 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeslimIPL: Language-Model-Free Iterative Pseudo-Labeling
Oct 22, 2020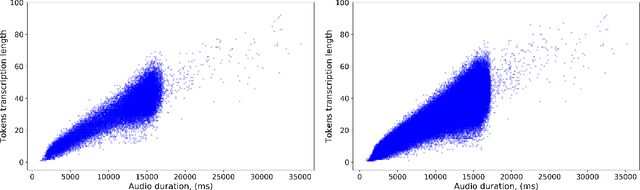
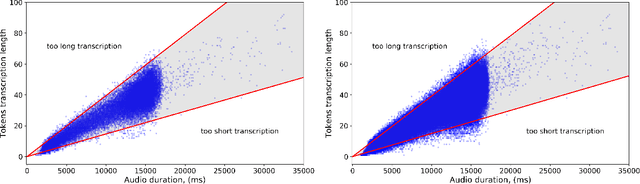

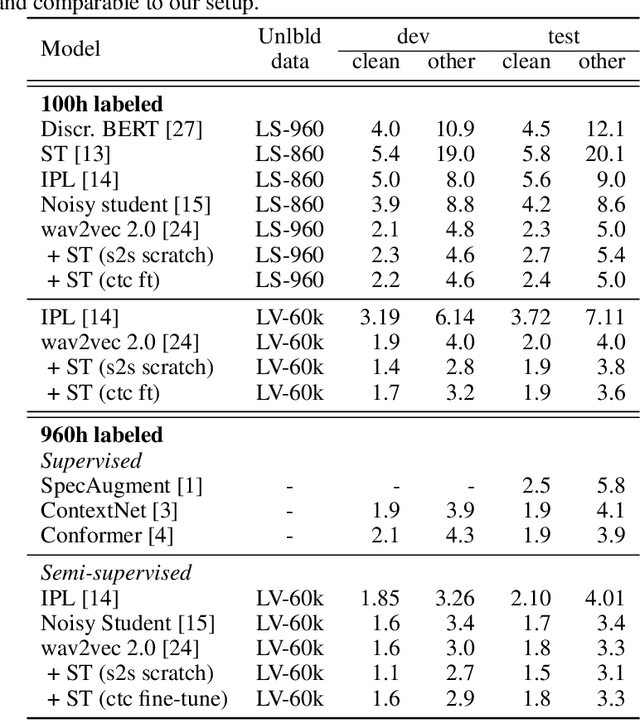
Recent results in end-to-end ASR have demonstrated the efficacy of simple pseudo-labeling for semi-supervised models trained both with Connectionist Temporal Classification (CTC) and Sequence-to-Sequence (seq2seq) losses. Iterative Pseudo-Labeling (IPL), which continuously trains a single model using pseudo-labels iteratively re-generated as the model learns, has been shown to further increase performance in ASR. We improve upon the IPL algorithm: as the model learns, we propose to iteratively re-generate transcriptions with hard labels (the most probable tokens) assignments, that is without a language model. We call this approach Language-Model-Free IPL (slimIPL) and we give a resultant training setup for CTC and seq2seq models. At inference, our experiments show that decoding with a strong language model is more beneficial with slimIPL than IPL, asIPL exhibits some language model over-fitting issues. Compared to prior work on semi-supervised and unsupervised approaches, slimIPL not only simplifies the training process, but also achieves competitive and state-of-the-art results on LibriSpeech test sets in both standard and low-resource settings.
