 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP-MMF: Provider Max-min Fairness Re-ranking in Recommender System
Mar 12, 2023



In this paper, we address the issue of recommending fairly from the aspect of providers, which has become increasingly essential in multistakeholder recommender systems. Existing studies on provider fairness usually focused on designing proportion fairness (PF) metrics that first consider systematic fairness. However, sociological researches show that to make the market more stable, max-min fairness (MMF) is a better metric. The main reason is that MMF aims to improve the utility of the worst ones preferentially, guiding the system to support the providers in weak market positions. When applying MMF to recommender systems, how to balance user preferences and provider fairness in an online recommendation scenario is still a challenging problem. In this paper, we proposed an online re-ranking model named Provider Max-min Fairness Re-ranking (P-MMF) to tackle the problem. Specifically, P-MMF formulates provider fair recommendation as a resource allocation problem, where the exposure slots are considered the resources to be allocated to providers and the max-min fairness is used as the regularizer during the process. We show that the problem can be further represented as a regularized online optimizing problem and solved efficiently in its dual space. During the online re-ranking phase, a momentum gradient descent method is designed to conduct the dynamic re-ranking. Theoretical analysis showed that the regret of P-MMF can be bounded. Experimental results on four public recommender datasets demonstrated that P-MMF can outperformed the state-of-the-art baselines. Experimental results also show that P-MMF can retain small computationally costs on a corpus with the large number of items.
EdgeYOLO: An Edge-Real-Time Object Detector
Feb 15, 2023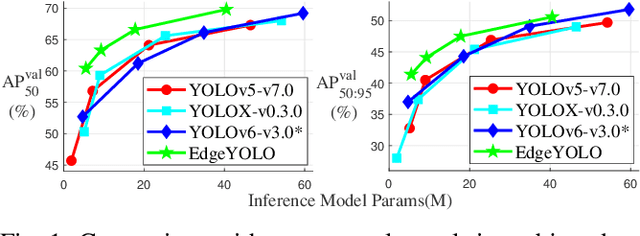
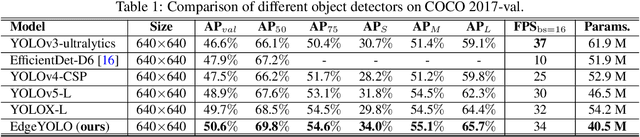

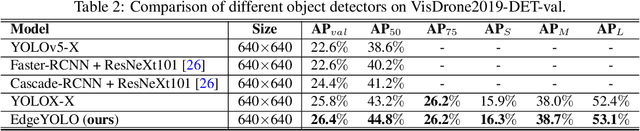
This paper proposes an efficient, low-complexity and anchor-free object detector based on the state-of-the-art YOLO framework, which can be implemented in real time on edge computing platforms. We develop an enhanced data augmentation method to effectively suppress overfitting during training, and design a hybrid random loss function to improve the detection accuracy of small objects. Inspired by FCOS, a lighter and more efficient decoupled head is proposed, and its inference speed can be improved with little loss of precision. Our baseline model can reach the accuracy of 50.6% AP50:95 and 69.8% AP50 in MS COCO2017 dataset, 26.4% AP50:95 and 44.8% AP50 in VisDrone2019-DET dataset, and it meets real-time requirements (FPS>=30) on edge-computing device Nvidia Jetson AGX Xavier. We also designed lighter models with less parameters for edge computing devices with lower computing power, which also show better performances. Our source code, hyper-parameters and model weights are all available at https://github.com/LSH9832/edgeyolo.
Time-attenuating Twin Delayed DDPG Reinforcement Learning for Trajectory Tracking Control of Quadrotors
Feb 13, 2023



Continuous trajectory tracking control of quadrotors is complicated when considering noise from the environment. Due to the difficulty in modeling the environmental dynamics, tracking methodologies based on conventional control theory, such as model predictive control, have limitations on tracking accuracy and response time. We propose a Time-attenuating Twin Delayed DDPG, a model-free algorithm that is robust to noise, to better handle the trajectory tracking task. A deep reinforcement learning framework is constructed, where a time decay strategy is designed to avoid trapping into local optima. The experimental results show that the tracking error is significantly small, and the operation time is one-tenth of that of a traditional algorithm. The OpenAI Mujoco tool is used to verify the proposed algorithm, and the simulation results show that, the proposed method can significantly improve the training efficiency and effectively improve the accuracy and convergence stability.
