 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWS-IMUBench: Can Weakly Supervised Methods from Audio, Image, and Video Be Adapted for IMU-based Temporal Action Localization?
Feb 02, 2026IMU-based Human Activity Recognition (HAR) has enabled a wide range of ubiquitous computing applications, yet its dominant clip classification paradigm cannot capture the rich temporal structure of real-world behaviors. This motivates a shift toward IMU Temporal Action Localization (IMU-TAL), which predicts both action categories and their start/end times in continuous streams. However, current progress is strongly bottlenecked by the need for dense, frame-level boundary annotations, which are costly and difficult to scale. To address this bottleneck, we introduce WS-IMUBench, a systematic benchmark study of weakly supervised IMU-TAL (WS-IMU-TAL) under only sequence-level labels. Rather than proposing a new localization algorithm, we evaluate how well established weakly supervised localization paradigms from audio, image, and video transfer to IMU-TAL under only sequence-level labels. We benchmark seven representative weakly supervised methods on seven public IMU datasets, resulting in over 3,540 model training runs and 7,080 inference evaluations. Guided by three research questions on transferability, effectiveness, and insights, our findings show that (i) transfer is modality-dependent, with temporal-domain methods generally more stable than image-derived proposal-based approaches; (ii) weak supervision can be competitive on favorable datasets (e.g., with longer actions and higher-dimensional sensing); and (iii) dominant failure modes arise from short actions, temporal ambiguity, and proposal quality. Finally, we outline concrete directions for advancing WS-IMU-TAL (e.g., IMU-specific proposal generation, boundary-aware objectives, and stronger temporal reasoning). Beyond individual results, WS-IMUBench establishes a reproducible benchmarking template, datasets, protocols, and analyses, to accelerate community-wide progress toward scalable WS-IMU-TAL.
MobiDiary: Autoregressive Action Captioning with Wearable Devices and Wireless Signals
Jan 13, 2026Human Activity Recognition (HAR) in smart homes is critical for health monitoring and assistive living. While vision-based systems are common, they face privacy concerns and environmental limitations (e.g., occlusion). In this work, we present MobiDiary, a framework that generates natural language descriptions of daily activities directly from heterogeneous physical signals (specifically IMU and Wi-Fi). Unlike conventional approaches that restrict outputs to pre-defined labels, MobiDiary produces expressive, human-readable summaries. To bridge the semantic gap between continuous, noisy physical signals and discrete linguistic descriptions, we propose a unified sensor encoder. Instead of relying on modality-specific engineering, we exploit the shared inductive biases of motion-induced signals--where both inertial and wireless data reflect underlying kinematic dynamics. Specifically, our encoder utilizes a patch-based mechanism to capture local temporal correlations and integrates heterogeneous placement embedding to unify spatial contexts across different sensors. These unified signal tokens are then fed into a Transformer-based decoder, which employs an autoregressive mechanism to generate coherent action descriptions word-by-word. We comprehensively evaluate our approach on multiple public benchmarks (XRF V2, UWash, and WiFiTAD). Experimental results demonstrate that MobiDiary effectively generalizes across modalities, achieving state-of-the-art performance on captioning metrics (e.g., BLEU@4, CIDEr, RMC) and outperforming specialized baselines in continuous action understanding.
SlideChain: Semantic Provenance for Lecture Understanding via Blockchain Registration
Dec 25, 2025Modern vision--language models (VLMs) are increasingly used to interpret and generate educational content, yet their semantic outputs remain challenging to verify, reproduce, and audit over time. Inconsistencies across model families, inference settings, and computing environments undermine the reliability of AI-generated instructional material, particularly in high-stakes and quantitative STEM domains. This work introduces SlideChain, a blockchain-backed provenance framework designed to provide verifiable integrity for multimodal semantic extraction at scale. Using the SlideChain Slides Dataset-a curated corpus of 1,117 medical imaging lecture slides from a university course-we extract concepts and relational triples from four state-of-the-art VLMs and construct structured provenance records for every slide. SlideChain anchors cryptographic hashes of these records on a local EVM (Ethereum Virtual Machine)-compatible blockchain, providing tamper-evident auditability and persistent semantic baselines. Through the first systematic analysis of semantic disagreement, cross-model similarity, and lecture-level variability in multimodal educational content, we reveal pronounced cross-model discrepancies, including low concept overlap and near-zero agreement in relational triples on many slides. We further evaluate gas usage, throughput, and scalability under simulated deployment conditions, and demonstrate perfect tamper detection along with deterministic reproducibility across independent extraction runs. Together, these results show that SlideChain provides a practical and scalable step toward trustworthy, verifiable multimodal educational pipelines, supporting long-term auditability, reproducibility, and integrity for AI-assisted instructional systems.