Self-training and Pre-training are Complementary for Speech Recognition
Oct 22, 2020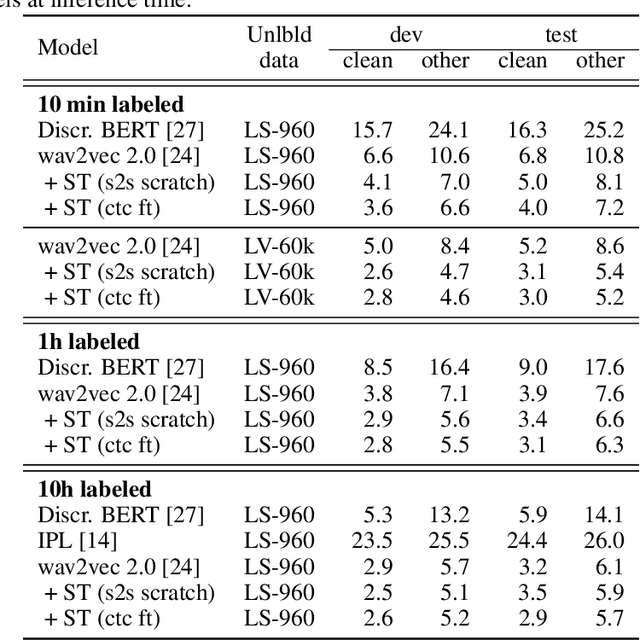
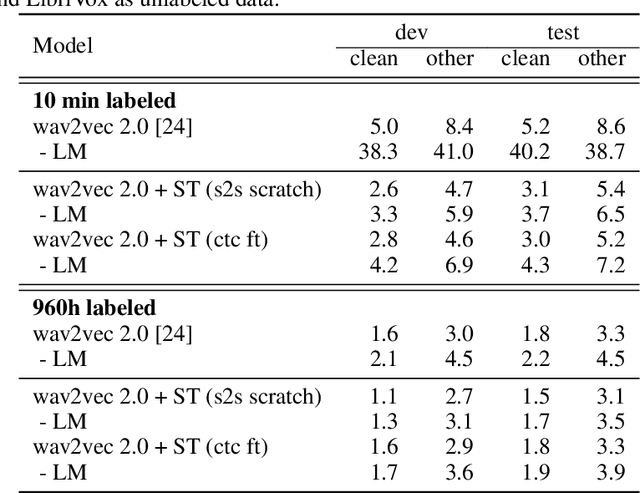
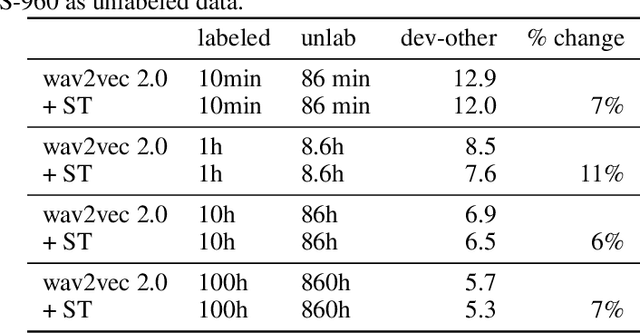
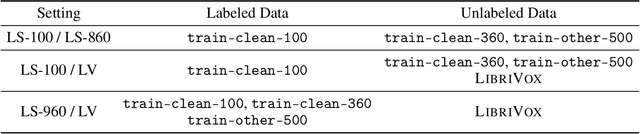
Self-training and unsupervised pre-training have emerged as effective approaches to improve speech recognition systems using unlabeled data. However, it is not clear whether they learn similar patterns or if they can be effectively combined. In this paper, we show that pseudo-labeling and pre-training with wav2vec 2.0 are complementary in a variety of labeled data setups. Using just 10 minutes of labeled data from Libri-light as well as 53k hours of unlabeled data from LibriVox achieves WERs of 3.0%/5.2% on the clean and other test sets of Librispeech - rivaling the best published systems trained on 960 hours of labeled data only a year ago. Training on all labeled data of Librispeech achieves WERs of 1.5%/3.1%.
