 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Monotone Energy-Aware Information Gathering for Heterogeneous Robot Teams
Jan 26, 2021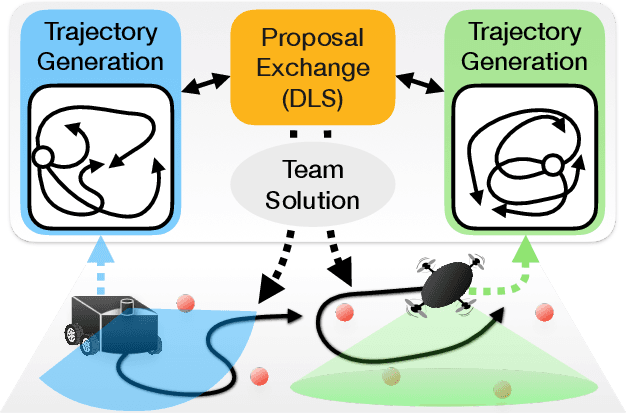
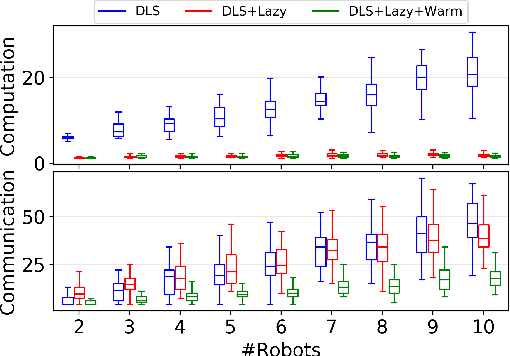
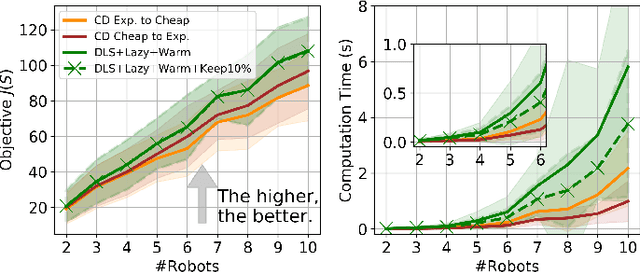
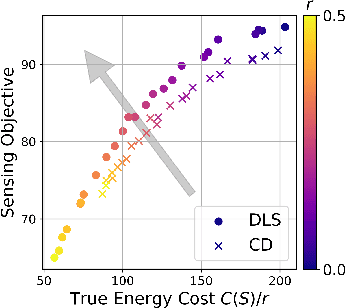
This paper considers the problem of planning trajectories for a team of sensor-equipped robots to reduce uncertainty about a dynamical process. Optimizing the trade-off between information gain and energy cost (e.g., control effort, energy expenditure, distance travelled) is desirable but leads to a non-monotone objective function in the set of robot trajectories. Therefore, common multi-robot planning algorithms based on techniques such as coordinate descent lose their performance guarantees. Methods based on local search provide performance guarantees for optimizing a non-monotone submodular function, but require access to all robots' trajectories, making it not suitable for distributed execution. This work proposes a distributed planning approach based on local search, and shows how to reduce its computation and communication requirements without sacrificing algorithm performance. We demonstrate the efficacy of our proposed method by coordinating robot teams composed of both ground and aerial vehicles with different sensing and control profiles, and evaluate the algorithm's performance in two target tracking scenarios. Our results show up to 60% communication reduction and 80-92% computation reduction on average when coordinating up to 10 robots, while outperforming the coordinate descent based algorithm in achieving a desirable trade-off between sensing and energy expenditure.
Is the brain macroscopically linear? A system identification of resting state dynamics
Dec 22, 2020A central challenge in the computational modeling of neural dynamics is the trade-off between accuracy and simplicity. At the level of individual neurons, nonlinear dynamics are both experimentally established and essential for neuronal functioning. An implicit assumption has thus formed that an accurate computational model of whole-brain dynamics must also be highly nonlinear, whereas linear models may provide a first-order approximation. Here, we provide a rigorous and data-driven investigation of this hypothesis at the level of whole-brain blood-oxygen-level-dependent (BOLD) and macroscopic field potential dynamics by leveraging the theory of system identification. Using functional MRI (fMRI) and intracranial EEG (iEEG), we model the resting state activity of 700 subjects in the Human Connectome Project (HCP) and 122 subjects from the Restoring Active Memory (RAM) project using state-of-the-art linear and nonlinear model families. We assess relative model fit using predictive power, computational complexity, and the extent of residual dynamics unexplained by the model. Contrary to our expectations, linear auto-regressive models achieve the best measures across all three metrics, eliminating the trade-off between accuracy and simplicity. To understand and explain this linearity, we highlight four properties of macroscopic neurodynamics which can counteract or mask microscopic nonlinear dynamics: averaging over space, averaging over time, observation noise, and limited data samples. Whereas the latter two are technological limitations and can improve in the future, the former two are inherent to aggregated macroscopic brain activity. Our results, together with the unparalleled interpretability of linear models, can greatly facilitate our understanding of macroscopic neural dynamics and the principled design of model-based interventions for the treatment of neuropsychiatric disorders.
