 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParticle-based Instance-aware Semantic Occupancy Mapping in Dynamic Environments
Sep 18, 2024



Representing the 3D environment with instance-aware semantic and geometric information is crucial for interaction-aware robots in dynamic environments. Nonetheless, creating such a representation poses challenges due to sensor noise, instance segmentation and tracking errors, and the objects' dynamic motion. This paper introduces a novel particle-based instance-aware semantic occupancy map to tackle these challenges. Particles with an augmented instance state are used to estimate the Probability Hypothesis Density (PHD) of the objects and implicitly model the environment. Utilizing a State-augmented Sequential Monte Carlo PHD (S$^2$MC-PHD) filter, these particles are updated to jointly estimate occupancy status, semantic, and instance IDs, mitigating noise. Additionally, a memory module is adopted to enhance the map's responsiveness to previously observed objects. Experimental results on the Virtual KITTI 2 dataset demonstrate that the proposed approach surpasses state-of-the-art methods across multiple metrics under different noise conditions. Subsequent tests using real-world data further validate the effectiveness of the proposed approach.
FreqINR: Frequency Consistency for Implicit Neural Representation with Adaptive DCT Frequency Loss
Aug 25, 2024



Recent advancements in local Implicit Neural Representation (INR) demonstrate its exceptional capability in handling images at various resolutions. However, frequency discrepancies between high-resolution (HR) and ground-truth images, especially at larger scales, result in significant artifacts and blurring in HR images. This paper introduces Frequency Consistency for Implicit Neural Representation (FreqINR), an innovative Arbitrary-scale Super-resolution method aimed at enhancing detailed textures by ensuring spectral consistency throughout both training and inference. During training, we employ Adaptive Discrete Cosine Transform Frequency Loss (ADFL) to minimize the frequency gap between HR and ground-truth images, utilizing 2-Dimensional DCT bases and focusing dynamically on challenging frequencies. During inference, we extend the receptive field to preserve spectral coherence between low-resolution (LR) and ground-truth images, which is crucial for the model to generate high-frequency details from LR counterparts. Experimental results show that FreqINR, as a lightweight approach, achieves state-of-the-art performance compared to existing Arbitrary-scale Super-resolution methods and offers notable improvements in computational efficiency. The code for our method will be made publicly available.
NeurDB: On the Design and Implementation of an AI-powered Autonomous Database
Aug 06, 2024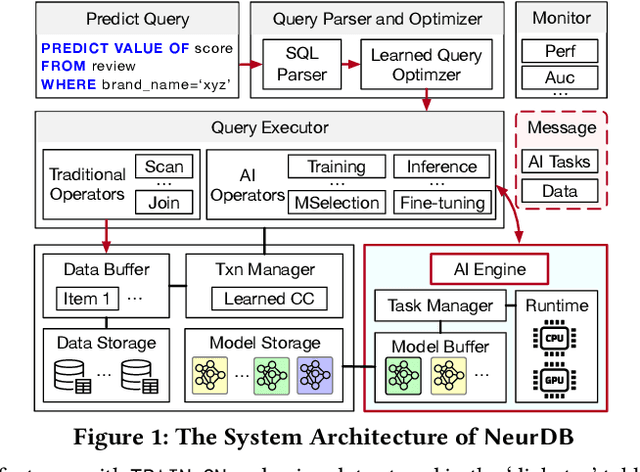
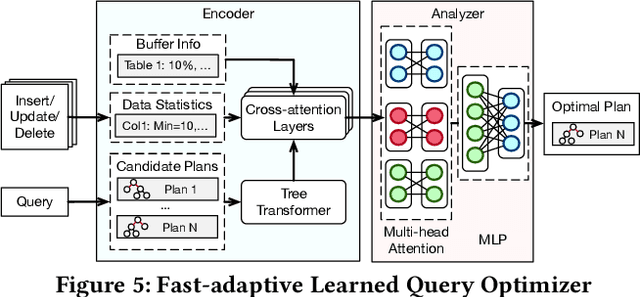
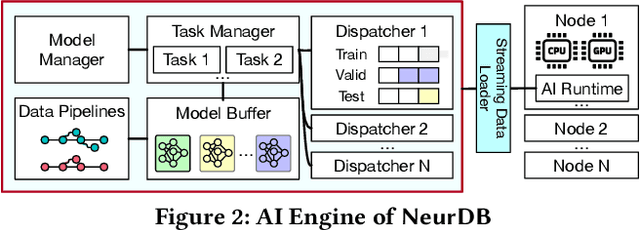
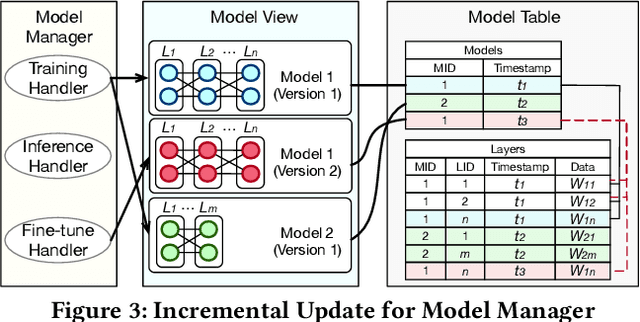
Databases are increasingly embracing AI to provide autonomous system optimization and intelligent in-database analytics, aiming to relieve end-user burdens across various industry sectors. Nonetheless, most existing approaches fail to account for the dynamic nature of databases, which renders them ineffective for real-world applications characterized by evolving data and workloads. This paper introduces NeurDB, an AI-powered autonomous database that deepens the fusion of AI and databases with adaptability to data and workload drift. NeurDB establishes a new in-database AI ecosystem that seamlessly integrates AI workflows within the database. This integration enables efficient and effective in-database AI analytics and fast-adaptive learned system components. Empirical evaluations demonstrate that NeurDB substantially outperforms existing solutions in managing AI analytics tasks, with the proposed learned components more effectively handling environmental dynamism than state-of-the-art approaches.
VecAug: Unveiling Camouflaged Frauds with Cohort Augmentation for Enhanced Detection
Aug 01, 2024