Population Based Training for Data Augmentation and Regularization in Speech Recognition
Oct 08, 2020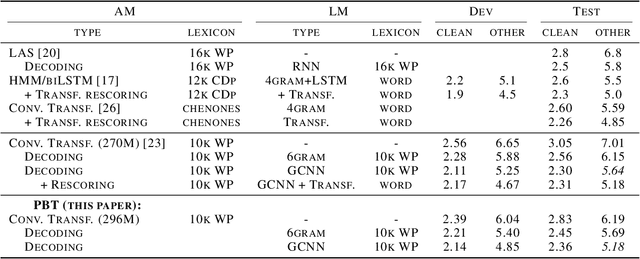
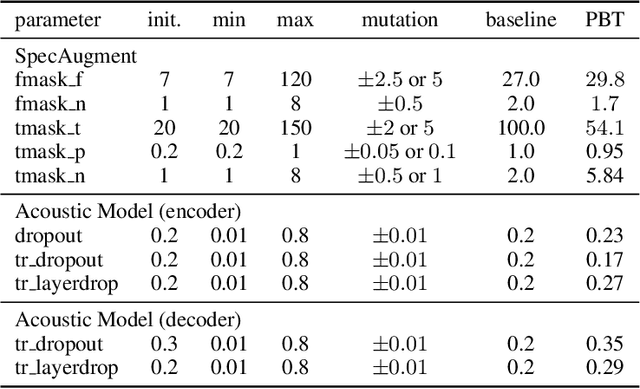
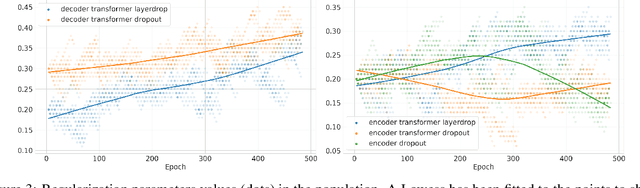
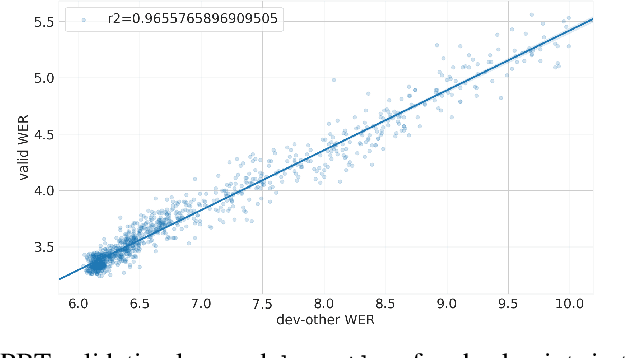
Varying data augmentation policies and regularization over the course of optimization has led to performance improvements over using fixed values. We show that population based training is a useful tool to continuously search those hyperparameters, within a fixed budget. This greatly simplifies the experimental burden and computational cost of finding such optimal schedules. We experiment in speech recognition by optimizing SpecAugment this way, as well as dropout. It compares favorably to a baseline that does not change those hyperparameters over the course of training, with an 8% relative WER improvement. We obtain 5.18% word error rate on LibriSpeech's test-other.
Massively Multilingual ASR: 50 Languages, 1 Model, 1 Billion Parameters
Jul 08, 2020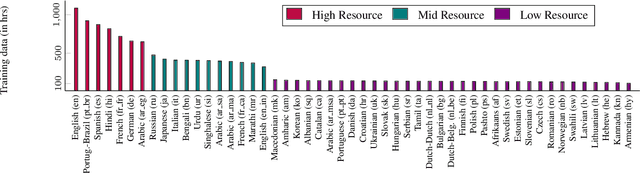
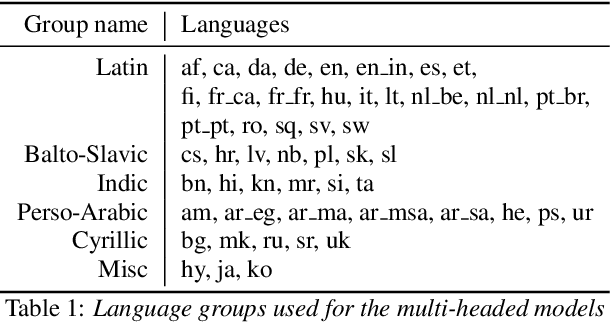
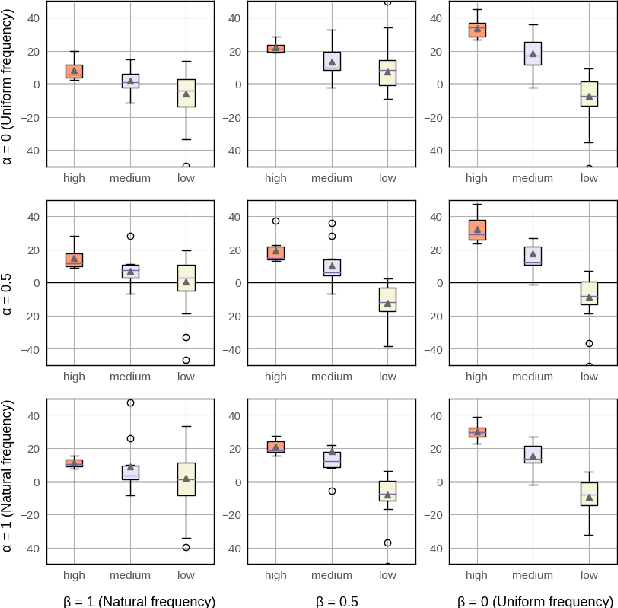
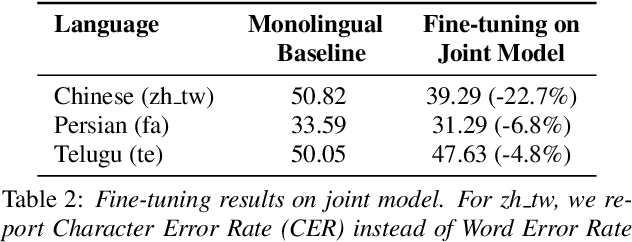