Sensor-Based Temporal Logic Planning in Uncertain Semantic Maps
Dec 18, 2020
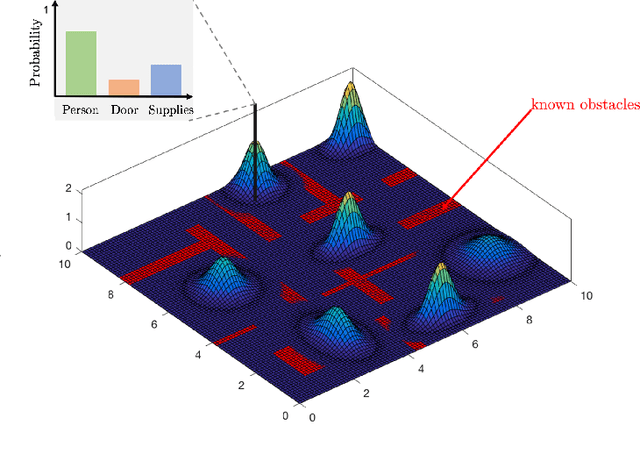
This paper addresses a multi-robot mission planning problem in uncertain semantic environments. The environment is modeled by static labeled landmarks with uncertain positions and classes giving rise to an uncertain semantic map generated by semantic SLAM algorithms. Our goal is to design control policies for sensing robots so that they can accomplish complex collaborative high level tasks captured by global temporal logic specifications. To account for environmental and sensing uncertainty, we extend Linear Temporal Logic (LTL) by including sensor-based predicates allowing us to incorporate uncertainty and probabilistic satisfaction requirements directly into the task specification. The sensor-based LTL planning problem gives rise to an optimal control problem, solved by a novel sampling-based algorithm, that generates open-loop control policies that can be updated online to adapt to the map that is continuously learned by existing semantic SLAM methods. We provide extensive experiments that corroborate the theoretical analysis and show that the proposed algorithm can address large-scale planning tasks in the presence of uncertainty.
Reactive Temporal Logic Planning for Multiple Robots in Unknown Occupancy Grid Maps
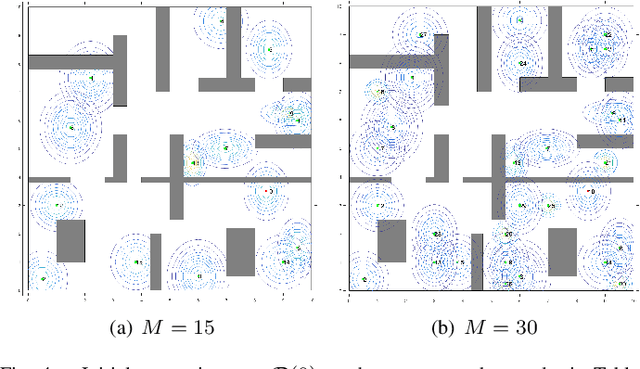
Dec 14, 2020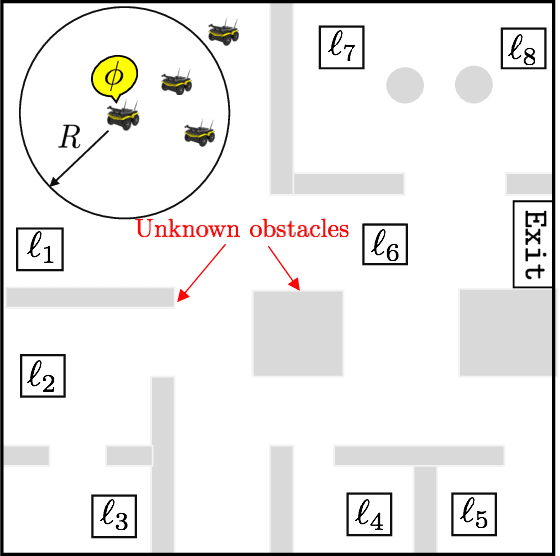
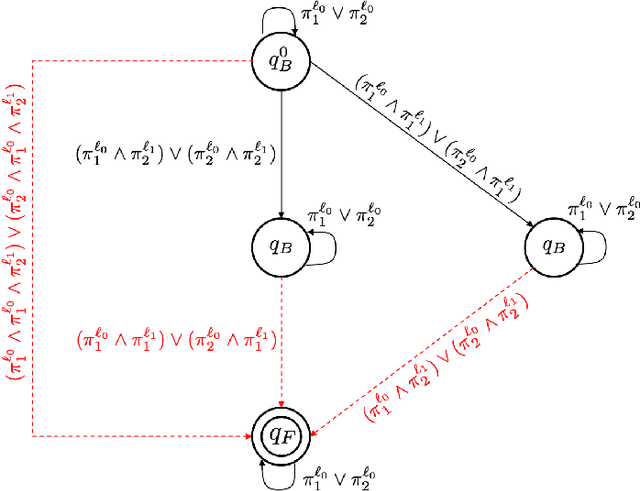
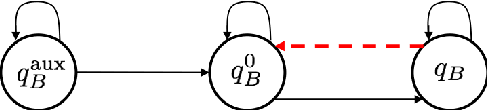
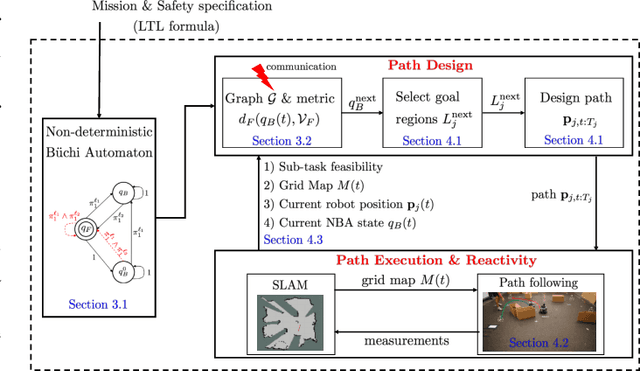
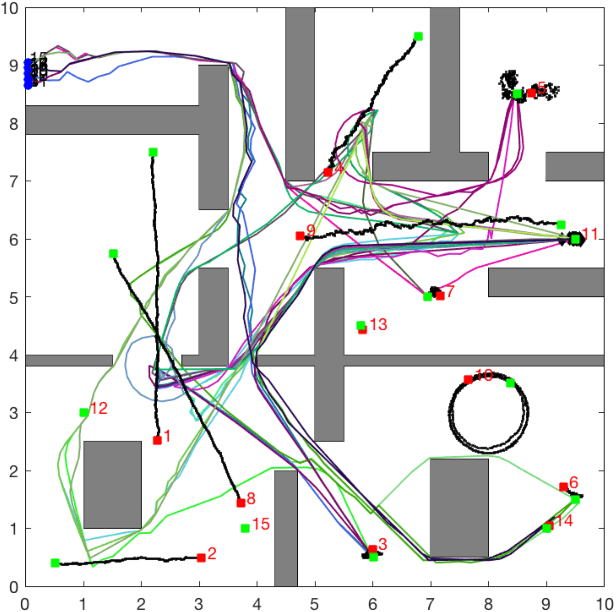