Fraud detection presents a challenging task characterized by ever-evolving fraud patterns and scarce labeled data. Existing methods predominantly rely on graph-based or sequence-based approaches. While graph-based approaches connect users through shared entities to capture structural information, they remain vulnerable to fraudsters who can disrupt or manipulate these connections. In contrast, sequence-based approaches analyze users' behavioral patterns, offering robustness against tampering but overlooking the interactions between similar users. Inspired by cohort analysis in retention and healthcare, this paper introduces VecAug, a novel cohort-augmented learning framework that addresses these challenges by enhancing the representation learning of target users with personalized cohort information. To this end, we first propose a vector burn-in technique for automatic cohort identification, which retrieves a task-specific cohort for each target user. Then, to fully exploit the cohort information, we introduce an attentive cohort aggregation technique for augmenting target user representations. To improve the robustness of such cohort augmentation, we also propose a novel label-aware cohort neighbor separation mechanism to distance negative cohort neighbors and calibrate the aggregated cohort information. By integrating this cohort information with target user representations, VecAug enhances the modeling capacity and generalization capabilities of the model to be augmented. Our framework is flexible and can be seamlessly integrated with existing fraud detection models. We deploy our framework on e-commerce platforms and evaluate it on three fraud detection datasets, and results show that VecAug improves the detection performance of base models by up to 2.48\% in AUC and 22.5\% in R@P$_{0.9}$, outperforming state-of-the-art methods significantly.
Tabular Data Augmentation for Machine Learning: Progress and Prospects of Embracing Generative AI
Jul 31, 2024



Machine learning (ML) on tabular data is ubiquitous, yet obtaining abundant high-quality tabular data for model training remains a significant obstacle. Numerous works have focused on tabular data augmentation (TDA) to enhance the original table with additional data, thereby improving downstream ML tasks. Recently, there has been a growing interest in leveraging the capabilities of generative AI for TDA. Therefore, we believe it is time to provide a comprehensive review of the progress and future prospects of TDA, with a particular emphasis on the trending generative AI. Specifically, we present an architectural view of the TDA pipeline, comprising three main procedures: pre-augmentation, augmentation, and post-augmentation. Pre-augmentation encompasses preparation tasks that facilitate subsequent TDA, including error handling, table annotation, table simplification, table representation, table indexing, table navigation, schema matching, and entity matching. Augmentation systematically analyzes current TDA methods, categorized into retrieval-based methods, which retrieve external data, and generation-based methods, which generate synthetic data. We further subdivide these methods based on the granularity of the augmentation process at the row, column, cell, and table levels. Post-augmentation focuses on the datasets, evaluation and optimization aspects of TDA. We also summarize current trends and future directions for TDA, highlighting promising opportunities in the era of generative AI. In addition, the accompanying papers and related resources are continuously updated and maintained in the GitHub repository at https://github.com/SuDIS-ZJU/awesome-tabular-data-augmentation to reflect ongoing advancements in the field.
Static and multivariate-temporal attentive fusion transformer for readmission risk prediction
Jul 15, 2024