We study training a single acoustic model for multiple languages with the aim of improving automatic speech recognition (ASR) performance on low-resource languages, and over-all simplifying deployment of ASR systems that support diverse languages. We perform an extensive benchmark on 51 languages, with varying amount of training data by language(from 100 hours to 1100 hours). We compare three variants of multilingual training from a single joint model without knowing the input language, to using this information, to multiple heads (one per language cluster). We show that multilingual training of ASR models on several languages can improve recognition performance, in particular, on low resource languages. We see 20.9%, 23% and 28.8% average WER relative reduction compared to monolingual baselines on joint model, joint model with language input and multi head model respectively. To our knowledge, this is the first work studying multilingual ASR at massive scale, with more than 50 languages and more than 16,000 hours of audio across them.
Data Augmenting Contrastive Learning of Speech Representations in the Time Domain
Jul 02, 2020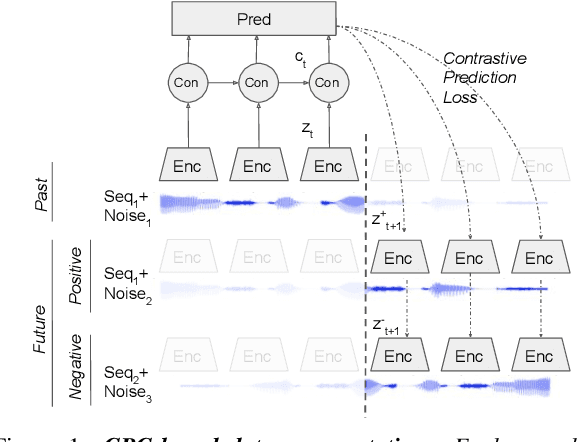
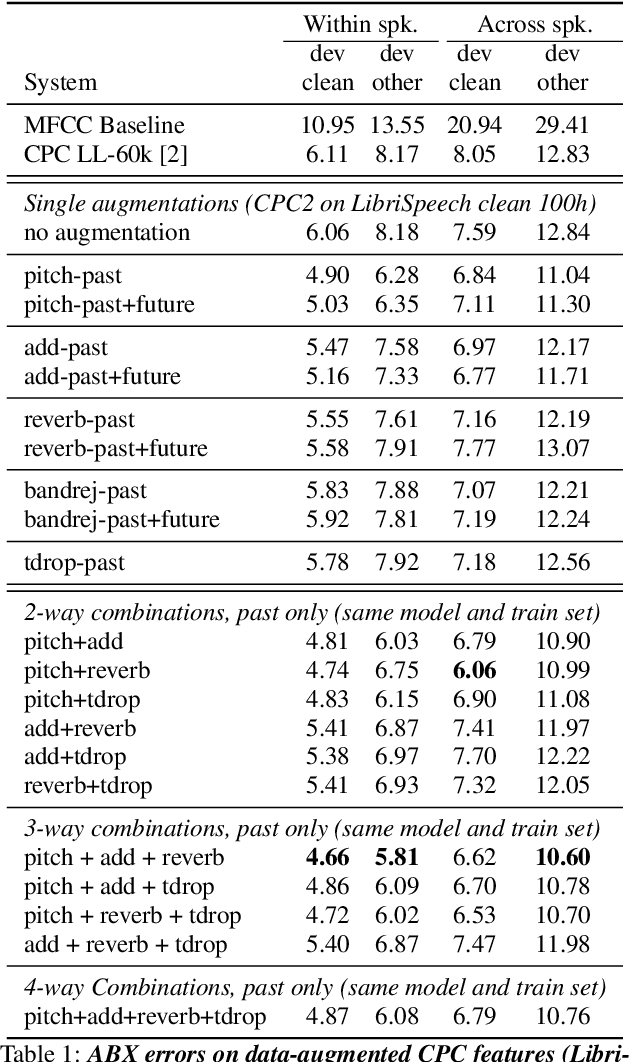
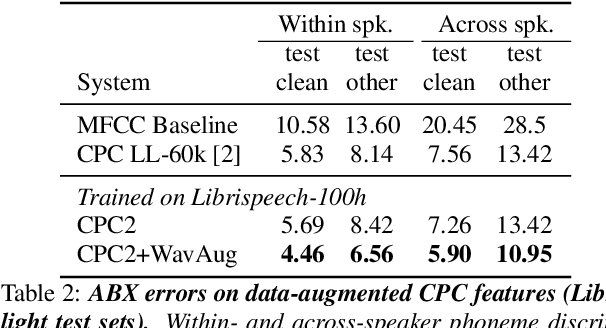
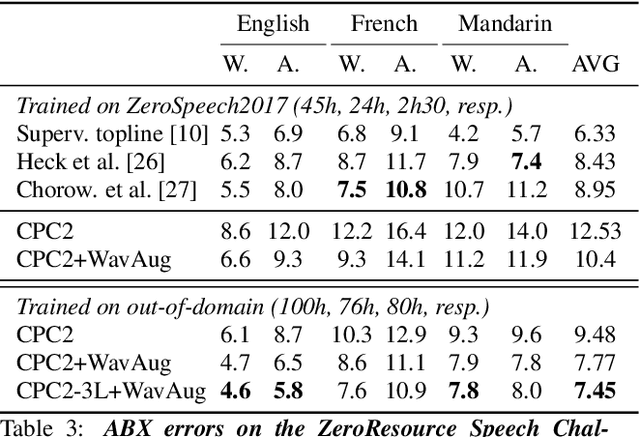
Contrastive Predictive Coding (CPC), based on predicting future segments of speech based on past segments is emerging as a powerful algorithm for representation learning of speech signal. However, it still under-performs other methods on unsupervised evaluation benchmarks. Here, we introduce WavAugment, a time-domain data augmentation library and find that applying augmentation in the past is generally more efficient and yields better performances than other methods. We find that a combination of pitch modification, additive noise and reverberation substantially increase the performance of CPC (relative improvement of 18-22%), beating the reference Libri-light results with 600 times less data. Using an out-of-domain dataset, time-domain data augmentation can push CPC to be on par with the state of the art on the Zero Speech Benchmark 2017. We also show that time-domain data augmentation consistently improves downstream limited-supervision phoneme classification tasks by a factor of 12-15% relative.