This paper proposes a new reactive temporal logic planning algorithm for multiple robots that operate in environments with unknown geometry modeled using occupancy grid maps. The robots are equipped with individual sensors that allow them to continuously learn a grid map of the unknown environment using existing Simultaneous Localization and Mapping (SLAM) methods. The goal of the robots is to accomplish complex collaborative tasks, captured by global Linear Temporal Logic (LTL) formulas. The majority of existing LTL planning approaches rely on discrete abstractions of the robot dynamics operating in known environments and, as a result, they cannot be applied to the more realistic scenarios where the environment is initially unknown. In this paper, we address this novel challenge by proposing the first reactive, abstraction-free, and distributed LTL planning algorithm that can be applied for complex mission planning of multiple robots operating in unknown environments. The proposed algorithm is reactive, i.e., planning is adapting to the updated environmental map and abstraction-free as it does not rely on designing abstractions of the robot dynamics. Also, our algorithm is distributed in the sense that the global LTL task is decomposed into single-agent reachability problems constructed online based on the continuously learned map. The proposed algorithm is complete under mild assumptions on the structure of the environment and the sensor models. We provide extensive numerical simulations and hardware experiments that illustrate the theoretical analysis and show that the proposed algorithm can address complex planning tasks for large-scale multi-robot systems in unknown environments.
