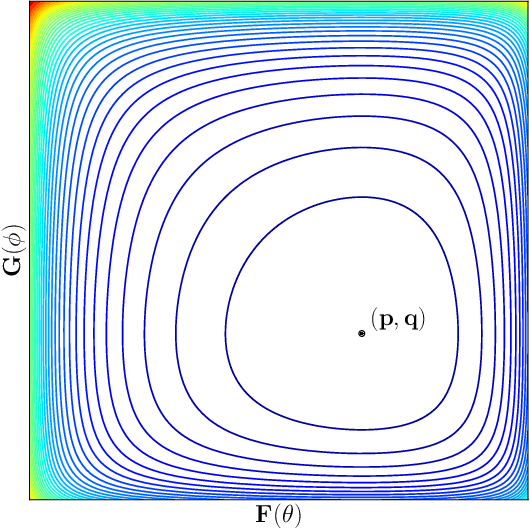
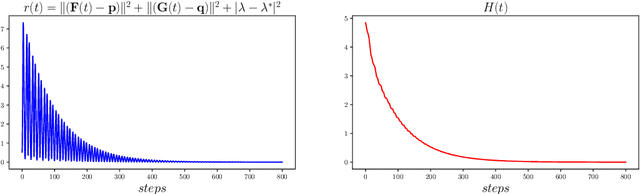
Many recent AI architectures are inspired by zero-sum games, however, the behavior of their dynamics is still not well understood. Inspired by this, we study standard gradient descent ascent (GDA) dynamics in a specific class of non-convex non-concave zero-sum games, that we call hidden zero-sum games. In this class, players control the inputs of smooth but possibly non-linear functions whose outputs are being applied as inputs to a convex-concave game. Unlike general zero-sum games, these games have a well-defined notion of solution; outcomes that implement the von-Neumann equilibrium of the "hidden" convex-concave game. We prove that if the hidden game is strictly convex-concave then vanilla GDA converges not merely to local Nash, but typically to the von-Neumann solution. If the game lacks strict convexity properties, GDA may fail to converge to any equilibrium, however, by applying standard regularization techniques we can prove convergence to a von-Neumann solution of a slightly perturbed zero-sum game. Our convergence guarantees are non-local, which as far as we know is a first-of-its-kind type of result in non-convex non-concave games. Finally, we discuss connections of our framework with generative adversarial networks.
Evolutionary Game Theory Squared: Evolving Agents in Endogenously Evolving Zero-Sum Games
Dec 15, 2020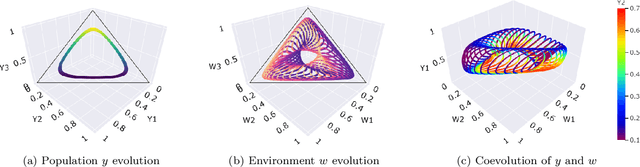
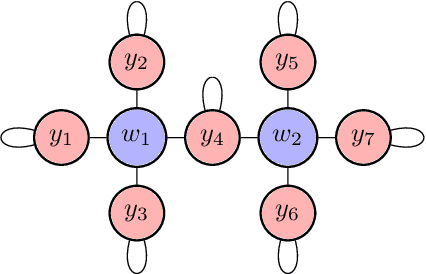
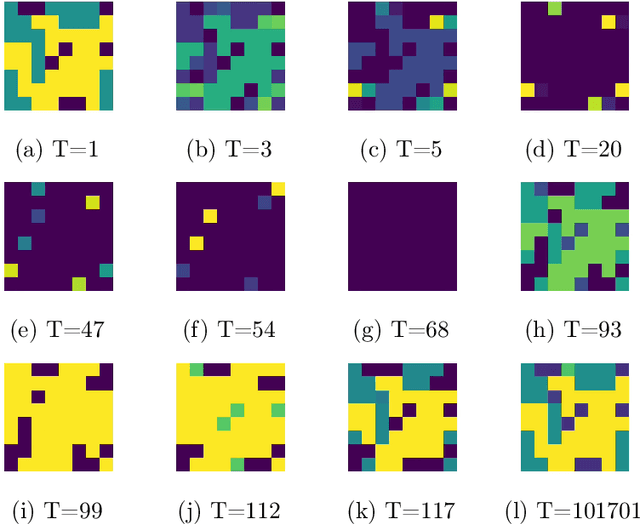
The predominant paradigm in evolutionary game theory and more generally online learning in games is based on a clear distinction between a population of dynamic agents that interact given a fixed, static game. In this paper, we move away from the artificial divide between dynamic agents and static games, to introduce and analyze a large class of competitive settings where both the agents and the games they play evolve strategically over time. We focus on arguably the most archetypal game-theoretic setting -- zero-sum games (as well as network generalizations) -- and the most studied evolutionary learning dynamic -- replicator, the continuous-time analogue of multiplicative weights. Populations of agents compete against each other in a zero-sum competition that itself evolves adversarially to the current population mixture. Remarkably, despite the chaotic coevolution of agents and games, we prove that the system exhibits a number of regularities. First, the system has conservation laws of an information-theoretic flavor that couple the behavior of all agents and games. Secondly, the system is Poincar\'{e} recurrent, with effectively all possible initializations of agents and games lying on recurrent orbits that come arbitrarily close to their initial conditions infinitely often. Thirdly, the time-average agent behavior and utility converge to the Nash equilibrium values of the time-average game. Finally, we provide a polynomial time algorithm to efficiently predict this time-average behavior for any such coevolving network game.