Real Time Speech Enhancement in the Waveform Domain
Jun 23, 2020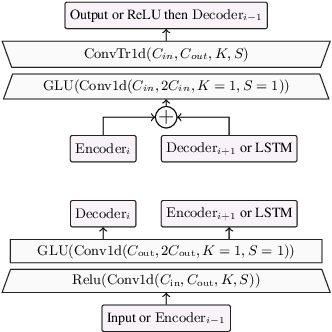
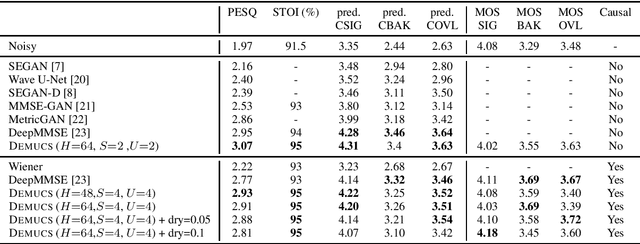
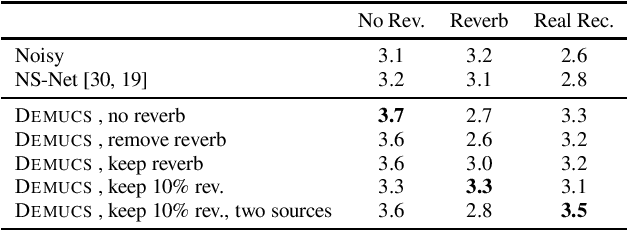

We present a causal speech enhancement model working on the raw waveform that runs in real-time on a laptop CPU. The proposed model is based on an encoder-decoder architecture with skip-connections. It is optimized on both time and frequency domains, using multiple loss functions. Empirical evidence shows that it is capable of removing various kinds of background noise including stationary and non-stationary noises, as well as room reverb. Additionally, we suggest a set of data augmentation techniques applied directly on the raw waveform which further improve model performance and its generalization abilities. We perform evaluations on several standard benchmarks, both using objective metrics and human judgements. The proposed model matches state-of-the-art performance of both causal and non causal methods while working directly on the raw waveform.
End-to-End Object Detection with Transformers
May 28, 2020
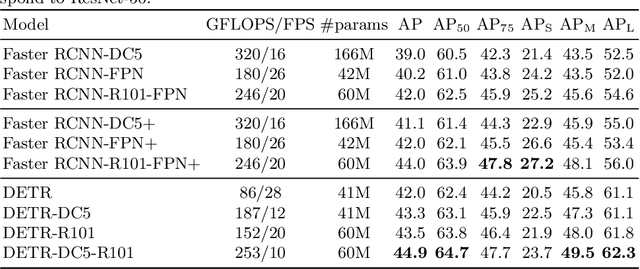
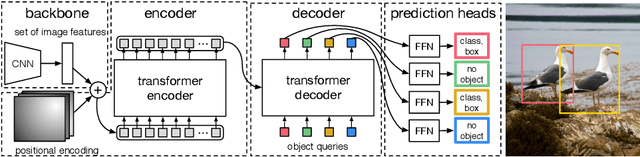
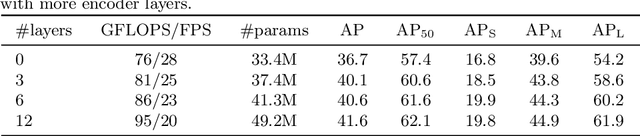
We present a new method that views object detection as a direct set prediction problem. Our approach streamlines the detection pipeline, effectively removing the need for many hand-designed components like a non-maximum suppression procedure or anchor generation that explicitly encode our prior knowledge about the task. The main ingredients of the new framework, called DEtection TRansformer or DETR, are a set-based global loss that forces unique predictions via bipartite matching, and a transformer encoder-decoder architecture. Given a fixed small set of learned object queries, DETR reasons about the relations of the objects and the global image context to directly output the final set of predictions in parallel. The new model is conceptually simple and does not require a specialized library, unlike many other modern detectors. DETR demonstrates accuracy and run-time performance on par with the well-established and highly-optimized Faster RCNN baseline on the challenging COCO object detection dataset. Moreover, DETR can be easily generalized to produce panoptic segmentation in a unified manner. We show that it significantly outperforms competitive baselines. Training code and pretrained models are available at https://github.com/facebookresearch/detr.