ALIVE: An Avatar-Lecture Interactive Video Engine with Content-Aware Retrieval for Real-Time Interaction
Dec 24, 2025Traditional lecture videos offer flexibility but lack mechanisms for real-time clarification, forcing learners to search externally when confusion arises. Recent advances in large language models and neural avatars provide new opportunities for interactive learning, yet existing systems typically lack lecture awareness, rely on cloud-based services, or fail to integrate retrieval and avatar-delivered explanations in a unified, privacy-preserving pipeline. We present ALIVE, an Avatar-Lecture Interactive Video Engine that transforms passive lecture viewing into a dynamic, real-time learning experience. ALIVE operates fully on local hardware and integrates (1) Avatar-delivered lecture generated through ASR transcription, LLM refinement, and neural talking-head synthesis; (2) A content-aware retrieval mechanism that combines semantic similarity with timestamp alignment to surface contextually relevant lecture segments; and (3) Real-time multimodal interaction, enabling students to pause the lecture, ask questions through text or voice, and receive grounded explanations either as text or as avatar-delivered responses. To maintain responsiveness, ALIVE employs lightweight embedding models, FAISS-based retrieval, and segmented avatar synthesis with progressive preloading. We demonstrate the system on a complete medical imaging course, evaluate its retrieval accuracy, latency characteristics, and user experience, and show that ALIVE provides accurate, content-aware, and engaging real-time support. ALIVE illustrates how multimodal AI-when combined with content-aware retrieval and local deployment-can significantly enhance the pedagogical value of recorded lectures, offering an extensible pathway toward next-generation interactive learning environments.
3One2: One-step Regression Plus One-step Diffusion for One-hot Modulation in Dual-path Video Snapshot Compressive Imaging
Dec 19, 2025Video snapshot compressive imaging (SCI) captures dynamic scene sequences through a two-dimensional (2D) snapshot, fundamentally relying on optical modulation for hardware compression and the corresponding software reconstruction. While mainstream video SCI using random binary modulation has demonstrated success, it inevitably results in temporal aliasing during compression. One-hot modulation, activating only one sub-frame per pixel, provides a promising solution for achieving perfect temporal decoupling, thereby alleviating issues associated with aliasing. However, no algorithms currently exist to fully exploit this potential. To bridge this gap, we propose an algorithm specifically designed for one-hot masks. First, leveraging the decoupling properties of one-hot modulation, we transform the reconstruction task into a generative video inpainting problem and introduce a stochastic differential equation (SDE) of the forward process that aligns with the hardware compression process. Next, we identify limitations of the pure diffusion method for video SCI and propose a novel framework that combines one-step regression initialization with one-step diffusion refinement. Furthermore, to mitigate the spatial degradation caused by one-hot modulation, we implement a dual optical path at the hardware level, utilizing complementary information from another path to enhance the inpainted video. To our knowledge, this is the first work integrating diffusion into video SCI reconstruction. Experiments conducted on synthetic datasets and real scenes demonstrate the effectiveness of our method.
X-WIN: Building Chest Radiograph World Model via Predictive Sensing
Nov 18, 2025Chest X-ray radiography (CXR) is an essential medical imaging technique for disease diagnosis. However, as 2D projectional images, CXRs are limited by structural superposition and hence fail to capture 3D anatomies. This limitation makes representation learning and disease diagnosis challenging. To address this challenge, we propose a novel CXR world model named X-WIN, which distills volumetric knowledge from chest computed tomography (CT) by learning to predict its 2D projections in latent space. The core idea is that a world model with internalized knowledge of 3D anatomical structure can predict CXRs under various transformations in 3D space. During projection prediction, we introduce an affinity-guided contrastive alignment loss that leverages mutual similarities to capture rich, correlated information across projections from the same volume. To improve model adaptability, we incorporate real CXRs into training through masked image modeling and employ a domain classifier to encourage statistically similar representations for real and simulated CXRs. Comprehensive experiments show that X-WIN outperforms existing foundation models on diverse downstream tasks using linear probing and few-shot fine-tuning. X-WIN also demonstrates the ability to render 2D projections for reconstructing a 3D CT volume.
N-ReLU: Zero-Mean Stochastic Extension of ReLU
Nov 10, 2025Activation functions are fundamental for enabling nonlinear representations in deep neural networks. However, the standard rectified linear unit (ReLU) often suffers from inactive or "dead" neurons caused by its hard zero cutoff. To address this issue, we introduce N-ReLU (Noise-ReLU), a zero-mean stochastic extension of ReLU that replaces negative activations with Gaussian noise while preserving the same expected output. This expectation-aligned formulation maintains gradient flow in inactive regions and acts as an annealing-style regularizer during training. Experiments on the MNIST dataset using both multilayer perceptron (MLP) and convolutional neural network (CNN) architectures show that N-ReLU achieves accuracy comparable to or slightly exceeding that of ReLU, LeakyReLU, PReLU, GELU, and RReLU at moderate noise levels (sigma = 0.05-0.10), with stable convergence and no dead neurons observed. These results demonstrate that lightweight Gaussian noise injection offers a simple yet effective mechanism to enhance optimization robustness without modifying network structures or introducing additional parameters.