Background: Accurate short-term readmission prediction of ICU patients is significant in improving the efficiency of resource assignment by assisting physicians in making discharge decisions. Clinically, both individual static static and multivariate temporal data collected from ICU monitors play critical roles in short-term readmission prediction. Informative static and multivariate temporal feature representation capturing and fusion present challenges for accurate readmission prediction. Methods:We propose a novel static and multivariate-temporal attentive fusion transformer (SMTAFormer) to predict short-term readmission of ICU patients by fully leveraging the potential of demographic and dynamic temporal data. In SMTAFormer, we first apply an MLP network and a temporal transformer network to learn useful static and temporal feature representations, respectively. Then, the well-designed static and multivariate temporal feature fusion module is applied to fuse static and temporal feature representations by modeling intra-correlation among multivariate temporal features and constructing inter-correlation between static and multivariate temporal features. Results: We construct a readmission risk assessment (RRA) dataset based on the MIMIC-III dataset. The extensive experiments show that SMTAFormer outperforms advanced methods, in which the accuracy of our proposed method is up to 86.6%, and the area under the receiver operating characteristic curve (AUC) is up to 0.717. Conclusion: Our proposed SMTAFormer can efficiently capture and fuse static and multivariate temporal feature representations. The results show that SMTAFormer significantly improves the short-term readmission prediction performance of ICU patients through comparisons to strong baselines.
On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey
Jun 14, 2024



Within the evolving landscape of deep learning, the dilemma of data quantity and quality has been a long-standing problem. The recent advent of Large Language Models (LLMs) offers a data-centric solution to alleviate the limitations of real-world data with synthetic data generation. However, current investigations into this field lack a unified framework and mostly stay on the surface. Therefore, this paper provides an organization of relevant studies based on a generic workflow of synthetic data generation. By doing so, we highlight the gaps within existing research and outline prospective avenues for future study. This work aims to shepherd the academic and industrial communities towards deeper, more methodical inquiries into the capabilities and applications of LLMs-driven synthetic data generation.
Optimizing Large Model Training through Overlapped Activation Recomputation
Jun 13, 2024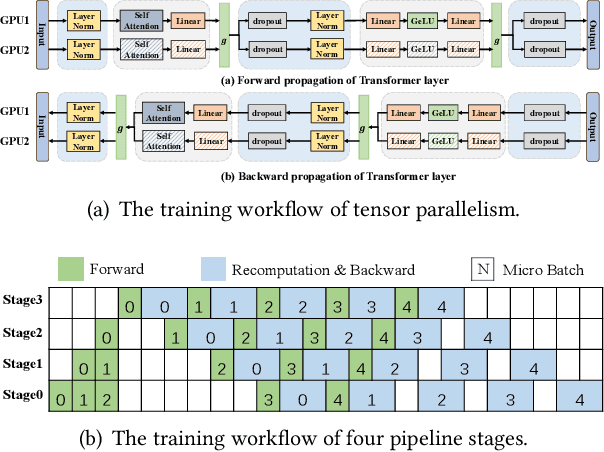
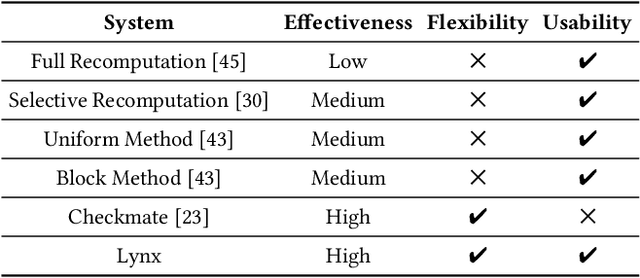
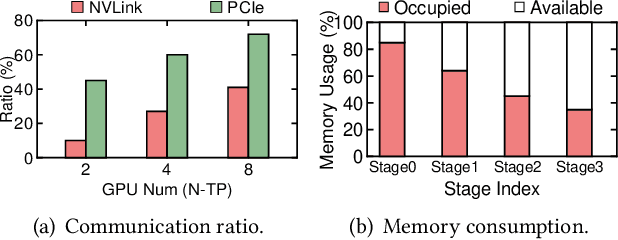
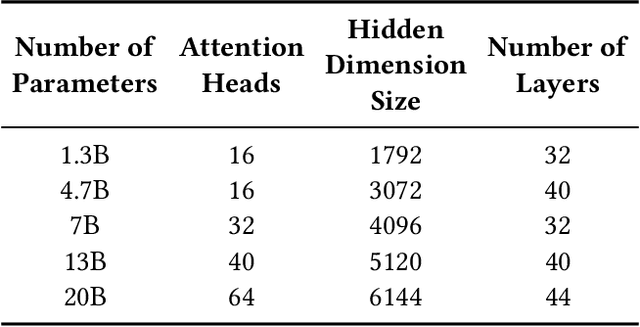
Large model training has been using recomputation to alleviate the memory pressure and pipelining to exploit the parallelism of data, tensor, and devices. The existing recomputation approaches may incur up to 40% overhead when training real-world models, e.g., the GPT model with 22B parameters. This is because they are executed on demand in the critical training path. In this paper, we design a new recomputation framework, Lynx, to reduce the overhead by overlapping the recomputation with communication occurring in training pipelines. It consists of an optimal scheduling algorithm (OPT) and a heuristic-based scheduling algorithm (HEU). OPT achieves a global optimum but suffers from a long search time. HEU was designed based on our observation that there are identical structures in large DNN models so that we can apply the same scheduling policy to all identical structures. HEU achieves a local optimum but reduces the search time by 99% compared to OPT. Our comprehensive evaluation using GPT models with 1.3B-20B parameters shows that both OPT and HEU outperform the state-of-the-art recomputation approaches (e.g., Megatron-LM and Checkmake) by 1.02-1.53x. HEU achieves a similar performance as OPT with a search time of 0.16s on average.
ADBA:Approximation Decision Boundary Approach for Black-Box Adversarial Attacks
Jun 07, 2024