Minimum Error Entropy Rauch-Tung-Striebel Smoother
Jan 14, 2023Outliers and impulsive disturbances often cause heavy-tailed distributions in practical applications, and these will degrade the performance of Gaussian approximation smoothing algorithms. To improve the robustness of the Rauch-Tung-Striebel (RTS) smother against complicated non-Gaussian noises, a new RTS-smoother integrated with the minimum error entropy (MEE) criterion (MEE-RTS) is proposed for linear systems, which is also extended to the state estimation of nonlinear systems by utilizing the Taylor series linearization approach. The mean error behavior, the mean square error behavior, as well as the computational complexity of the MEE-RTS smoother are analyzed. According to simulation results, the proposed smoothers perform better than several robust solutions in terms of steady-state error.
State Estimation of Wireless Sensor Networks in the Presence of Data Packet Drops and Non-Gaussian Noise
Jan 14, 2023



Distributed Kalman filter approaches based on the maximum correntropy criterion have recently demonstrated superior state estimation performance to that of conventional distributed Kalman filters for wireless sensor networks in the presence of non-Gaussian impulsive noise. However, these algorithms currently fail to take account of data packet drops. The present work addresses this issue by proposing a distributed maximum correntropy Kalman filter that accounts for data packet drops (i.e., the DMCKF-DPD algorithm). The effectiveness and feasibility of the algorithm are verified by simulations conducted in a wireless sensor network with intermittent observations due to data packet drops under a non-Gaussian noise environment. Moreover, the computational complexity of the DMCKF-DPD algorithm is demonstrated to be moderate compared with that of a conventional distributed Kalman filter, and we provide a sufficient condition to ensure the convergence of the proposed algorithm.
Robust Ellipse Fitting Based on Maximum Correntropy Criterion With Variable Center
Oct 24, 2022The presence of outliers can significantly degrade the performance of ellipse fitting methods. We develop an ellipse fitting method that is robust to outliers based on the maximum correntropy criterion with variable center (MCC-VC), where a Laplacian kernel is used. For single ellipse fitting, we formulate a non-convex optimization problem to estimate the kernel bandwidth and center and divide it into two subproblems, each estimating one parameter. We design sufficiently accurate convex approximation to each subproblem such that computationally efficient closed-form solutions are obtained. The two subproblems are solved in an alternate manner until convergence is reached. We also investigate coupled ellipses fitting. While there exist multiple ellipses fitting methods that can be used for coupled ellipses fitting, we develop a couple ellipses fitting method by exploiting the special structure. Having unknown association between data points and ellipses, we introduce an association vector for each data point and formulate a non-convex mixed-integer optimization problem to estimate the data associations, which is approximately solved by relaxing it into a second-order cone program. Using the estimated data associations, we extend the proposed method to achieve the final coupled ellipses fitting. The proposed method is shown to have significantly better performance over the existing methods in both simulated data and real images.