Median2Median: Zero-shot Suppression of Structured Noise in Images
Oct 02, 2025Image denoising is a fundamental problem in computer vision and medical imaging. However, real-world images are often degraded by structured noise with strong anisotropic correlations that existing methods struggle to remove. Most data-driven approaches rely on large datasets with high-quality labels and still suffer from limited generalizability, whereas existing zero-shot methods avoid this limitation but remain effective only for independent and identically distributed (i.i.d.) noise. To address this gap, we propose Median2Median (M2M), a zero-shot denoising framework designed for structured noise. M2M introduces a novel sampling strategy that generates pseudo-independent sub-image pairs from a single noisy input. This strategy leverages directional interpolation and generalized median filtering to adaptively exclude values distorted by structured artifacts. To further enlarge the effective sampling space and eliminate systematic bias, a randomized assignment strategy is employed, ensuring that the sampled sub-image pairs are suitable for Noise2Noise training. In our realistic simulation studies, M2M performs on par with state-of-the-art zero-shot methods under i.i.d. noise, while consistently outperforming them under correlated noise. These findings establish M2M as an efficient, data-free solution for structured noise suppression and mark the first step toward effective zero-shot denoising beyond the strict i.i.d. assumption.
What Matters in LLM-Based Feature Extractor for Recommender? A Systematic Analysis of Prompts, Models, and Adaptation
Sep 18, 2025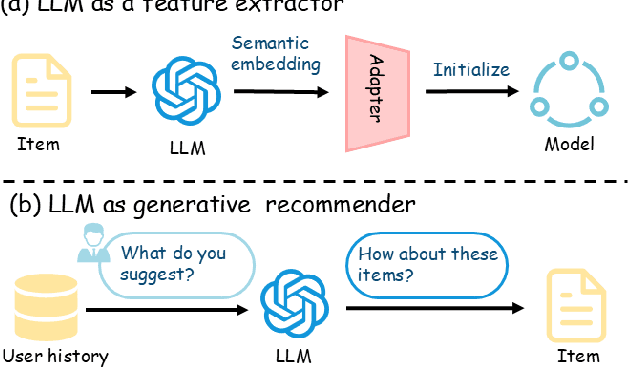

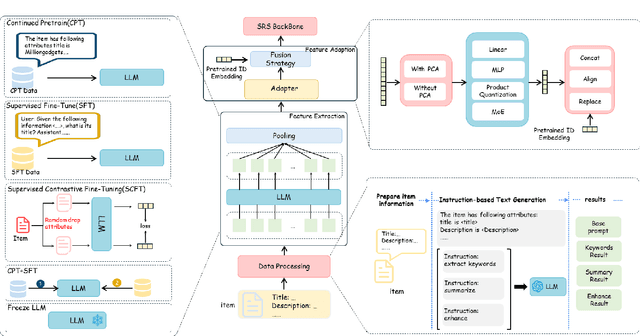

Using Large Language Models (LLMs) to generate semantic features has been demonstrated as a powerful paradigm for enhancing Sequential Recommender Systems (SRS). This typically involves three stages: processing item text, extracting features with LLMs, and adapting them for downstream models. However, existing methods vary widely in prompting, architecture, and adaptation strategies, making it difficult to fairly compare design choices and identify what truly drives performance. In this work, we propose RecXplore, a modular analytical framework that decomposes the LLM-as-feature-extractor pipeline into four modules: data processing, semantic feature extraction, feature adaptation, and sequential modeling. Instead of proposing new techniques, RecXplore revisits and organizes established methods, enabling systematic exploration of each module in isolation. Experiments on four public datasets show that simply combining the best designs from existing techniques without exhaustive search yields up to 18.7% relative improvement in NDCG@5 and 12.7% in HR@5 over strong baselines. These results underscore the utility of modular benchmarking for identifying effective design patterns and promoting standardized research in LLM-enhanced recommendation.
LAMA-Net: A Convergent Network Architecture for Dual-Domain Reconstruction
Jul 30, 2025We propose a learnable variational model that learns the features and leverages complementary information from both image and measurement domains for image reconstruction. In particular, we introduce a learned alternating minimization algorithm (LAMA) from our prior work, which tackles two-block nonconvex and nonsmooth optimization problems by incorporating a residual learning architecture in a proximal alternating framework. In this work, our goal is to provide a complete and rigorous convergence proof of LAMA and show that all accumulation points of a specified subsequence of LAMA must be Clarke stationary points of the problem. LAMA directly yields a highly interpretable neural network architecture called LAMA-Net. Notably, in addition to the results shown in our prior work, we demonstrate that the convergence property of LAMA yields outstanding stability and robustness of LAMA-Net in this work. We also show that the performance of LAMA-Net can be further improved by integrating a properly designed network that generates suitable initials, which we call iLAMA-Net. To evaluate LAMA-Net/iLAMA-Net, we conduct several experiments and compare them with several state-of-the-art methods on popular benchmark datasets for Sparse-View Computed Tomography.
* arXiv admin note: substantial text overlap with arXiv:2410.21111