Many machine learning models are susceptible to adversarial attacks, with decision-based black-box attacks representing the most critical threat in real-world applications. These attacks are extremely stealthy, generating adversarial examples using hard labels obtained from the target machine learning model. This is typically realized by optimizing perturbation directions, guided by decision boundaries identified through query-intensive exact search, significantly limiting the attack success rate. This paper introduces a novel approach using the Approximation Decision Boundary (ADB) to efficiently and accurately compare perturbation directions without precisely determining decision boundaries. The effectiveness of our ADB approach (ADBA) hinges on promptly identifying suitable ADB, ensuring reliable differentiation of all perturbation directions. For this purpose, we analyze the probability distribution of decision boundaries, confirming that using the distribution's median value as ADB can effectively distinguish different perturbation directions, giving rise to the development of the ADBA-md algorithm. ADBA-md only requires four queries on average to differentiate any pair of perturbation directions, which is highly query-efficient. Extensive experiments on six well-known image classifiers clearly demonstrate the superiority of ADBA and ADBA-md over multiple state-of-the-art black-box attacks.
Cognitive Manipulation: Semi-supervised Visual Representation and Classroom-to-real Reinforcement Learning for Assembly in Semi-structured Environments
Jun 01, 2024Assembling a slave object into a fixture-free master object represents a critical challenge in flexible manufacturing. Existing deep reinforcement learning-based methods, while benefiting from visual or operational priors, often struggle with small-batch precise assembly tasks due to their reliance on insufficient priors and high-costed model development. To address these limitations, this paper introduces a cognitive manipulation and learning approach that utilizes skill graphs to integrate learning-based object detection with fine manipulation models into a cohesive modular policy. This approach enables the detection of the master object from both global and local perspectives to accommodate positional uncertainties and variable backgrounds, and parametric residual policy to handle pose error and intricate contact dynamics effectively. Leveraging the skill graph, our method supports knowledge-informed learning of semi-supervised learning for object detection and classroom-to-real reinforcement learning for fine manipulation. Simulation experiments on a gear-assembly task have demonstrated that the skill-graph-enabled coarse-operation planning and visual attention are essential for efficient learning and robust manipulation, showing substantial improvements of 13$\%$ in success rate and 15.4$\%$ in number of completion steps over competing methods. Real-world experiments further validate that our system is highly effective for robotic assembly in semi-structured environments.