Multi-scale Attention Network for Single Image Super-Resolution
Sep 29, 2022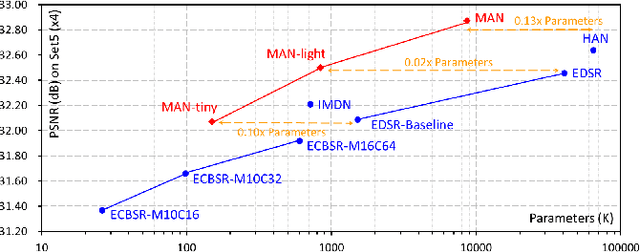
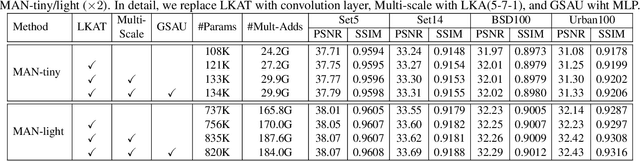

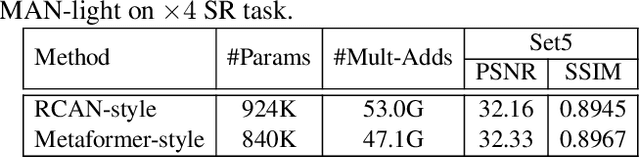
By exploiting large kernel decomposition and attention mechanisms, convolutional neural networks (CNN) can compete with transformer-based methods in many high-level computer vision tasks. However, due to the advantage of long-range modeling, the transformers with self-attention still dominate the low-level vision, including the super-resolution task. In this paper, we propose a CNN-based multi-scale attention network (MAN), which consists of multi-scale large kernel attention (MLKA) and a gated spatial attention unit (GSAU), to improve the performance of convolutional SR networks. Within our MLKA, we rectify LKA with multi-scale and gate schemes to obtain the abundant attention map at various granularity levels, therefore jointly aggregating global and local information and avoiding the potential blocking artifacts. In GSAU, we integrate gate mechanism and spatial attention to remove the unnecessary linear layer and aggregate informative spatial context. To confirm the effectiveness of our designs, we evaluate MAN with multiple complexities by simply stacking different numbers of MLKA and GSAU. Experimental results illustrate that our MAN can achieve varied trade-offs between state-of-the-art performance and computations. Code is available at https://github.com/icandle/MAN.
Acoustic SLAM based on the Direction-of-Arrival and the Direct-to-Reverberant Energy Ratio
Sep 22, 2022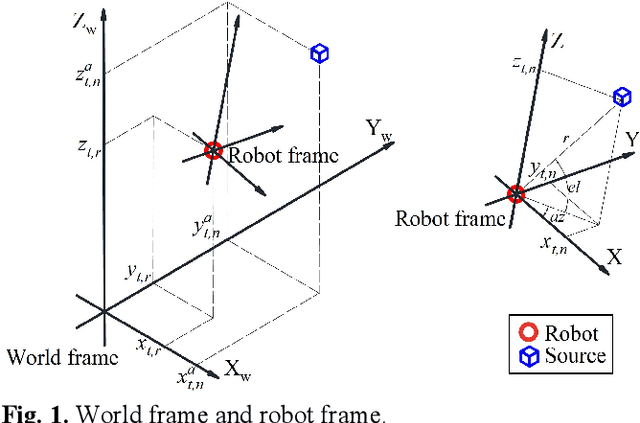
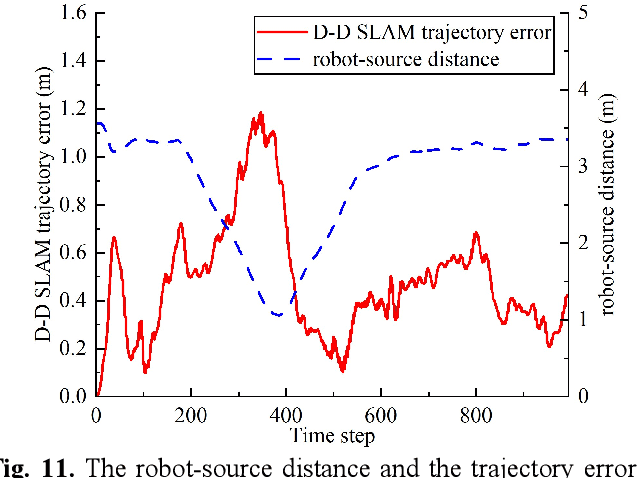
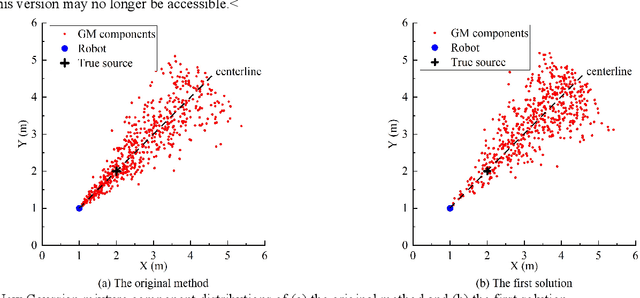
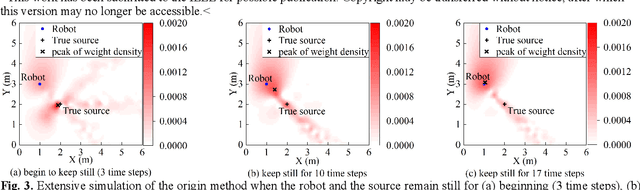
This paper proposes a new method that fuses acoustic measurements in the reverberation field and low-accuracy inertial measurement unit (IMU) motion reports for simultaneous localization and mapping (SLAM). Different from existing studies that only use acoustic data for direction-of-arrival (DoA) estimates, the source's distance from sensors is calculated with the direct-to-reverberant energy ratio (DRR) and applied as a new constraint to eliminate the nonlinear noise from motion reports. A particle filter is applied to estimate the critical distance, which is key