Efficient Online Learning of Optimal Rankings: Dimensionality Reduction via Gradient Descent
Nov 05, 2020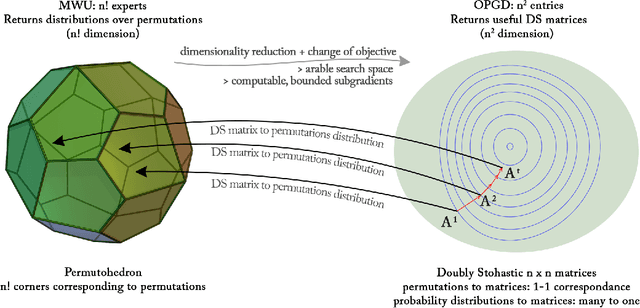
We consider a natural model of online preference aggregation, where sets of preferred items $R_1, R_2, \ldots, R_t$ along with a demand for $k_t$ items in each $R_t$, appear online. Without prior knowledge of $(R_t, k_t)$, the learner maintains a ranking $\pi_t$ aiming that at least $k_t$ items from $R_t$ appear high in $\pi_t$. This is a fundamental problem in preference aggregation with applications to, e.g., ordering product or news items in web pages based on user scrolling and click patterns. The widely studied Generalized Min-Sum-Set-Cover (GMSSC) problem serves as a formal model for the setting above. GMSSC is NP-hard and the standard application of no-regret online learning algorithms is computationally inefficient, because they operate in the space of rankings. In this work, we show how to achieve low regret for GMSSC in polynomial-time. We employ dimensionality reduction from rankings to the space of doubly stochastic matrices, where we apply Online Gradient Descent. A key step is to show how subgradients can be computed efficiently, by solving the dual of a configuration LP. Using oblivious deterministic and randomized rounding schemes, we map doubly stochastic matrices back to rankings with a small loss in the GMSSC objective.
No-regret learning and mixed Nash equilibria: They do not mix
Oct 20, 2020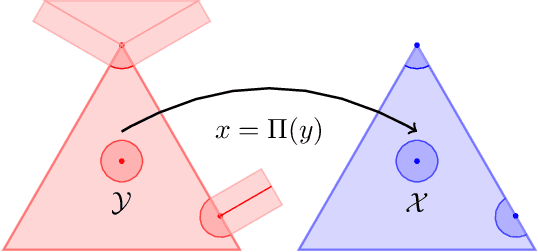

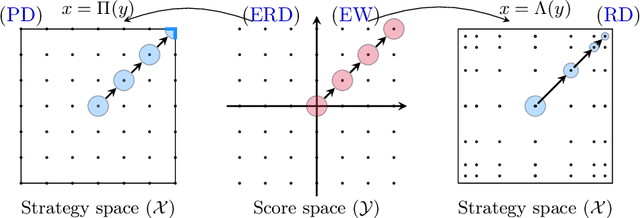
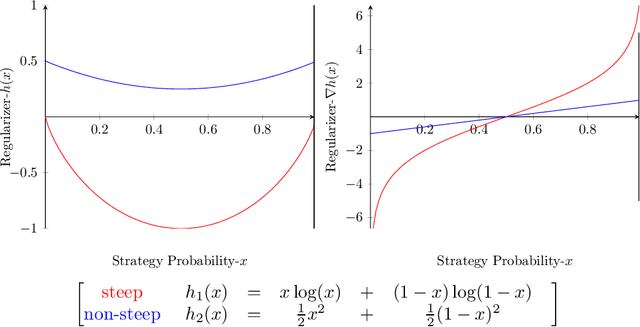
Understanding the behavior of no-regret dynamics in general $N$-player games is a fundamental question in online learning and game theory. A folk result in the field states that, in finite games, the empirical frequency of play under no-regret learning converges to the game's set of coarse correlated equilibria. By contrast, our understanding of how the day-to-day behavior of the dynamics correlates to the game's Nash equilibria is much more limited, and only partial results are known for certain classes of games (such as zero-sum or congestion games). In this paper, we study the dynamics of "follow-the-regularized-leader" (FTRL), arguably the most well-studied class of no-regret dynamics, and we establish a sweeping negative result showing that the notion of mixed Nash equilibrium is antithetical to no-regret learning. Specifically, we show that any Nash equilibrium which is not strict (in that every player has a unique best response) cannot be stable and attracting under the dynamics of FTRL. This result has significant implications for predicting the outcome of a learning process as it shows unequivocally that only strict (and hence, pure) Nash equilibria can emerge as stable limit points thereof.