Scalable Reinforcement Learning Policies for Multi-Agent Control
Nov 16, 2020
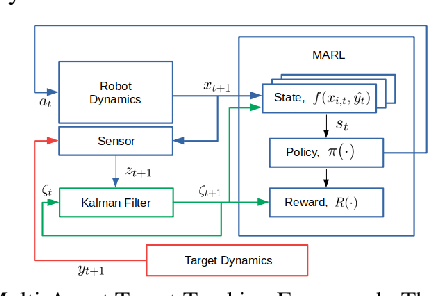
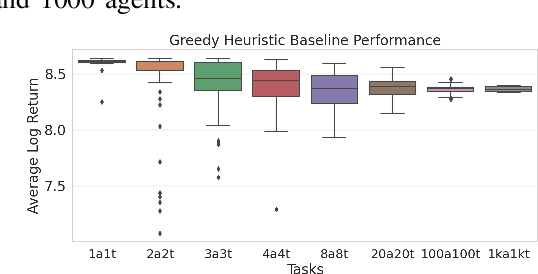
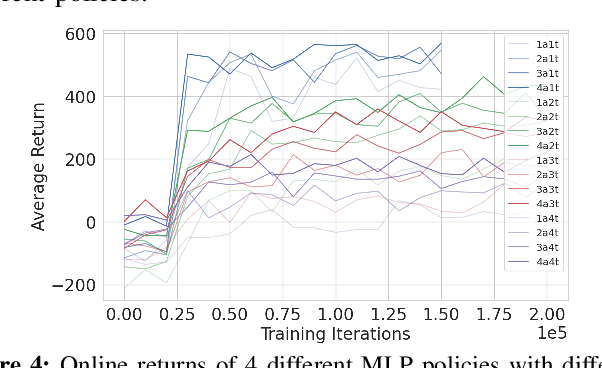
This paper develops a stochastic Multi-Agent Reinforcement Learning (MARL) method to learn control policies that can handle an arbitrary number of external agents; our policies can be executed for tasks consisting of 1000 pursuers and 1000 evaders. We model pursuers as agents with limited on-board sensing and formulate the problem as a decentralized, partially-observable Markov Decision Process. An attention mechanism is used to build a permutation and input-size invariant embedding of the observations for learning a stochastic policy and value function using techniques in entropy-regularized off-policy methods. Simulation experiments on a large number of problems show that our control policies are dramatically scalable and display cooperative behavior in spite of being executed in a decentralized fashion; our methods offer a simple solution to classical multi-agent problems using techniques in reinforcement learning.
Technical Report: Reactive Planning for Mobile Manipulation Tasks in Unexplored Semantic Environments
Nov 01, 2020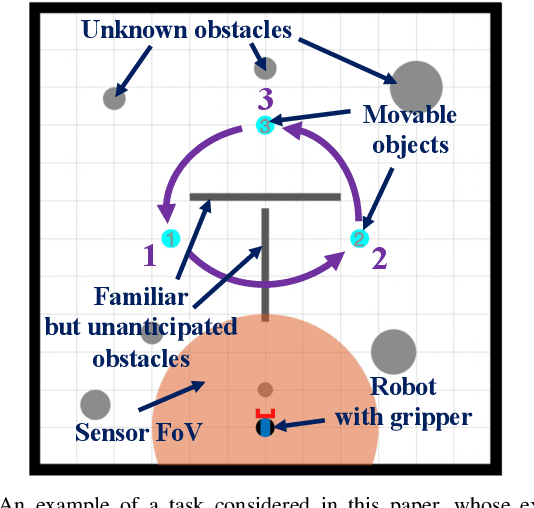
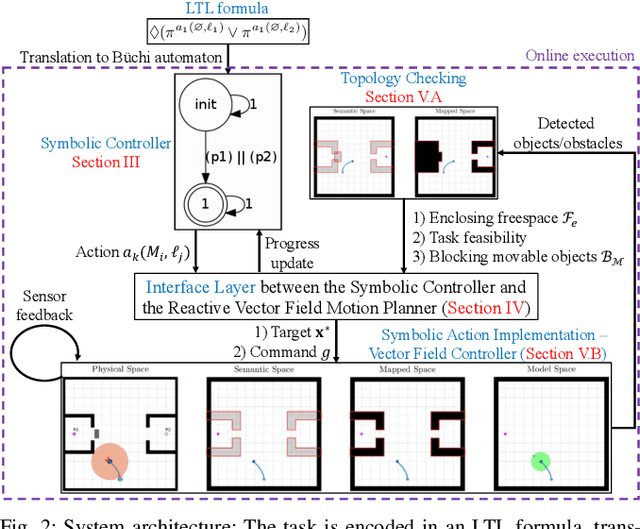
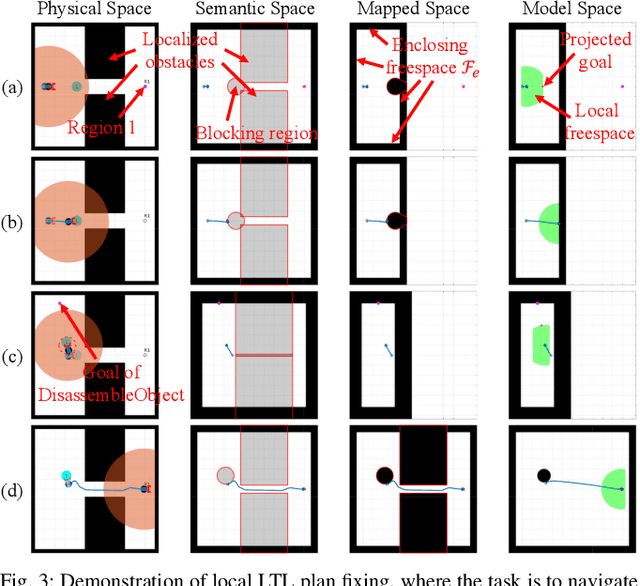