for associating the source's distance with the DRR. A keyframe method is used to eliminate the deviation of the source position estimation toward the robot. The proposed DoA-DRR acoustic SLAM (D-D SLAM) is designed for three-dimensional motion and is suitable for most robots. The method is the first acoustic SLAM algorithm that has been validated on a real-world indoor scene dataset that contains only acoustic data and IMU measurements. Compared with previous methods, D-D SLAM has acceptable performance in locating the robot and building a source map from a real-world indoor dataset. The average location accuracy is 0.48 m, while the source position error converges to less than 0.25 m within 2.8 s. These results prove the effectiveness of D-D SLAM in real-world indoor scenes, which may be especially useful in search and rescue missions after disasters where the environment is foggy, i.e., unsuitable for light or laser irradiation.
Deep learning-based Crop Row Following for Infield Navigation of Agri-Robots
Sep 09, 2022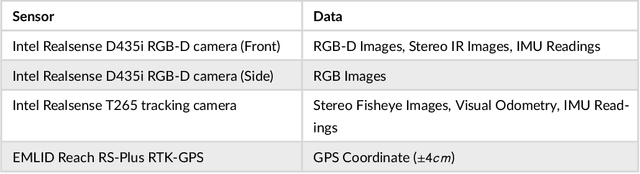
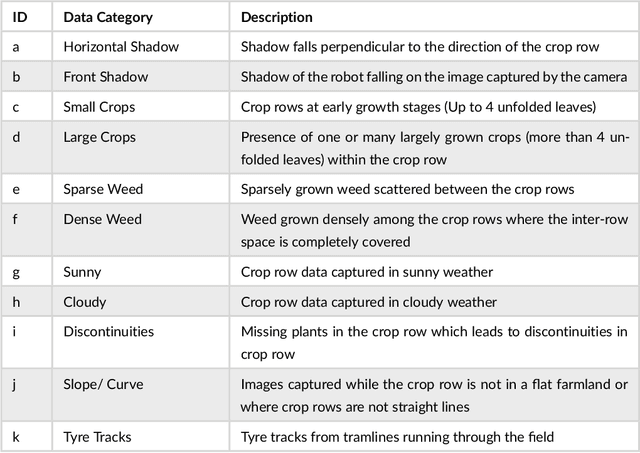
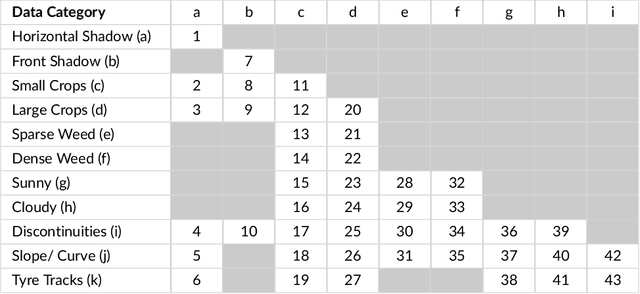
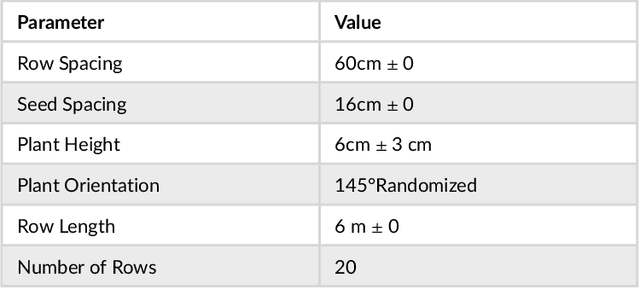
Autonomous navigation in agricultural environments is often challenged by varying field conditions that may arise in arable fields. The state-of-the-art solutions for autonomous navigation in these agricultural environments will require expensive hardware such as RTK-GPS. This paper presents a robust crop row detection algorithm that can withstand those variations while detecting crop rows for visual servoing. A dataset of sugar beet images was created with 43 combinations of 11 field variations found in arable fields. The novel crop row detection algorithm is tested both for the crop row detection performance and also the capability of visual servoing along a crop row. The algorithm only uses RGB images as input and a convolutional neural network was used to predict crop row masks. Our algorithm outperformed the baseline method which uses colour-based segmentation for all the combinations of field variations. We use a combined performance indicator that accounts for the angular and displacement errors of the crop row detection. Our algorithm exhibited the worst performance during the early growth stages of the crop.