Iterative Pseudo-Labeling for Speech Recognition
May 19, 2020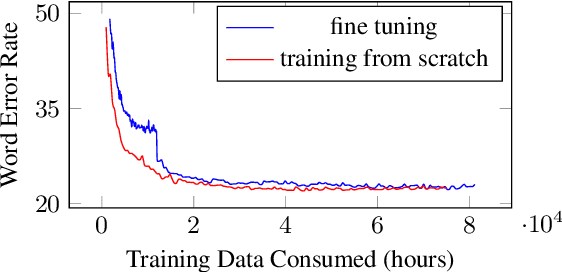
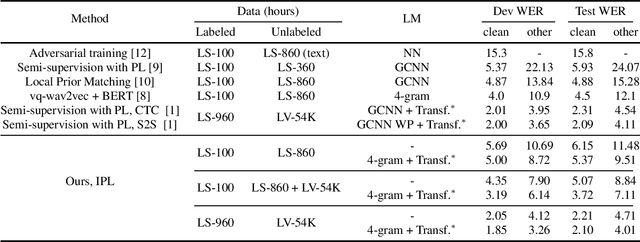
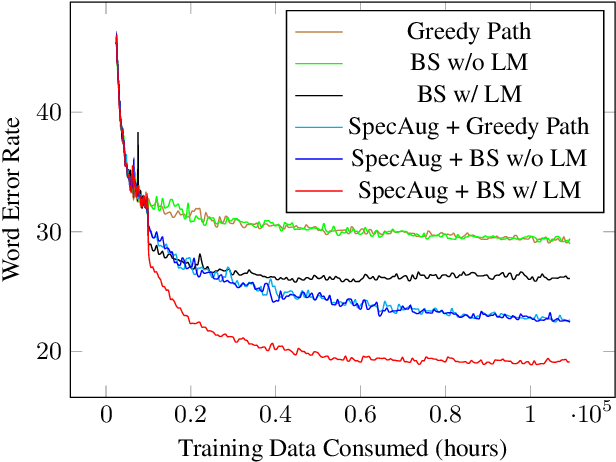

Pseudo-labeling has recently shown promise in end-to-end automatic speech recognition (ASR). We study Iterative Pseudo-Labeling (IPL), a semi-supervised algorithm which efficiently performs multiple iterations of pseudo-labeling on unlabeled data as the acoustic model evolves. In particular, IPL fine-tunes an existing model at each iteration using both labeled data and a subset of unlabeled data. We study the main components of IPL: decoding with a language model and data augmentation. We then demonstrate the effectiveness of IPL by achieving state-of-the-art word-error rate on the Librispeech test sets in both standard and low-resource setting. We also study the effect of language models trained on different corpora to show IPL can effectively utilize additional text. Finally, we release a new large in-domain text corpus which does not overlap with the Librispeech training transcriptions to foster research in low-resource, semi-supervised ASR
Contextualizing ASR Lattice Rescoring with Hybrid Pointer Network Language Model
May 15, 2020
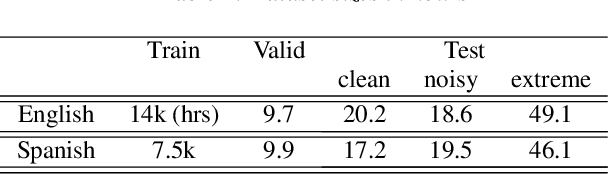
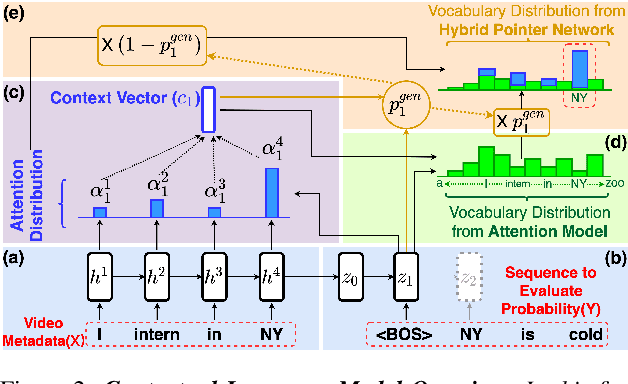
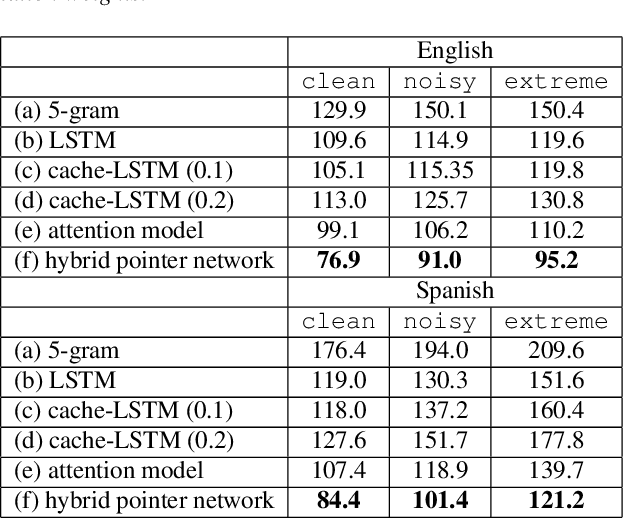
Videos uploaded on social media are often accompanied with textual descriptions. In building automatic speech recognition (ASR) systems for videos, we can exploit the contextual information provided by such video metadata. In this paper, we explore ASR lattice rescoring by