 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust-Aware Routing for Distributed Generative AI Inference at the Edge
Mar 30, 2026Emerging deployments of Generative AI increasingly execute inference across decentralized and heterogeneous edge devices rather than on a single trusted server. In such environments, a single device failure or misbehavior can disrupt the entire inference process, making traditional best-effort peer-to-peer routing insufficient. Coordinating distributed generative inference therefore requires mechanisms that explicitly account for reliability, performance variability, and trust among participating peers. In this paper, we present G-TRAC, a trust-aware coordination framework that integrates algorithmic path selection with system-level protocol design to ensure robust distributed inference. First, we formulate the routing problem as a \textit{Risk-Bounded Shortest Path} computation and introduce a polynomial-time solution that combines trust-floor pruning with Dijkstra's search, achieving sub-millisecond median routing latency at practical edge scales, and remaining below 10 ms at larger scales. Second, to operationally support the routing logic in dynamic environments, the framework employs a \textit{Hybrid Trust Architecture} that maintains global reputation state at stable anchors while disseminating lightweight updates to edge peers via background synchronization. Experimental evaluation on a heterogeneous testbed of commodity devices demonstrates that G-TRAC significantly improves inference completion rates, effectively isolates unreliable peers, and sustains robust execution even under node failures and network partitions.
Speculative Policy Orchestration: A Latency-Resilient Framework for Cloud-Robotic Manipulation
Mar 19, 2026Cloud robotics enables robots to offload high-dimensional motion planning and reasoning to remote servers. However, for continuous manipulation tasks requiring high-frequency control, network latency and jitter can severely destabilize the system, causing command starvation and unsafe physical execution. To address this, we propose Speculative Policy Orchestration (SPO), a latency-resilient cloud-edge framework. SPO utilizes a cloud-hosted world model to pre-compute and stream future kinematic waypoints to a local edge buffer, decoupling execution frequency from network round-trip time. To mitigate unsafe execution caused by predictive drift, the edge node employs an $ε$-tube verifier that strictly bounds kinematic execution errors. The framework is coupled with an Adaptive Horizon Scaling mechanism that dynamically expands or shrinks the speculative pre-fetch depth based on real-time tracking error. We evaluate SPO on continuous RLBench manipulation tasks under emulated network delays. Results show that even when deployed with learned models of modest accuracy, SPO reduces network-induced idle time by over 60% compared to blocking remote inference. Furthermore, SPO discards approximately 60% fewer cloud predictions than static caching baselines. Ultimately, SPO enables fluid, real-time cloud-robotic control while maintaining bounded physical safety.
Semantic Search At LinkedIn
Feb 07, 2026Semantic search with large language models (LLMs) enables retrieval by meaning rather than keyword overlap, but scaling it requires major inference efficiency advances. We present LinkedIn's LLM-based semantic search framework for AI Job Search and AI People Search, combining an LLM relevance judge, embedding-based retrieval, and a compact Small Language Model trained via multi-teacher distillation to jointly optimize relevance and engagement. A prefill-oriented inference architecture co-designed with model pruning, context compression, and text-embedding hybrid interactions boosts ranking throughput by over 75x under a fixed latency constraint while preserving near-teacher-level NDCG, enabling one of the first production LLM-based ranking systems with efficiency comparable to traditional approaches and delivering significant gains in quality and user engagement.
Federated Learning for Large-Scale Cloud Robotic Manipulation: Opportunities and Challenges
Jul 23, 2025Federated Learning (FL) is an emerging distributed machine learning paradigm, where the collaborative training of a model involves dynamic participation of devices to achieve broad objectives. In contrast, classical machine learning (ML) typically requires data to be located on-premises for training, whereas FL leverages numerous user devices to train a shared global model without the need to share private data. Current robotic manipulation tasks are constrained by the individual capabilities and speed of robots due to limited low-latency computing resources. Consequently, the concept of cloud robotics has emerged, allowing robotic applications to harness the flexibility and reliability of computing resources, effectively alleviating their computational demands across the cloud-edge continuum. Undoubtedly, within this distributed computing context, as exemplified in cloud robotic manipulation scenarios, FL offers manifold advantages while also presenting several challenges and opportunities. In this paper, we present fundamental concepts of FL and their connection to cloud robotic manipulation. Additionally, we envision the opportunities and challenges associated with realizing efficient and reliable cloud robotic manipulation at scale through FL, where researchers adopt to design and verify FL models in either centralized or decentralized settings.
Where Classification Fails, Interpretation Rises
Dec 02, 2017
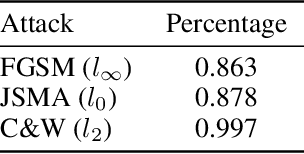
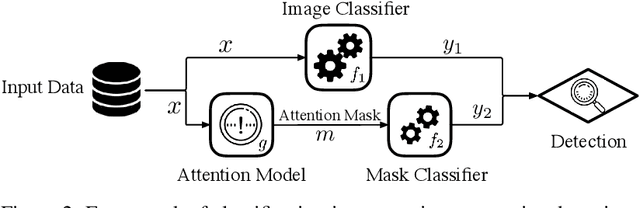

An intriguing property of deep neural networks is their inherent vulnerability to adversarial inputs, which significantly hinders their application in security-critical domains. Most existing detection methods attempt to use carefully engineered patterns to distinguish adversarial inputs from their genuine counterparts, which however can often be circumvented by adaptive adversaries. In this work, we take a completely different route by leveraging the definition of adversarial inputs: while deceiving for deep neural networks, they are barely discernible for human visions. Building upon recent advances in interpretable models, we construct a new detection framework that contrasts an input's interpretation against its classification. We validate the efficacy of this framework through extensive experiments using benchmark datasets and attacks. We believe that this work opens a new direction for designing adversarial input detection methods.