Knowledge Distillation via the Target-aware Transformer
May 22, 2022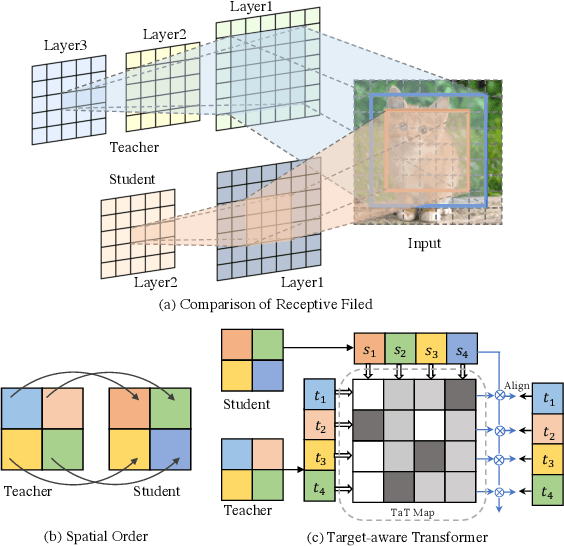
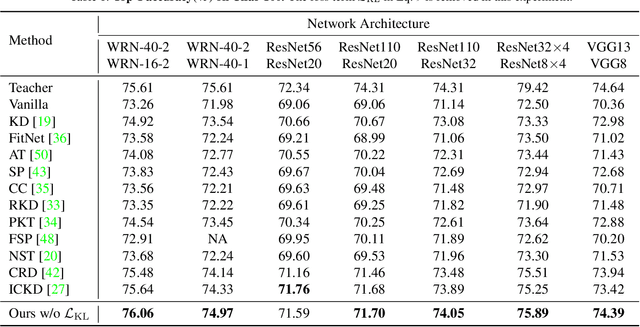
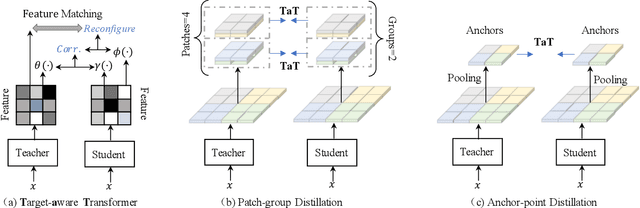

Knowledge distillation becomes a de facto standard to improve the performance of small neural networks. Most of the previous works propose to regress the representational features from the teacher to the student in a one-to-one spatial matching fashion. However, people tend to overlook the fact that, due to the architecture differences, the semantic information on the same spatial location usually vary. This greatly undermines the underlying assumption of the one-to-one distillation approach. To this end, we propose a novel one-to-all spatial matching knowledge distillation approach. Specifically, we allow each pixel of the teacher feature to be distilled to all spatial locations of the student features given its similarity, which is generated from a target-aware transformer. Our approach surpasses the state-of-the-art methods by a significant margin on various computer vision benchmarks, such as ImageNet, Pascal VOC and COCOStuff10k. Code will be released soon.