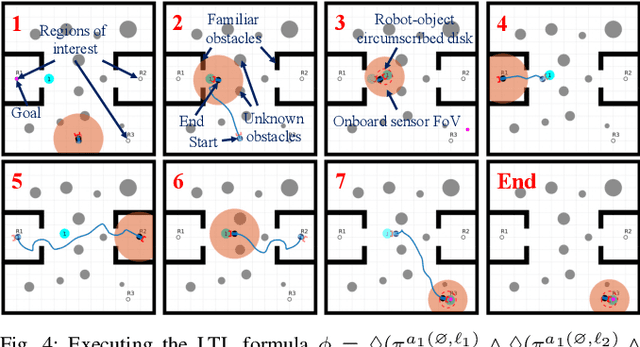
Complex manipulation tasks, such as rearrangement planning of numerous objects, are combinatorially hard problems. Existing algorithms either do not scale well or assume a great deal of prior knowledge about the environment, and few offer any rigorous guarantees. In this paper, we propose a novel hybrid control architecture for achieving such tasks with mobile manipulators. On the discrete side, we enrich a temporal logic specification with mobile manipulation primitives such as moving to a point, and grasping or moving an object. Such specifications are translated to an automaton representation, which orchestrates the physical grounding of the task to mobility or manipulation controllers. The grounding from the discrete to the continuous reactive controller is online and can respond to the discovery of unknown obstacles or decide to push out of the way movable objects that prohibit task accomplishment. Despite the problem complexity, we prove that, under specific conditions, our architecture enjoys provable completeness on the discrete side, provable termination on the continuous side, and avoids all obstacles in the environment. Simulations illustrate the efficiency of our architecture that can handle tasks of increased complexity while also responding to unknown obstacles or unanticipated adverse configurations.