selectively attending to the video descriptions. We first use an attention based method to extract contextual vector representations of video metadata, and use these representations as part of the inputs to a neural language model during lattice rescoring. Secondly, we propose a hybrid pointer network approach to explicitly interpolate the word probabilities of the word occurrences in metadata. We perform experimental evaluations on both language modeling and ASR tasks, and demonstrate that both proposed methods provide performance improvements by selectively leveraging the video metadata.
Semi-Supervised Speech Recognition via Local Prior Matching
Feb 24, 2020
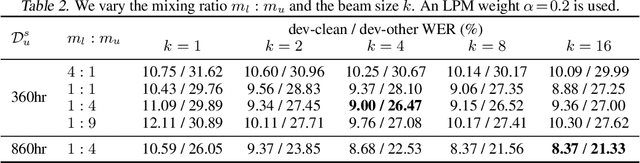
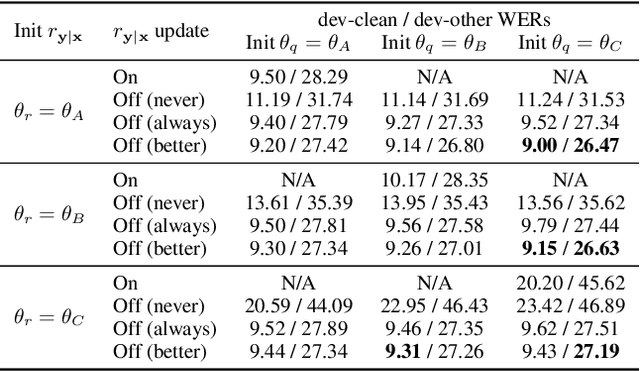
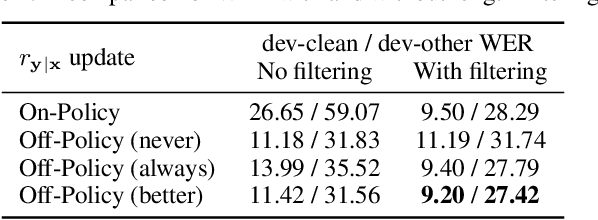
For sequence transduction tasks like speech recognition, a strong structured prior model encodes rich information about the target space, implicitly ruling out invalid sequences by assigning them low probability. In this work, we propose local prior matching (LPM), a semi-supervised objective that distills knowledge from a strong prior (e.g. a language model) to provide learning signal to a discriminative model trained on unlabeled speech. We demonstrate that LPM is theoretically well-motivated, simple to implement, and superior to existing knowledge distillation techniques under comparable settings. Starting from a baseline trained on 100 hours of labeled speech, with an additional 360 hours of unlabeled data, LPM recovers 54% and 73% of the word error rate on clean and noisy test sets relative to a fully supervised model on the same data.