 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT-JAM: Boosting BERT-Enhanced Neural Machine Translation with Joint Attention
Paper and Code
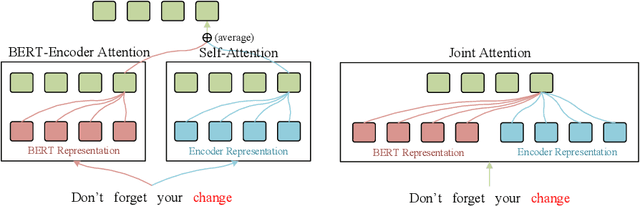
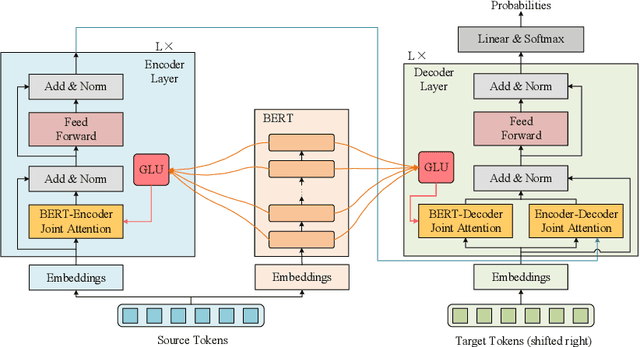

BERT-enhanced neural machine translation (NMT) aims at leveraging BERT-encoded representations for translation tasks. A recently proposed approach uses attention mechanisms to fuse Transformer's encoder and decoder layers with BERT's last-layer representation and shows enhanced performance. However, their method doesn't allow for the flexible distribution of attention between the BERT representation and the encoder/decoder representation. In this work, we propose a novel BERT-enhanced NMT model called BERT-JAM which improves upon existing models from two aspects: 1) BERT-JAM uses joint-attention modules to allow the encoder/decoder layers to dynamically allocate attention between different representations, and 2) BERT-JAM allows the encoder/decoder layers to make use of BERT's intermediate representations by composing them using a gated linear unit (GLU). We train BERT-JAM with a novel three-phase optimization strategy that progressively unfreezes different components of BERT-JAM. Our experiments show that BERT-JAM achieves SOTA BLEU scores on multiple translation tasks.