Control Barrier Functions for Unknown Nonlinear Systems using Gaussian Processes
Oct 12, 2020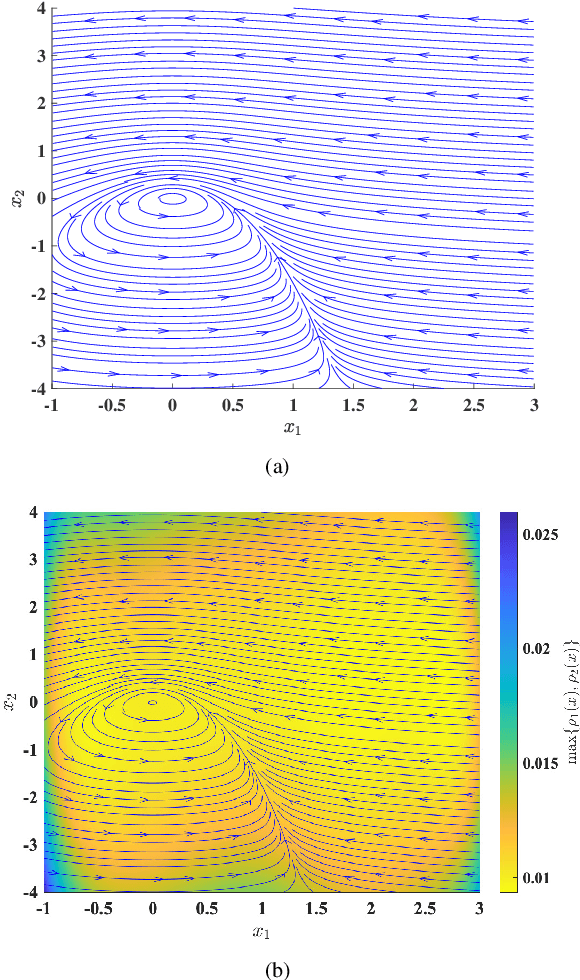
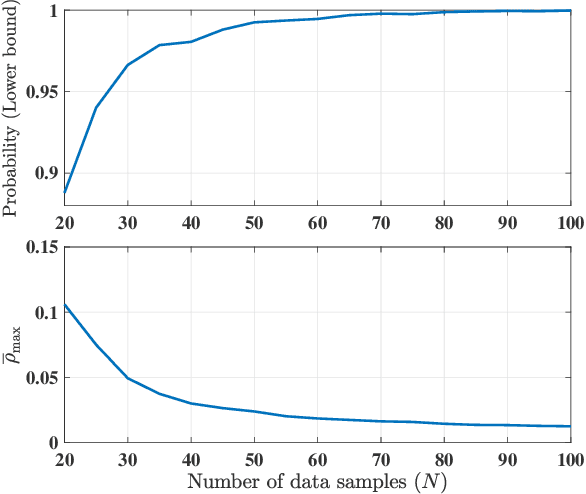
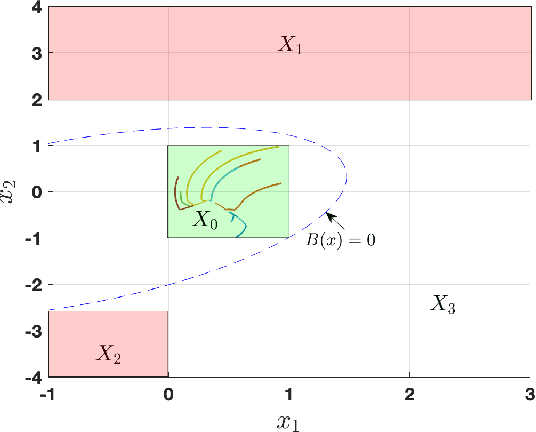
This paper focuses on the controller synthesis for unknown, nonlinear systems while ensuring safety constraints. Our approach consists of two steps, a learning step that uses Gaussian processes and a controller synthesis step that is based on control barrier functions. In the learning step, we use a data-driven approach utilizing Gaussian processes to learn the unknown control affine nonlinear dynamics together with a statistical bound on the accuracy of the learned model. In the second controller synthesis steps, we develop a systematic approach to compute control barrier functions that explicitly take into consideration the uncertainty of the learned model. The control barrier function not only results in a safe controller by construction but also provides a rigorous lower bound on the probability of satisfaction of the safety specification. Finally, we illustrate the effectiveness of the proposed results by synthesizing a safety controller for a jet engine example.
Zeroth-order Deterministic Policy Gradient
Jul 11, 2020
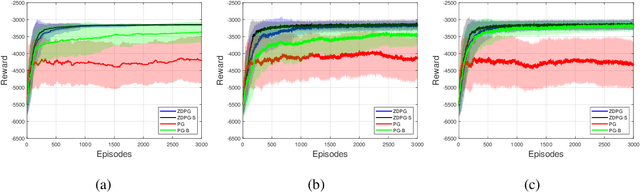
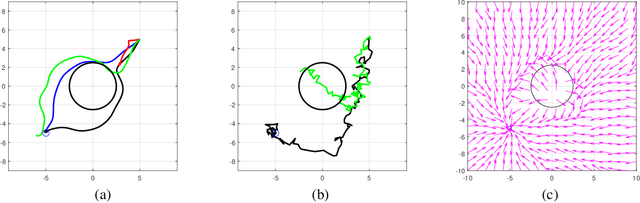
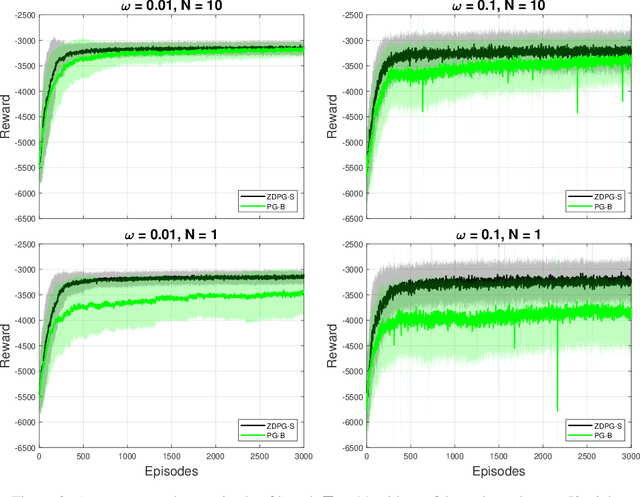
Deterministic Policy Gradient (DPG) removes a level of randomness from standard randomized-action Policy Gradient (PG), and demonstrates substantial empirical success for tackling complex dynamic problems involving Markov decision processes. At the same time, though, DPG loses its ability to learn in a model-free (i.e., actor-only) fashion, frequently necessitating the use of critics in order to obtain consistent estimates of the associated policy-reward gradient. In this work, we introduce Zeroth-order Deterministic Policy Gradient (ZDPG), which approximates policy-reward gradients via two-point stochastic evaluations of the $Q$-function, constructed by properly designed low-dimensional action-space perturbations. Exploiting the idea of random horizon rollouts for obtaining unbiased estimates of the $Q$-function, ZDPG lifts the dependence on critics and restores true model-free policy learning, while enjoying built-in and provable algorithmic stability. Additionally, we present new finite sample complexity bounds for ZDPG, which improve upon existing results by up to two orders of magnitude. Our findings are supported by several numerical experiments, which showcase the effectiveness of ZDPG in a practical setting, and its advantages over both PG and Baseline PG.
Learning to Track Dynamic Targets in Partially Known Environments
Jun 17, 2020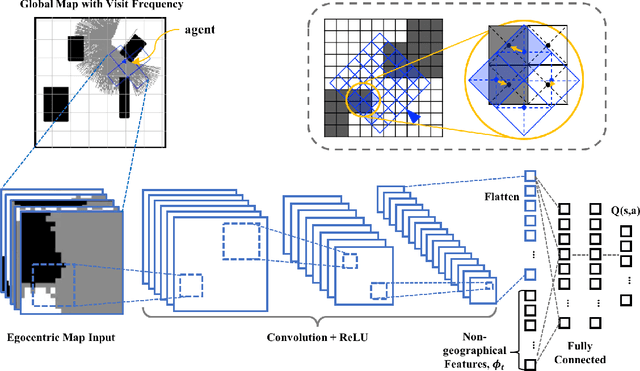
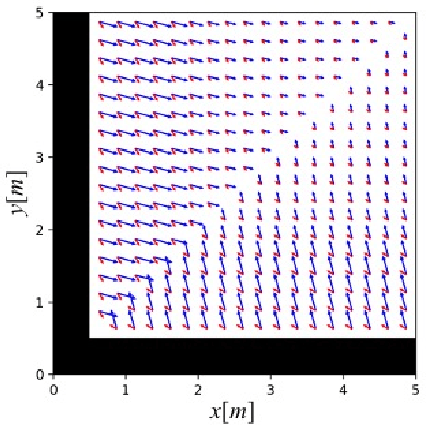

We solve active target tracking, one of the essential tasks in autonomous systems, using a deep reinforcement learning (RL) approach. In this problem, an autonomous agent is tasked with acquiring information about targets of interests using its onboard sensors. The classical challenges in this problem are system model dependence and the difficulty of computing information-theoretic cost functions for a long planning horizon. RL provides solutions for these challenges as the length of its effective planning horizon does not affect the computational complexity, and it drops the strong dependency of an algorithm on system models. In particular, we introduce Active Tracking Target Network (ATTN), a unified RL policy that is capable of solving major sub-tasks of active target tracking -- in-sight tracking, navigation, and exploration. The policy shows robust behavior for tracking agile and anomalous targets with a partially known target model. Additionally, the same policy is able to navigate in obstacle environments to reach distant targets as well as explore the environment when targets are positioned in unexpected locations.
Model-Based Robust Deep Learning
May 20, 2020
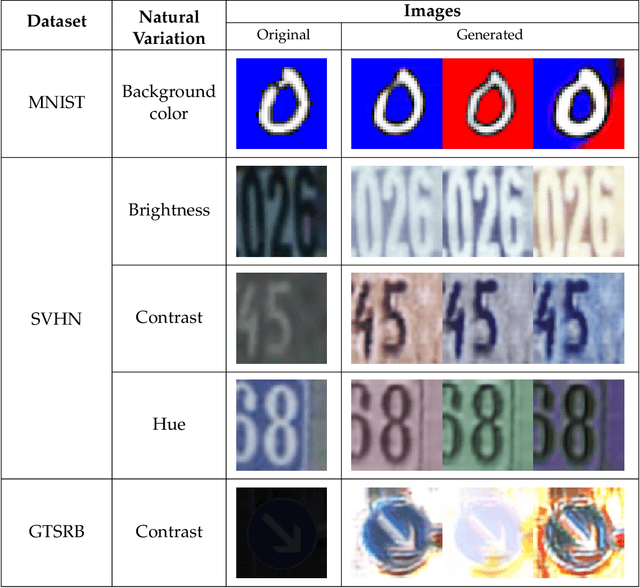
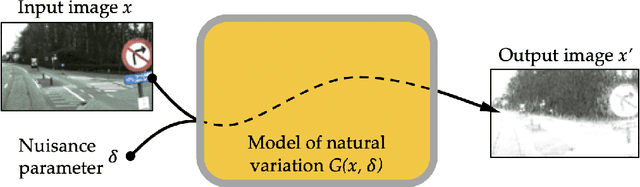
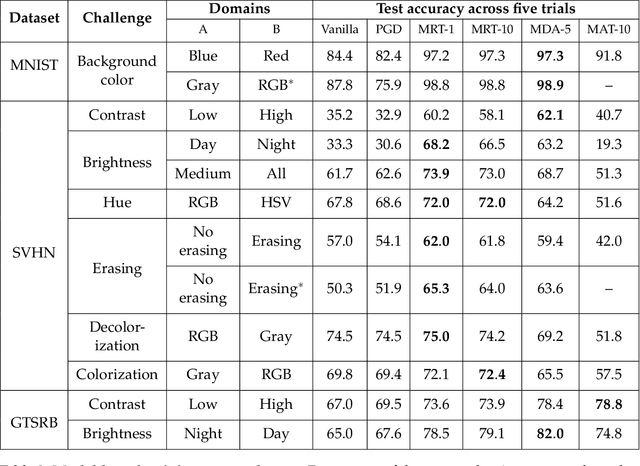
While deep learning has resulted in major breakthroughs in many application domains, the frameworks commonly used in deep learning remain fragile to artificially-crafted and imperceptible changes in the data. In response to this fragility, adversarial training has emerged as a principled approach for enhancing the robustness of deep learning with respect to norm-bounded perturbations. However, there are other sources of fragility for deep learning that are arguably more common and less thoroughly studied. Indeed, natural variation such as lighting or weather conditions can significantly degrade the accuracy of trained neural networks, proving that such natural variation presents a significant challenge for deep learning. In this paper, we propose a paradigm shift from perturbation-based adversarial robustness toward {\em model-based robust deep learning}. Our objective is to provide general training algorithms that can be used to train deep neural networks to be robust against natural variation in data. Critical to our paradigm is first obtaining a \emph{model of natural variation} which can be used to vary data over a range of natural conditions. Such models may be either known a priori or else learned from data. In the latter case, we show that deep generative models can be used to learn models of natural variation that are consistent with realistic conditions. We then exploit such models in three novel model-based robust training algorithms in order to enhance the robustness of deep learning with respect to the given model. Our extensive experiments show that across a variety of naturally-occurring conditions and across various datasets, deep neural networks trained with our model-based algorithms significantly outperform both standard deep learning algorithms as well as norm-bounded robust deep learning algorithms.